 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGLETS: A System for Automatic Semi-Supervised Learning with Auxiliary Data
Nov 10, 2021
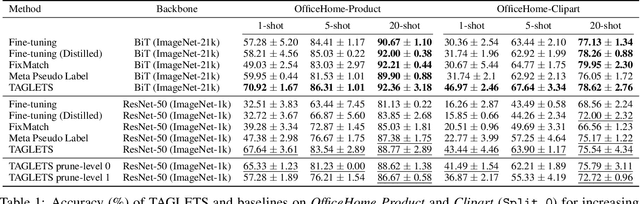
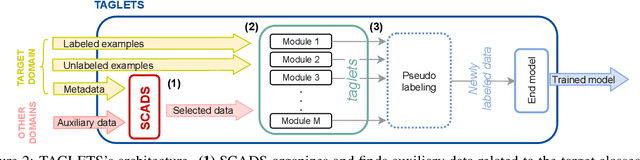
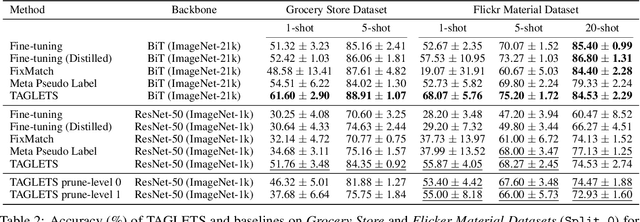
Machine learning practitioners often have access to a spectrum of data: labeled data for the target task (which is often limited), unlabeled data, and auxiliary data, the many available labeled datasets for other tasks. We describe TAGLETS, a system built to study techniques for automatically exploiting all three types of data and creating high-quality, servable classifiers. The key components of TAGLETS are: (1) auxiliary data organized according to a knowledge graph, (2) modules encapsulating different methods for exploiting auxiliary and unlabeled data, and (3) a distillation stage in which the ensembled modules are combined into a servable model. We compare TAGLETS with state-of-the-art transfer learning and semi-supervised learning methods on four image classification tasks. Our study covers a range of settings, varying the amount of labeled data and the semantic relatedness of the auxiliary data to the target task. We find that the intelligent incorporation of auxiliary and unlabeled data into multiple learning techniques enables TAGLETS to match-and most often significantly surpass-these alternatives. TAGLETS is available as an open-source system at github.com/BatsResearch/taglets.
DomiKnowS: A Library for Integration of Symbolic Domain Knowledge in Deep Learning
Aug 27, 2021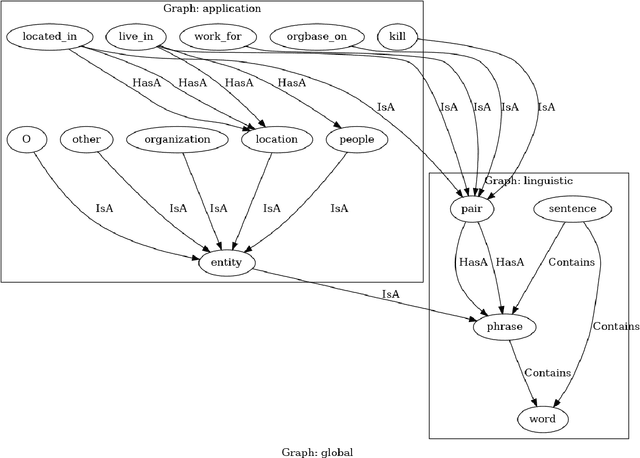

We demonstrate a library for the integration of domain knowledge in deep learning architectures. Using this library, the structure of the data is expressed symbolically via graph declarations and the logical constraints over outputs or latent variables can be seamlessly added to the deep models. The domain knowledge can be defined explicitly, which improves the models' explainability in addition to the performance and generalizability in the low-data regime. Several approaches for such an integration of symbolic and sub-symbolic models have been introduced; however, there is no library to facilitate the programming for such an integration in a generic way while various underlying algorithms can be used. Our library aims to simplify programming for such an integration in both training and inference phases while separating the knowledge representation from learning algorithms. We showcase various NLP benchmark tasks and beyond. The framework is publicly available at Github(https://github.com/HLR/DomiKnowS).
Detecting Online Hate Speech: Approaches Using Weak Supervision and Network Embedding Models
Jul 24, 2020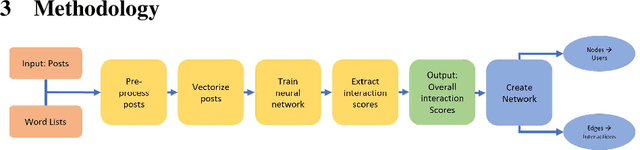
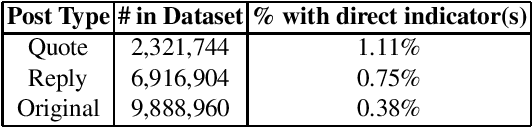

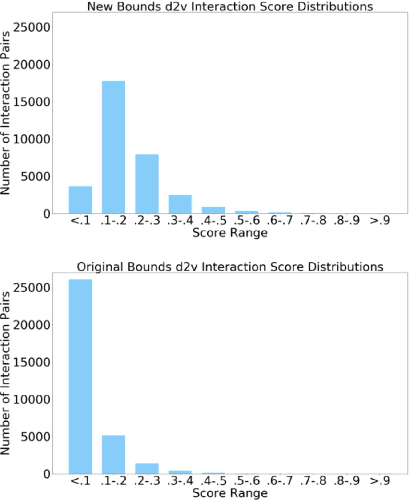
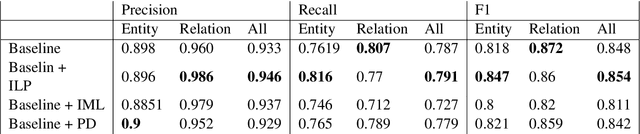
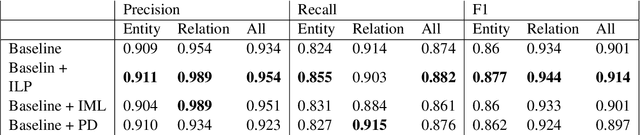
The ubiquity of social media has transformed online interactions among individuals. Despite positive effects, it has also allowed anti-social elements to unite in alternative social media environments (eg. Gab.com) like never before. Detecting such hateful speech using automated techniques can allow social media platforms to moderate their content and prevent nefarious activities like hate speech propagation. In this work, we propose a weak supervision deep learning model that - (i) quantitatively uncover hateful users and (ii) present a novel qualitative analysis to uncover indirect hateful conversations. This model scores content on the interaction level, rather than the post or user level, and allows for characterization of users who most frequently participate in hateful conversations. We evaluate our model on 19.2M posts and show that our weak supervision model outperforms the baseline models in identifying indirect hateful interactions. We also analyze a multilayer network, constructed from two types of user interactions in Gab(quote and reply) and interaction scores from the weak supervision model as edge weights, to predict hateful users. We utilize the multilayer network embedding methods to generate features for the prediction task and we show that considering user context from multiple networks help achieving better predictions of hateful users in Gab. We receive up to 7% performance gain compared to single layer or homogeneous network embedding models.
Incremental Nonparametric Weighted Feature Extraction for OnlineSubspace Pattern Classification
Oct 26, 2016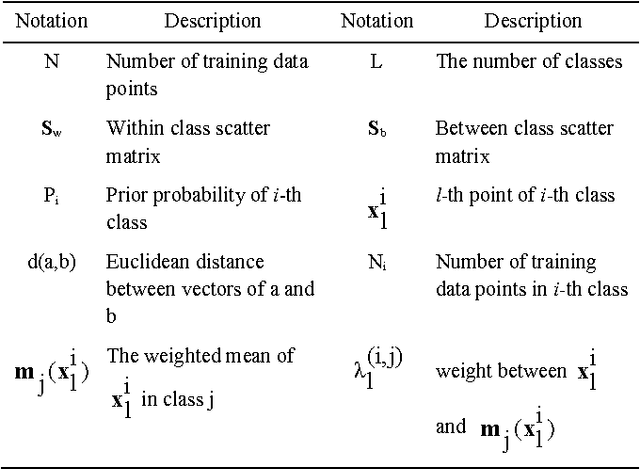
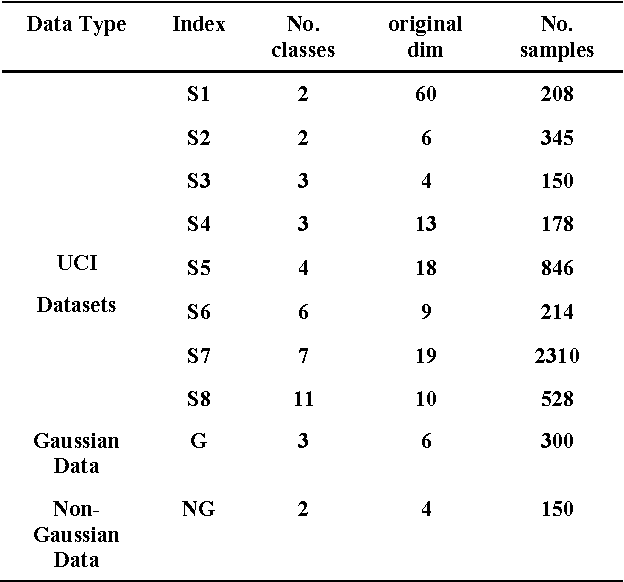
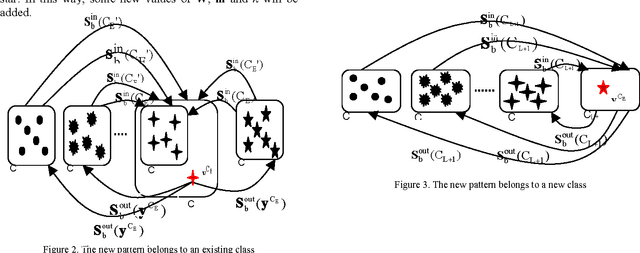
In this paper, a new online method based on nonparametric weighted feature extraction (NWFE) is proposed. NWFE was introduced to enjoy optimum characteristics of linear discriminant analysis (LDA) and nonparametric discriminant analysis (NDA) while rectifying their drawbacks. It emphasizes the points near decision boundary by putting greater weights on them and deemphasizes other points. Incremental nonparametric weighted feature extraction (INWFE) is the online version of NWFE. INWFE has advantages of NWFE method such as extracting more than L-1 features in contrast to LDA. It is independent of the class distribution and performs well in complex distributed data. The effects of outliers are reduced due to the nature of its nonparametric scatter matrix. Furthermore, it is possible to add new samples asynchronously, i.e. whenever a new sample becomes available at any given time, it can be added to the algorithm. This is useful for many real world applications since all data cannot be available in advance. This method is implemented on Gaussian and non-Gaussian multidimensional data, a number of UCI datasets and Indian Pine dataset. Results are compared with NWFE in terms of classification accuracy and execution time. For nearest neighbour classifier it shows that this technique converges to NWFE at the end of learning process. In addition, the computational complexity is reduced in comparison with NWFE in terms of execution time.
Cyberbullying Identification Using Participant-Vocabulary Consistency
Jun 26, 2016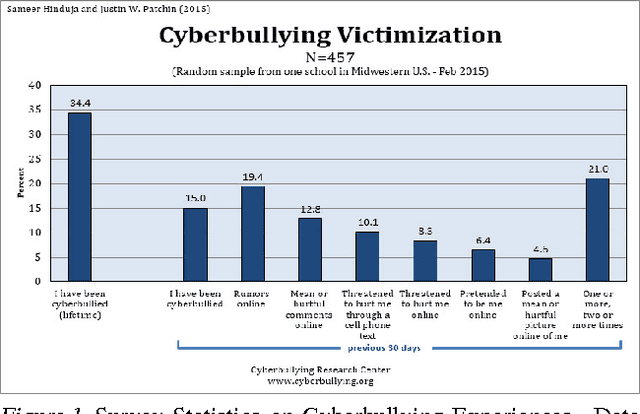

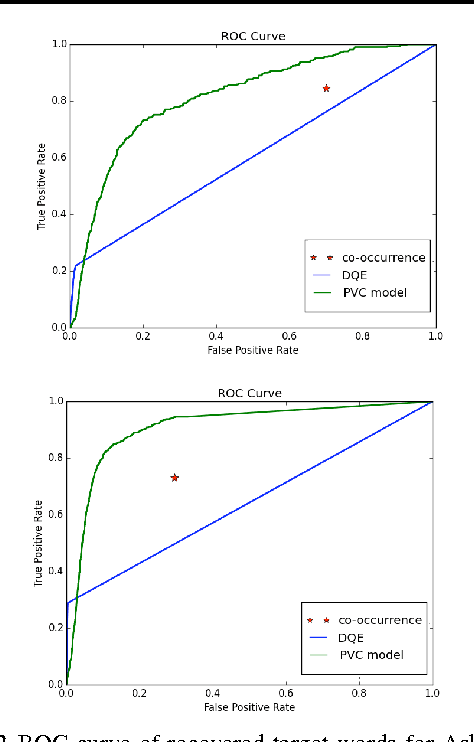

With the rise of social media, people can now form relationships and communities easily regardless of location, race, ethnicity, or gender. However, the power of social media simultaneously enables harmful online behavior such as harassment and bullying. Cyberbullying is a serious social problem, making it an important topic in social network analysis. Machine learning methods can potentially help provide better understanding of this phenomenon, but they must address several key challenges: the rapidly changing vocabulary involved in cyber- bullying, the role of social network structure, and the scale of the data. In this study, we propose a model that simultaneously discovers instigators and victims of bullying as well as new bullying vocabulary by starting with a corpus of social interactions and a seed dictionary of bullying indicators. We formulate an objective function based on participant-vocabulary consistency. We evaluate this approach on Twitter and Ask.fm data sets and show that the proposed method can detect new bullying vocabulary as well as victims and bullies.