 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compose Soft Prompts for Compositional Zero-Shot Learning
Paper and Code
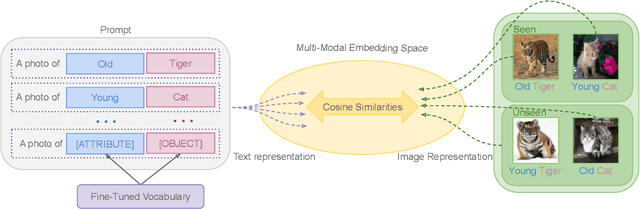


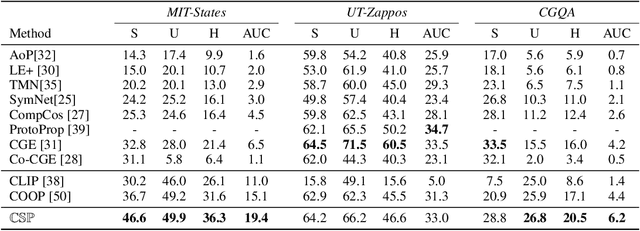
We introduce compositional soft prompting (CSP), a parameter-efficient learning technique to improve the zero-shot compositionality of large-scale pretrained vision-language models (VLMs) without the overhead of fine-tuning the entire model. VLMs can represent arbitrary classes as natural language prompts in their flexible text encoders but they underperform state-of-the-art methods on compositional zero-shot benchmark tasks. To improve VLMs, we propose a novel form of soft prompting. We treat the attributes and objects that are composed to define classes as learnable tokens of vocabulary and tune them on multiple prompt compositions. During inference, we recompose the learned attribute-object vocabulary in new combinations and show that CSP outperforms the original VLM on benchmark datasets by an average of 14.7 percentage points of accuracy. CSP also achieves new state-of-the-art accuracies on two out of three benchmark datasets, while only fine-tuning a small number of parameters. Further, we show that CSP improves generalization to higher-order attribute-attribute-object compositions and combinations of pretrained attributes and fine-tuned objects.