 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Look at Targeted Instruction Selection: Disentangling What Matters (and What Doesn't)
Feb 16, 2026Instruction fine-tuning of large language models (LLMs) often involves selecting a subset of instruction training data from a large candidate pool, using a small query set from the target task. Despite growing interest, the literature on targeted instruction selection remains fragmented and opaque: methods vary widely in selection budgets, often omit zero-shot baselines, and frequently entangle the contributions of key components. As a result, practitioners lack actionable guidance on selecting instructions for their target tasks. In this work, we aim to bring clarity to this landscape by disentangling and systematically analyzing the two core ingredients: data representation and selection algorithms. Our framework enables controlled comparisons across models, tasks, and budgets. We find that only gradient-based data representations choose subsets whose similarity to the query consistently predicts performance across datasets and models. While no single method dominates, gradient-based representations paired with a greedy round-robin selection algorithm tend to perform best on average at low budgets, but these benefits diminish at larger budgets. Finally, we unify several existing selection algorithms as forms of approximate distance minimization between the selected subset and the query set, and support this view with new generalization bounds. More broadly, our findings provide critical insights and a foundation for more principled data selection in LLM fine-tuning. The code is available at https://github.com/dcml-lab/targeted-instruction-selection.
Boomerang Distillation Enables Zero-Shot Model Size Interpolation
Oct 06, 2025Large language models (LLMs) are typically deployed under diverse memory and compute constraints. Existing approaches build model families by training each size independently, which is prohibitively expensive and provides only coarse-grained size options. In this work, we identify a novel phenomenon that we call boomerang distillation: starting from a large base model (the teacher), one first distills down to a small student and then progressively reconstructs intermediate-sized models by re-incorporating blocks of teacher layers into the student without any additional training. This process produces zero-shot interpolated models of many intermediate sizes whose performance scales smoothly between the student and teacher, often matching or surpassing pretrained or distilled models of the same size. We further analyze when this type of interpolation succeeds, showing that alignment between teacher and student through pruning and distillation is essential. Boomerang distillation thus provides a simple and efficient way to generate fine-grained model families, dramatically reducing training cost while enabling flexible adaptation across deployment environments. The code and models are available at https://github.com/dcml-lab/boomerang-distillation.
K-Paths: Reasoning over Graph Paths for Drug Repurposing and Drug Interaction Prediction
Feb 18, 2025Drug discovery is a complex and time-intensive process that requires identifying and validating new therapeutic candidates. Computational approaches using large-scale biomedical knowledge graphs (KGs) offer a promising solution to accelerate this process. However, extracting meaningful insights from large-scale KGs remains challenging due to the complexity of graph traversal. Existing subgraph-based methods are tailored to graph neural networks (GNNs), making them incompatible with other models, such as large language models (LLMs). We introduce K-Paths, a retrieval framework that extracts structured, diverse, and biologically meaningful paths from KGs. Integrating these paths enables LLMs and GNNs to effectively predict unobserved drug-drug and drug-disease interactions. Unlike traditional path-ranking approaches, K-Paths retrieves and transforms paths into a structured format that LLMs can directly process, facilitating explainable reasoning. K-Paths employs a diversity-aware adaptation of Yen's algorithm to retrieve the K shortest loopless paths between entities in an interaction query, prioritizing biologically relevant and diverse relationships. Our experiments on benchmark datasets show that K-Paths improves the zero-shot performance of Llama 8.1B's F1-score by 12.45 points on drug repurposing and 13.42 points on interaction severity prediction. We also show that Llama 70B achieves F1-score gains of 6.18 and 8.46 points, respectively. K-Paths also improves the supervised training efficiency of EmerGNN, a state-of-the-art GNN, by reducing KG size by 90% while maintaining strong predictive performance. Beyond its scalability and efficiency, K-Paths uniquely bridges the gap between KGs and LLMs, providing explainable rationales for predicted interactions. These capabilities show that K-Paths is a valuable tool for efficient data-driven drug discovery.
$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Oct 30, 2024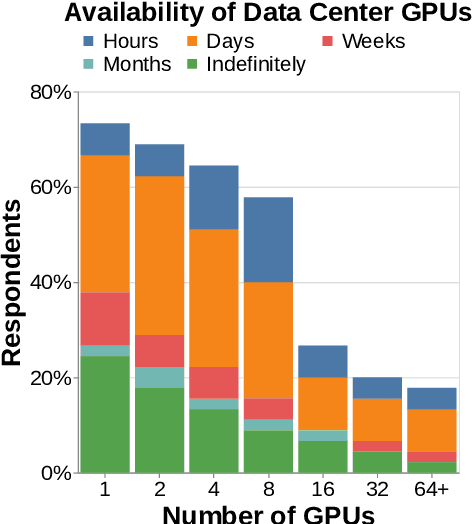
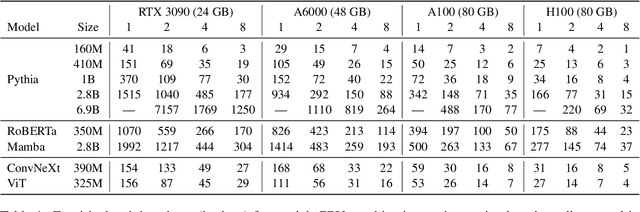
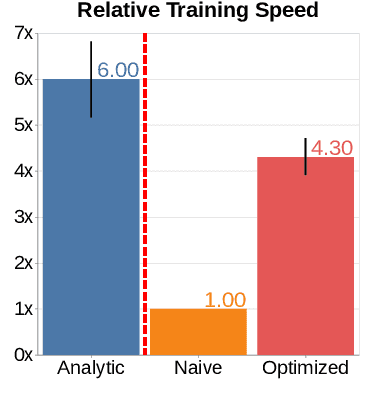
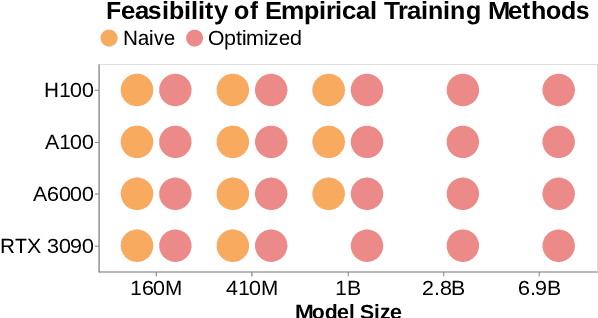
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek to clarify this assumption. We first survey academic researchers to learn about their available compute and then empirically measure the time to replicate models on such resources. We introduce a benchmark to measure the time to pre-train models on given GPUs and also identify ideal settings for maximizing training speed. We run our benchmark on a range of models and academic GPUs, spending 2,000 GPU-hours on our experiments. Our results reveal a brighter picture for academic pre-training: for example, although Pythia-1B was originally trained on 64 GPUs for 3 days, we find it is also possible to replicate this model (with the same hyper-parameters) in 3x fewer GPU-days: i.e. on 4 GPUs in 18 days. We conclude with a cost-benefit analysis to help clarify the trade-offs between price and pre-training time. We believe our benchmark will help academic researchers conduct experiments that require training larger models on more data. We fully release our codebase at: https://github.com/apoorvkh/academic-pretraining.
Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
Feb 28, 2024We introduce Bonito, an open-source model for conditional task generation: the task of converting unannotated text into task-specific training datasets for instruction tuning. Our goal is to enable zero-shot task adaptation of large language models on users' specialized, private data. We train Bonito on a new large-scale dataset with 1.65M examples created by remixing existing instruction tuning datasets into meta-templates. The meta-templates for a dataset produce training examples where the input is the unannotated text and the task attribute and the output consists of the instruction and the response. We use Bonito to generate synthetic tasks for seven datasets from specialized domains across three task types -- yes-no question answering, extractive question answering, and natural language inference -- and adapt language models. We show that Bonito significantly improves the average performance of pretrained and instruction tuned models over the de facto self supervised baseline. For example, adapting Mistral-Instruct-v2 and instruction tuned variants of Mistral and Llama2 with Bonito improves the strong zero-shot performance by 22.1 F1 points whereas the next word prediction objective undoes some of the benefits of instruction tuning and reduces the average performance by 0.8 F1 points. We conduct additional experiments with Bonito to understand the effects of the domain, the size of the training set, and the choice of alternative synthetic task generators. Overall, we show that learning with synthetic instruction tuning datasets is an effective way to adapt language models to new domains. The model, dataset, and code are available at https://github.com/BatsResearch/bonito.
CEREAL: Few-Sample Clustering Evaluation
Sep 30, 2022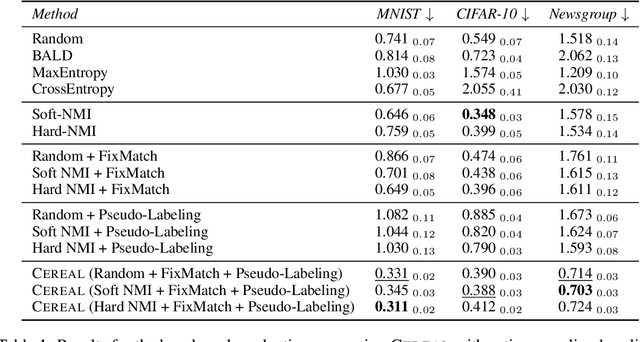



Evaluating clustering quality with reliable evaluation metrics like normalized mutual information (NMI) requires labeled data that can be expensive to annotate. We focus on the underexplored problem of estimating clustering quality with limited labels. We adapt existing approaches from the few-sample model evaluation literature to actively sub-sample, with a learned surrogate model, the most informative data points for annotation to estimate the evaluation metric. However, we find that their estimation can be biased and only relies on the labeled data. To that end, we introduce CEREAL, a comprehensive framework for few-sample clustering evaluation that extends active sampling approaches in three key ways. First, we propose novel NMI-based acquisition functions that account for the distinctive properties of clustering and uncertainties from a learned surrogate model. Next, we use ideas from semi-supervised learning and train the surrogate model with both the labeled and unlabeled data. Finally, we pseudo-label the unlabeled data with the surrogate model. We run experiments to estimate NMI in an active sampling pipeline on three datasets across vision and language. Our results show that CEREAL reduces the area under the absolute error curve by up to 57% compared to the best sampling baseline. We perform an extensive ablation study to show that our framework is agnostic to the choice of clustering algorithm and evaluation metric. We also extend CEREAL from clusterwise annotations to pairwise annotations. Overall, CEREAL can efficiently evaluate clustering with limited human annotations.
Learning to Compose Soft Prompts for Compositional Zero-Shot Learning
Apr 07, 2022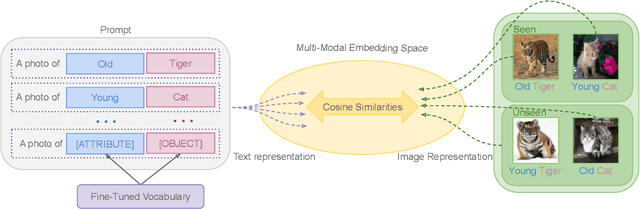


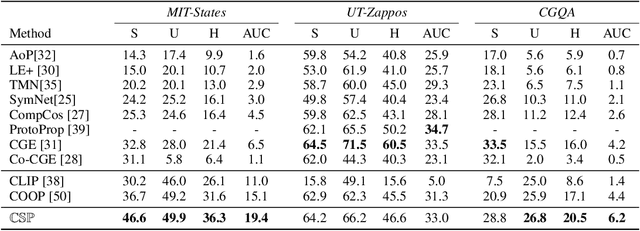
We introduce compositional soft prompting (CSP), a parameter-efficient learning technique to improve the zero-shot compositionality of large-scale pretrained vision-language models (VLMs) without the overhead of fine-tuning the entire model. VLMs can represent arbitrary classes as natural language prompts in their flexible text encoders but they underperform state-of-the-art methods on compositional zero-shot benchmark tasks. To improve VLMs, we propose a novel form of soft prompting. We treat the attributes and objects that are composed to define classes as learnable tokens of vocabulary and tune them on multiple prompt compositions. During inference, we recompose the learned attribute-object vocabulary in new combinations and show that CSP outperforms the original VLM on benchmark datasets by an average of 14.7 percentage points of accuracy. CSP also achieves new state-of-the-art accuracies on two out of three benchmark datasets, while only fine-tuning a small number of parameters. Further, we show that CSP improves generalization to higher-order attribute-attribute-object compositions and combinations of pretrained attributes and fine-tuned objects.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Feb 02, 2022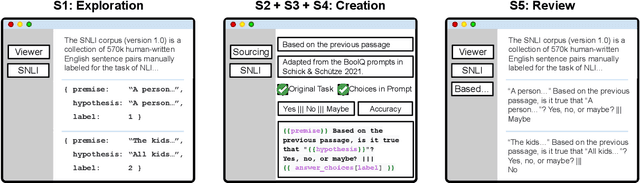
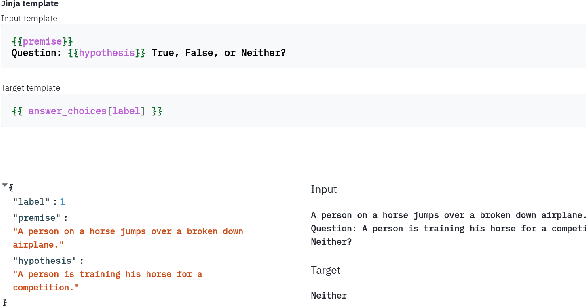

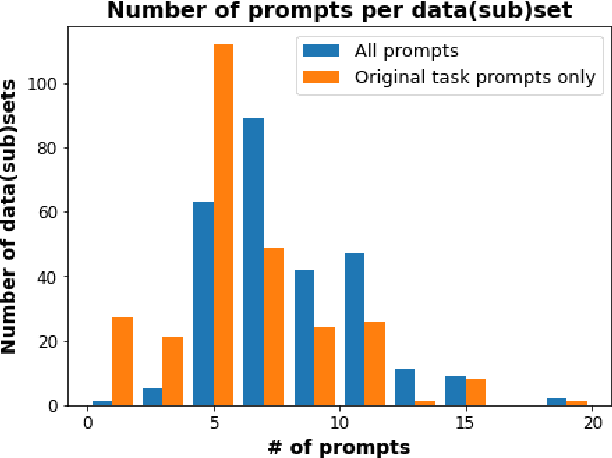
PromptSource is a system for creating, sharing, and using natural language prompts. Prompts are functions that map an example from a dataset to a natural language input and target output. Using prompts to train and query language models is an emerging area in NLP that requires new tools that let users develop and refine these prompts collaboratively. PromptSource addresses the emergent challenges in this new setting with (1) a templating language for defining data-linked prompts, (2) an interface that lets users quickly iterate on prompt development by observing outputs of their prompts on many examples, and (3) a community-driven set of guidelines for contributing new prompts to a common pool. Over 2,000 prompts for roughly 170 datasets are already available in PromptSource. PromptSource is available at https://github.com/bigscience-workshop/promptsource.
TAGLETS: A System for Automatic Semi-Supervised Learning with Auxiliary Data
Nov 10, 2021
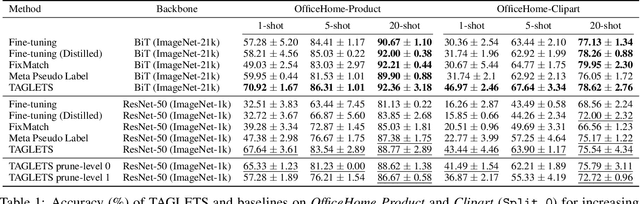
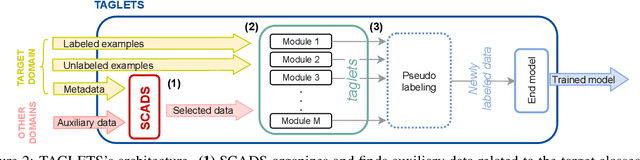
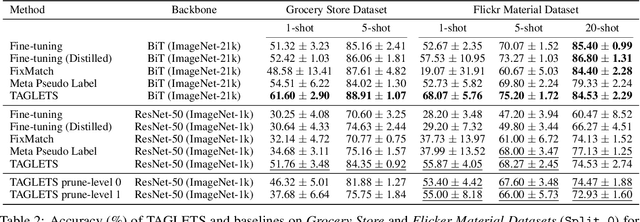
Machine learning practitioners often have access to a spectrum of data: labeled data for the target task (which is often limited), unlabeled data, and auxiliary data, the many available labeled datasets for other tasks. We describe TAGLETS, a system built to study techniques for automatically exploiting all three types of data and creating high-quality, servable classifiers. The key components of TAGLETS are: (1) auxiliary data organized according to a knowledge graph, (2) modules encapsulating different methods for exploiting auxiliary and unlabeled data, and (3) a distillation stage in which the ensembled modules are combined into a servable model. We compare TAGLETS with state-of-the-art transfer learning and semi-supervised learning methods on four image classification tasks. Our study covers a range of settings, varying the amount of labeled data and the semantic relatedness of the auxiliary data to the target task. We find that the intelligent incorporation of auxiliary and unlabeled data into multiple learning techniques enables TAGLETS to match-and most often significantly surpass-these alternatives. TAGLETS is available as an open-source system at github.com/BatsResearch/taglets.
Zero-Shot Learning with Common Sense Knowledge Graphs
Jun 18, 2020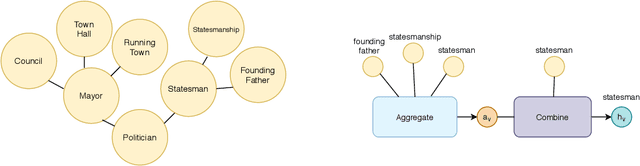
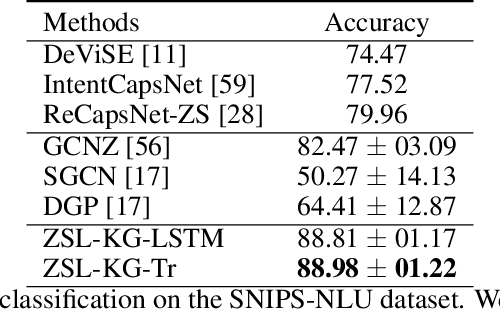
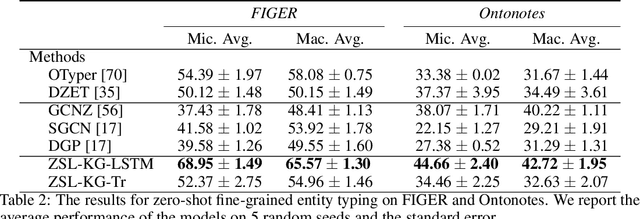
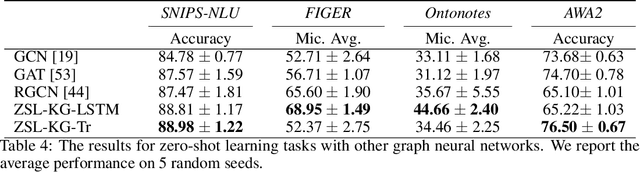
Zero-shot learning relies on semantic class representations such as attributes or pretrained embeddings to predict classes without any labeled examples. We propose to learn class representations from common sense knowledge graphs. Common sense knowledge graphs are an untapped source of explicit high-level knowledge that requires little human effort to apply to a range of tasks. To capture the knowledge in the graph, we introduce ZSL-KG, a framework based on graph neural networks with non-linear aggregators to generate class representations. Whereas most prior work on graph neural networks uses linear functions to aggregate information from neighboring nodes, we find that non-linear aggregators such as LSTMs or transformers lead to significant improvements on zero-shot tasks. On two natural language tasks across three datasets, ZSL-KG shows an average improvement of 9.2 points of accuracy versus state-of-the-art methods. In addition, on an object classification task, ZSL-KG shows a 2.2 accuracy point improvement versus the best methods that do not require hand-engineered class representations. Finally, we find that ZSL-KG outperforms the best performing graph neural networks with linear aggregators by an average of 3.8 points of accuracy across these four datasets.