 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel open-source ultrasound dataset with deep learning benchmarks for spinal cord injury localization and anatomical segmentation
Sep 24, 2024



While deep learning has catalyzed breakthroughs across numerous domains, its broader adoption in clinical settings is inhibited by the costly and time-intensive nature of data acquisition and annotation. To further facilitate medical machine learning, we present an ultrasound dataset of 10,223 Brightness-mode (B-mode) images consisting of sagittal slices of porcine spinal cords (N=25) before and after a contusion injury. We additionally benchmark the performance metrics of several state-of-the-art object detection algorithms to localize the site of injury and semantic segmentation models to label the anatomy for comparison and creation of task-specific architectures. Finally, we evaluate the zero-shot generalization capabilities of the segmentation models on human ultrasound spinal cord images to determine whether training on our porcine dataset is sufficient for accurately interpreting human data. Our results show that the YOLOv8 detection model outperforms all evaluated models for injury localization, achieving a mean Average Precision (mAP50-95) score of 0.606. Segmentation metrics indicate that the DeepLabv3 segmentation model achieves the highest accuracy on unseen porcine anatomy, with a Mean Dice score of 0.587, while SAMed achieves the highest Mean Dice score generalizing to human anatomy (0.445). To the best of our knowledge, this is the largest annotated dataset of spinal cord ultrasound images made publicly available to researchers and medical professionals, as well as the first public report of object detection and segmentation architectures to assess anatomical markers in the spinal cord for methodology development and clinical applications.
Two-Stage Stance Labeling: User-Hashtag Heuristics with Graph Neural Networks
Apr 16, 2024The high volume and rapid evolution of content on social media present major challenges for studying the stance of social media users. In this work, we develop a two stage stance labeling method that utilizes the user-hashtag bipartite graph and the user-user interaction graph. In the first stage, a simple and efficient heuristic for stance labeling uses the user-hashtag bipartite graph to iteratively update the stance association of user and hashtag nodes via a label propagation mechanism. This set of soft labels is then integrated with the user-user interaction graph to train a graph neural network (GNN) model using semi-supervised learning. We evaluate this method on two large-scale datasets containing tweets related to climate change from June 2021 to June 2022 and gun control from January 2022 to January 2023. Experiments demonstrate that our user-hashtag heuristic and the semi-supervised GNN method outperform zero-shot stance labeling using LLMs such as GPT4. Further analysis illustrates how the stance labeling information and interaction graph can be used for evaluating the polarization of social media interactions on divisive issues such as climate change and gun control.
Flurry: a Fast Framework for Reproducible Multi-layered Provenance Graph Representation Learning
Mar 05, 2022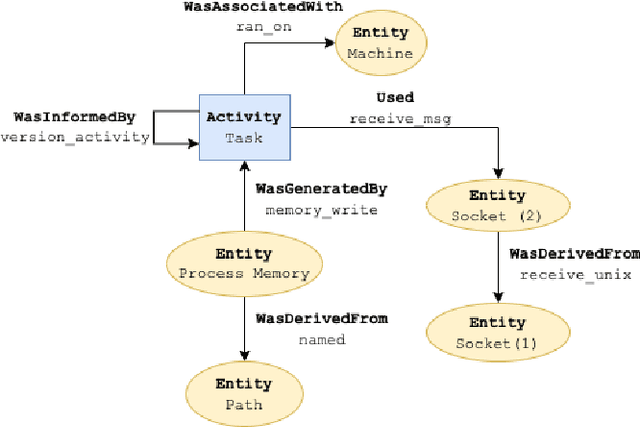
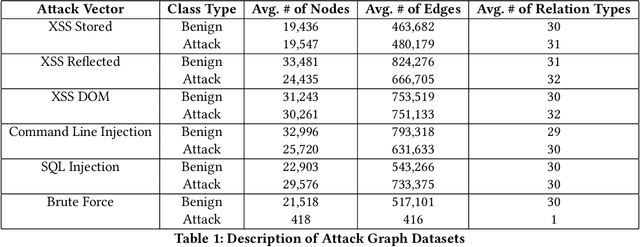
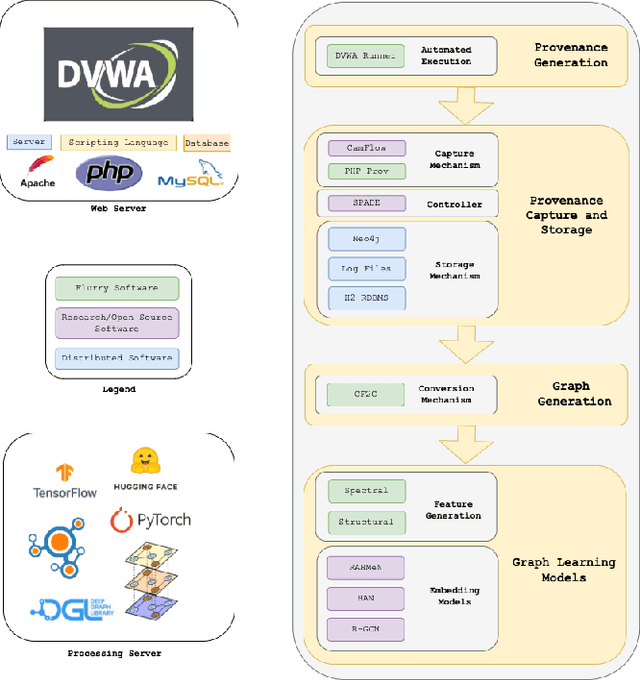

Complex heterogeneous dynamic networks like knowledge graphs are powerful constructs that can be used in modeling data provenance from computer systems. From a security perspective, these attributed graphs enable causality analysis and tracing for analyzing a myriad of cyberattacks. However, there is a paucity in systematic development of pipelines that transform system executions and provenance into usable graph representations for machine learning tasks. This lack of instrumentation severely inhibits scientific advancement in provenance graph machine learning by hindering reproducibility and limiting the availability of data that are critical for techniques like graph neural networks. To fulfill this need, we present Flurry, an end-to-end data pipeline which simulates cyberattacks, captures provenance data from these attacks at multiple system and application layers, converts audit logs from these attacks into data provenance graphs, and incorporates this data with a framework for training deep neural models that supports preconfigured or custom-designed models for analysis in real-world resilient systems. We showcase this pipeline by processing data from multiple system attacks and performing anomaly detection via graph classification using current benchmark graph representational learning frameworks. Flurry provides a fast, customizable, extensible, and transparent solution for providing this much needed data to cybersecurity professionals.
Pay Attention to Relations: Multi-embeddings for Attributed Multiplex Networks
Mar 03, 2022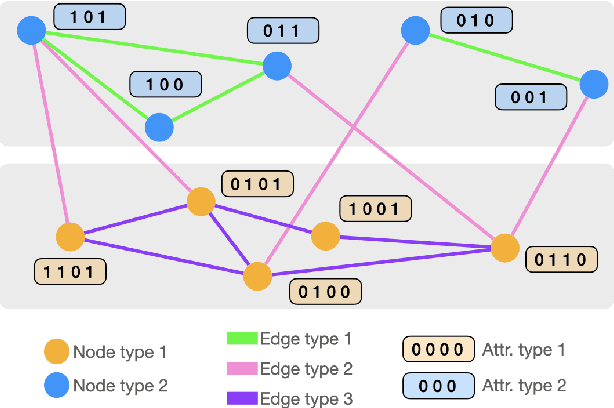
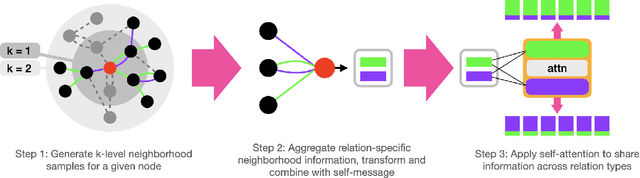
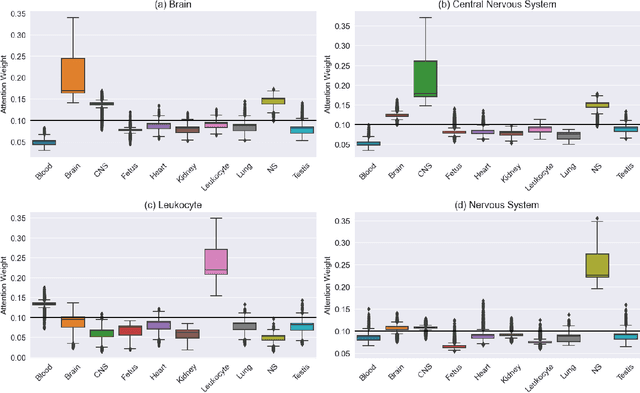
Graph Convolutional Neural Networks (GCNs) have become effective machine learning algorithms for many downstream network mining tasks such as node classification, link prediction, and community detection. However, most GCN methods have been developed for homogenous networks and are limited to a single embedding for each node. Complex systems, often represented by heterogeneous, multiplex networks present a more difficult challenge for GCN models and require that such techniques capture the diverse contexts and assorted interactions that occur between nodes. In this work, we propose RAHMeN, a novel unified relation-aware embedding framework for attributed heterogeneous multiplex networks. Our model incorporates node attributes, motif-based features, relation-based GCN approaches, and relational self-attention to learn embeddings of nodes with respect to the various relations in a heterogeneous, multiplex network. In contrast to prior work, RAHMeN is a more expressive embedding framework that embraces the multi-faceted nature of nodes in such networks, producing a set of multi-embeddings that capture the varied and diverse contexts of nodes. We evaluate our model on four real-world datasets from Amazon, Twitter, YouTube, and Tissue PPIs in both transductive and inductive settings. Our results show that RAHMeN consistently outperforms comparable state-of-the-art network embedding models, and an analysis of RAHMeN's relational self-attention demonstrates that our model discovers interpretable connections between relations present in heterogeneous, multiplex networks.
A Machine Learning Pipeline to Examine Political Bias with Congressional Speeches
Sep 18, 2021
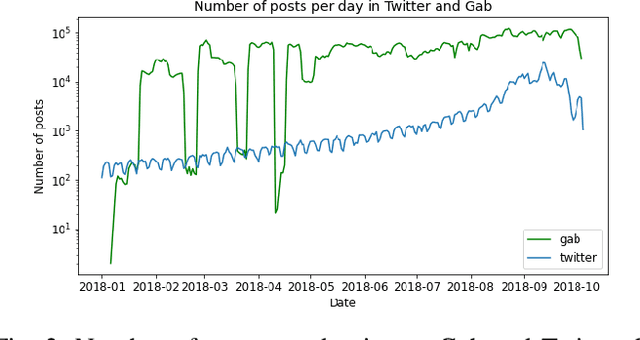
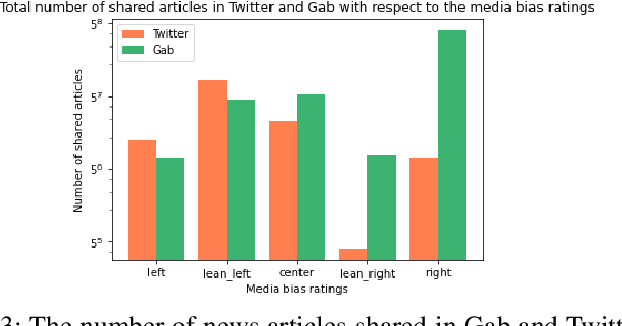
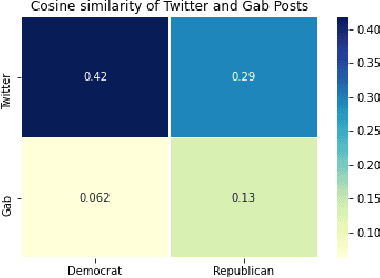
Computational methods to model political bias in social media involve several challenges due to heterogeneity, high-dimensional, multiple modalities, and the scale of the data. Political bias in social media has been studied in multiple viewpoints like media bias, political ideology, echo chambers, and controversies using machine learning pipelines. Most of the current methods rely heavily on the manually-labeled ground-truth data for the underlying political bias prediction tasks. Limitations of such methods include human-intensive labeling, labels related to only a specific problem, and the inability to determine the near future bias state of a social media conversation. In this work, we address such problems and give machine learning approaches to study political bias in two ideologically diverse social media forums: Gab and Twitter without the availability of human-annotated data. Our proposed methods exploit the use of transcripts collected from political speeches in US congress to label the data and achieve the highest accuracy of 70.5% and 65.1% in Twitter and Gab data respectively to predict political bias. We also present a machine learning approach that combines features from cascades and text to forecast cascade's political bias with an accuracy of about 85%.
DeL-haTE: A Deep Learning Tunable Ensemble for Hate Speech Detection
Nov 03, 2020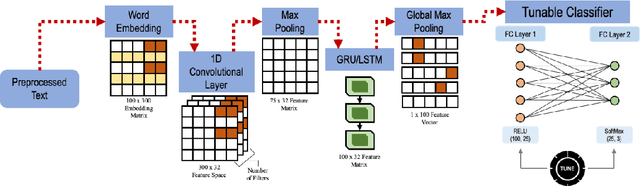

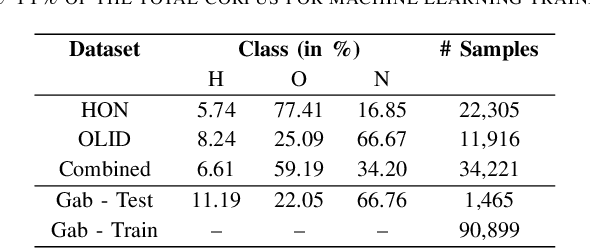

Online hate speech on social media has become a fast-growing problem in recent times. Nefarious groups have developed large content delivery networks across several main-stream (Twitter and Facebook) and fringe (Gab, 4chan, 8chan, etc.) outlets to deliver cascades of hate messages directed both at individuals and communities. Thus addressing these issues has become a top priority for large-scale social media outlets. Three key challenges in automated detection and classification of hateful content are the lack of clearly labeled data, evolving vocabulary and lexicon - hashtags, emojis, etc. - and the lack of baseline models for fringe outlets such as Gab. In this work, we propose a novel framework with three major contributions. (a) We engineer an ensemble of deep learning models that combines the strengths of state-of-the-art approaches, (b) we incorporate a tuning factor into this framework that leverages transfer learning to conduct automated hate speech classification on unlabeled datasets, like Gab, and (c) we develop a weak supervised learning methodology that allows our framework to train on unlabeled data. Our ensemble models achieve an 83% hate recall on the HON dataset, surpassing the performance of the state-of-the-art deep models. We demonstrate that weak supervised training in combination with classifier tuning significantly increases model performance on unlabeled data from Gab, achieving a hate recall of 67%.
Detecting Online Hate Speech: Approaches Using Weak Supervision and Network Embedding Models
Jul 24, 2020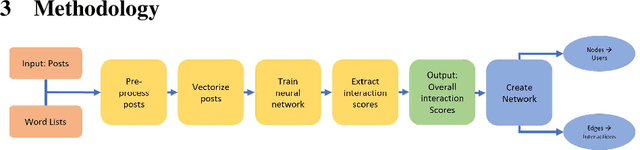
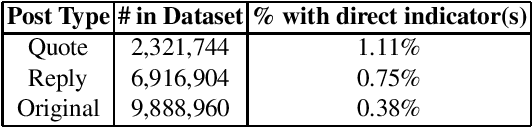

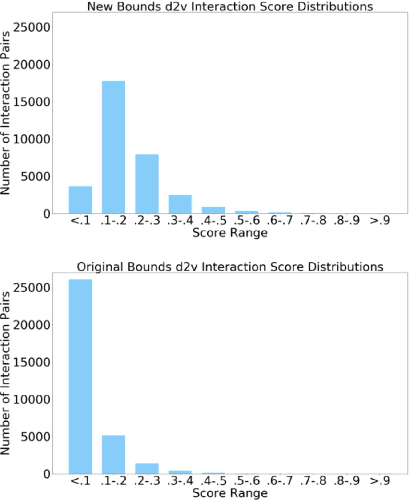
The ubiquity of social media has transformed online interactions among individuals. Despite positive effects, it has also allowed anti-social elements to unite in alternative social media environments (eg. Gab.com) like never before. Detecting such hateful speech using automated techniques can allow social media platforms to moderate their content and prevent nefarious activities like hate speech propagation. In this work, we propose a weak supervision deep learning model that - (i) quantitatively uncover hateful users and (ii) present a novel qualitative analysis to uncover indirect hateful conversations. This model scores content on the interaction level, rather than the post or user level, and allows for characterization of users who most frequently participate in hateful conversations. We evaluate our model on 19.2M posts and show that our weak supervision model outperforms the baseline models in identifying indirect hateful interactions. We also analyze a multilayer network, constructed from two types of user interactions in Gab(quote and reply) and interaction scores from the weak supervision model as edge weights, to predict hateful users. We utilize the multilayer network embedding methods to generate features for the prediction task and we show that considering user context from multiple networks help achieving better predictions of hateful users in Gab. We receive up to 7% performance gain compared to single layer or homogeneous network embedding models.
ragamAI: A Network Based Recommender System to Arrange a Indian Classical Music Concert
Dec 08, 2019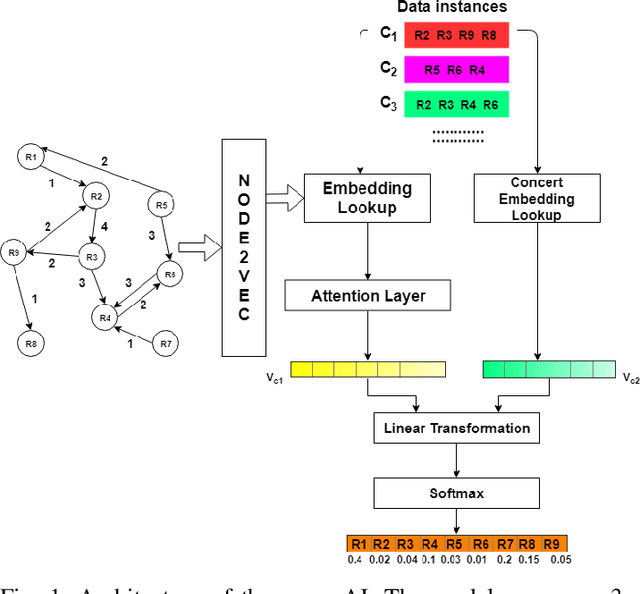
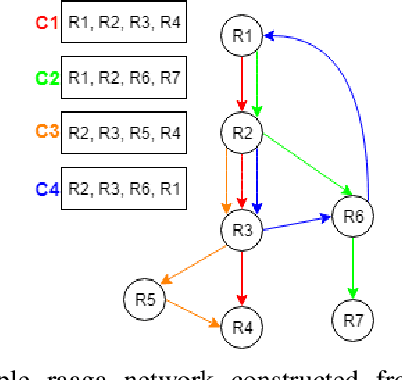
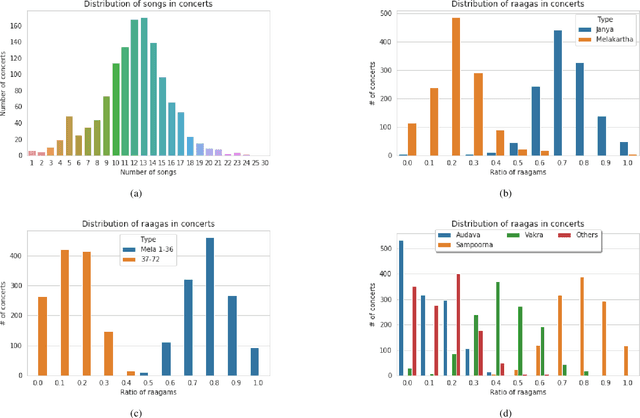
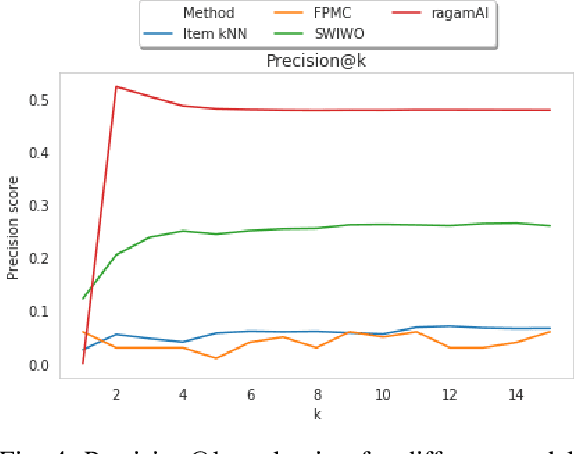
South Indian classical music (Carnatic music) is best consumed through live concerts. A carnatic recital requires meticulous planning accounting for several parameters like the performers' repertoire, composition variety, musical versatility, thematic structure, the recital's arrangement, etc. to ensure that the audience have a comprehensive listening experience. In this work, we present ragamAI a novel machine learning framework that utilizes the tonic nuances and musical structures in the carnatic music to generate a concert recital that melodically captures the entire range in an octave. Utilizing the underlying idea of playlist and session-based recommender models, the proposed model studies the mathematical structure present in past concerts and recommends relevant items for the playlist/concert. ragamAI ensembles recommendations given by multiple models to learn user idea and past preference of sequences in concerts to extract recommendations. Our experiments on a vast collection of concert show that our model performs 25%-50% better than baseline models. ragamAI's applications are two-fold. 1) it will assist musicians to customize their performance with the necessary variety required to sustain the interest of the audience for the entirety of the concert 2) it will generate carefully curated lists of south Indian classical music so that the listener can discover the wide range of melody that the musical system can offer.
Examining Untempered Social Media: Analyzing Cascades of Polarized Conversations
Jun 10, 2019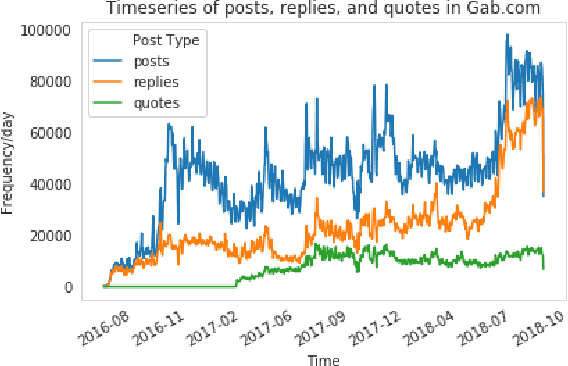
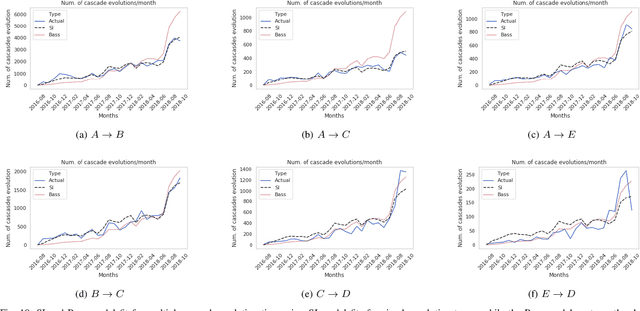
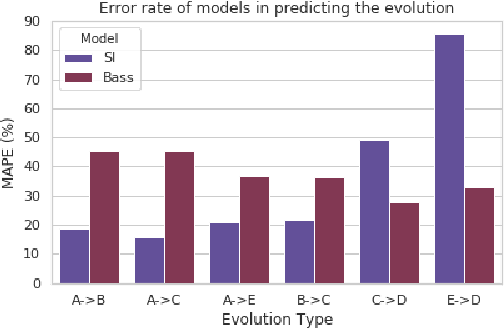
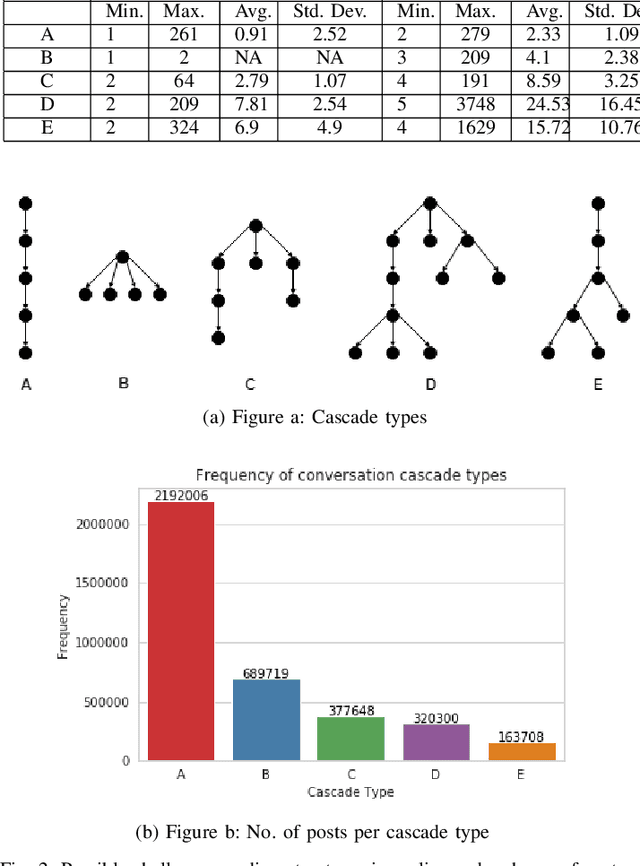
Online social media, periodically serves as a platform for cascading polarizing topics of conversation. The inherent community structure present in online social networks (homophily) and the advent of fringe outlets like Gab have created online "echo chambers" that amplify the effects of polarization, which fuels detrimental behavior. Recently, in October 2018, Gab made headlines when it was revealed that Robert Bowers, the individual behind the Pittsburgh Synagogue massacre, was an active member of this social media site and used it to express his anti-Semitic views and discuss conspiracy theories. Thus to address the need of automated data-driven analyses of such fringe outlets, this research proposes novel methods to discover topics that are prevalent in Gab and how they cascade within the network. Specifically, using approximately 34 million posts, and 3.7 million cascading conversation threads with close to 300k users; we demonstrate that there are essentially five cascading patterns that manifest in Gab and the most "viral" ones begin with an echo-chamber pattern and grow out to the entire network. Also, we empirically show, through two models viz. Susceptible-Infected and Bass, how the cascades structurally evolve from one of the five patterns to the other based on the topic of the conversation with upto 84% accuracy.