 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Dual Feature Augmentation for Open-Environment
Jun 10, 2025Feature augmentation generates novel samples in the feature space, providing an effective way to enhance the generalization ability of learning algorithms with hyperbolic geometry. Most hyperbolic feature augmentation is confined to closed-environment, assuming the number of classes is fixed (\emph{i.e.}, seen classes) and generating features only for these classes. In this paper, we propose a hyperbolic dual feature augmentation method for open-environment, which augments features for both seen and unseen classes in the hyperbolic space. To obtain a more precise approximation of the real data distribution for efficient training, (1) we adopt a neural ordinary differential equation module, enhanced by meta-learning, estimating the feature distributions of both seen and unseen classes; (2) we then introduce a regularizer to preserve the latent hierarchical structures of data in the hyperbolic space; (3) we also derive an upper bound for the hyperbolic dual augmentation loss, allowing us to train a hyperbolic model using infinite augmentations for seen and unseen classes. Extensive experiments on five open-environment tasks: class-incremental learning, few-shot open-set recognition, few-shot learning, zero-shot learning, and general image classification, demonstrate that our method effectively enhances the performance of hyperbolic algorithms in open-environment.
Large-Scale Riemannian Meta-Optimization via Subspace Adaptation
Jan 25, 2025
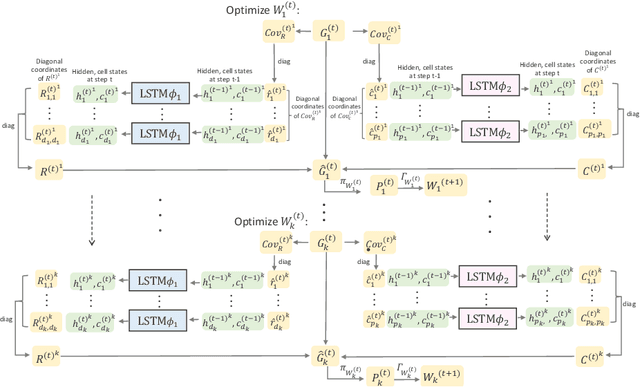

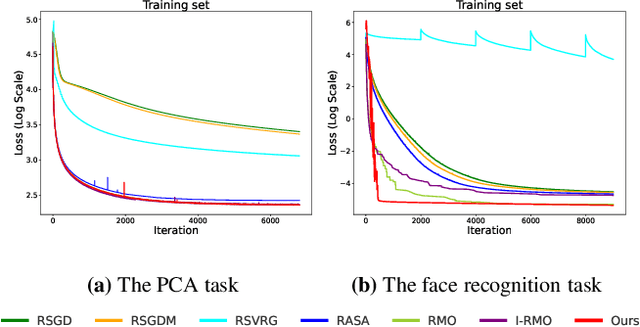
Riemannian meta-optimization provides a promising approach to solving non-linear constrained optimization problems, which trains neural networks as optimizers to perform optimization on Riemannian manifolds. However, existing Riemannian meta-optimization methods take up huge memory footprints in large-scale optimization settings, as the learned optimizer can only adapt gradients of a fixed size and thus cannot be shared across different Riemannian parameters. In this paper, we propose an efficient Riemannian meta-optimization method that significantly reduces the memory burden for large-scale optimization via a subspace adaptation scheme. Our method trains neural networks to individually adapt the row and column subspaces of Riemannian gradients, instead of directly adapting the full gradient matrices in existing Riemannian meta-optimization methods. In this case, our learned optimizer can be shared across Riemannian parameters with different sizes. Our method reduces the model memory consumption by six orders of magnitude when optimizing an orthogonal mainstream deep neural network (e.g., ResNet50). Experiments on multiple Riemannian tasks show that our method can not only reduce the memory consumption but also improve the performance of Riemannian meta-optimization.
Leveraging Large Language Models for Structure Learning in Prompted Weak Supervision
Feb 02, 2024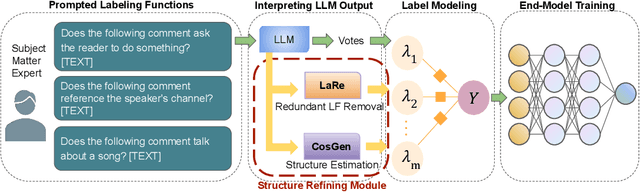


Prompted weak supervision (PromptedWS) applies pre-trained large language models (LLMs) as the basis for labeling functions (LFs) in a weak supervision framework to obtain large labeled datasets. We further extend the use of LLMs in the loop to address one of the key challenges in weak supervision: learning the statistical dependency structure among supervision sources. In this work, we ask the LLM how similar are these prompted LFs. We propose a Structure Refining Module, a simple yet effective first approach based on the similarities of the prompts by taking advantage of the intrinsic structure in the embedding space. At the core of Structure Refining Module are Labeling Function Removal (LaRe) and Correlation Structure Generation (CosGen). Compared to previous methods that learn the dependencies from weak labels, our method finds the dependencies which are intrinsic to the LFs and less dependent on the data. We show that our Structure Refining Module improves the PromptedWS pipeline by up to 12.7 points on the benchmark tasks. We also explore the trade-offs between efficiency and performance with comprehensive ablation experiments and analysis. Code for this project can be found in https://github.com/BatsResearch/su-bigdata23-code.
Alfred: A System for Prompted Weak Supervision
May 29, 2023



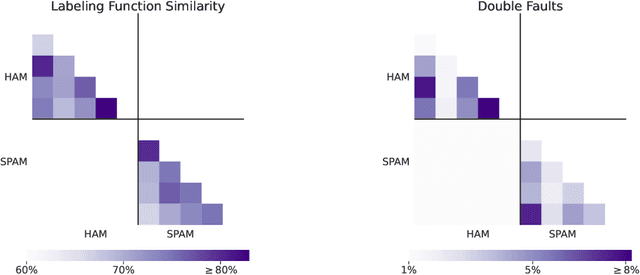
Alfred is the first system for programmatic weak supervision (PWS) that creates training data for machine learning by prompting. In contrast to typical PWS systems where weak supervision sources are programs coded by experts, Alfred enables users to encode their subject matter expertise via natural language prompts for language and vision-language models. Alfred provides a simple Python interface for the key steps of this emerging paradigm, with a high-throughput backend for large-scale data labeling. Users can quickly create, evaluate, and refine their prompt-based weak supervision sources; map the results to weak labels; and resolve their disagreements with a label model. Alfred enables a seamless local development experience backed by models served from self-managed computing clusters. It automatically optimizes the execution of prompts with optimized batching mechanisms. We find that this optimization improves query throughput by 2.9x versus a naive approach. We present two example use cases demonstrating Alfred on YouTube comment spam detection and pet breeds classification. Alfred is open source, available at https://github.com/BatsResearch/alfred.
Learning to Compose Soft Prompts for Compositional Zero-Shot Learning
Apr 07, 2022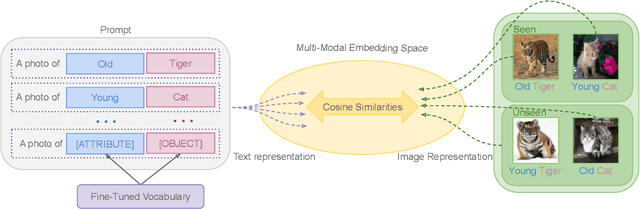


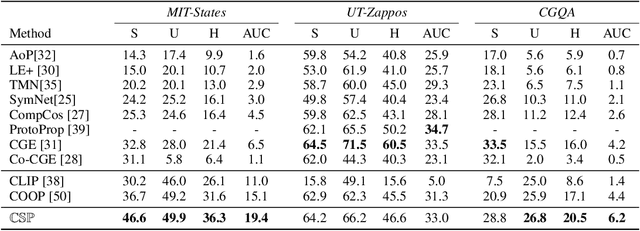
We introduce compositional soft prompting (CSP), a parameter-efficient learning technique to improve the zero-shot compositionality of large-scale pretrained vision-language models (VLMs) without the overhead of fine-tuning the entire model. VLMs can represent arbitrary classes as natural language prompts in their flexible text encoders but they underperform state-of-the-art methods on compositional zero-shot benchmark tasks. To improve VLMs, we propose a novel form of soft prompting. We treat the attributes and objects that are composed to define classes as learnable tokens of vocabulary and tune them on multiple prompt compositions. During inference, we recompose the learned attribute-object vocabulary in new combinations and show that CSP outperforms the original VLM on benchmark datasets by an average of 14.7 percentage points of accuracy. CSP also achieves new state-of-the-art accuracies on two out of three benchmark datasets, while only fine-tuning a small number of parameters. Further, we show that CSP improves generalization to higher-order attribute-attribute-object compositions and combinations of pretrained attributes and fine-tuned objects.
Learning from Multiple Noisy Partial Labelers
Jun 08, 2021


Programmatic weak supervision creates models without hand-labeled training data by combining the outputs of noisy, user-written rules and other heuristic labelers. Existing frameworks make the restrictive assumption that labelers output a single class label. Enabling users to create partial labelers that output subsets of possible class labels would greatly expand the expressivity of programmatic weak supervision. We introduce this capability by defining a probabilistic generative model that can estimate the underlying accuracies of multiple noisy partial labelers without ground truth labels. We prove that this class of models is generically identifiable up to label swapping under mild conditions. We also show how to scale up learning to 100k examples in one minute, a 300X speed up compared to a naive implementation. We evaluate our framework on three text classification and six object classification tasks. On text tasks, adding partial labels increases average accuracy by 9.6 percentage points. On image tasks, we show that partial labels allow us to approach some zero-shot object classification problems with programmatic weak supervision by using class attributes as partial labelers. Our framework is able to achieve accuracy comparable to recent embedding-based zero-shot learning methods using only pre-trained attribute detectors
DIAG-NRE: A Deep Pattern Diagnosis Framework for Distant Supervision Neural Relation Extraction
Nov 06, 2018
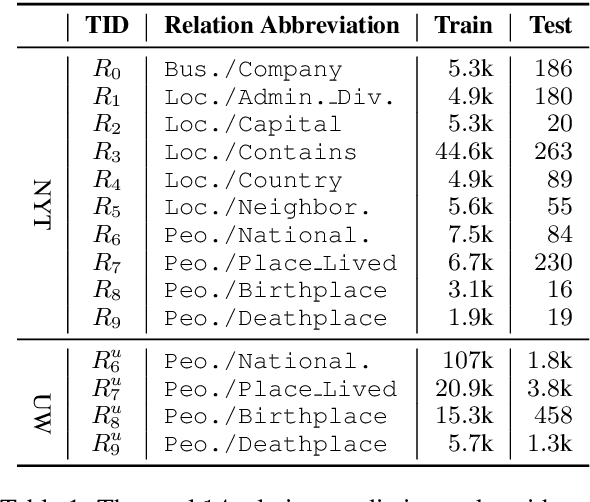
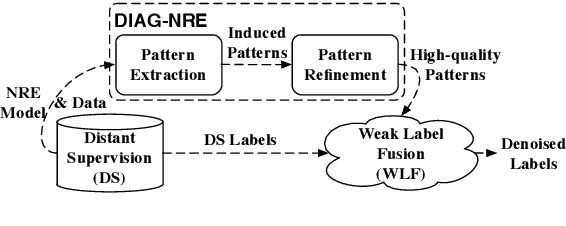
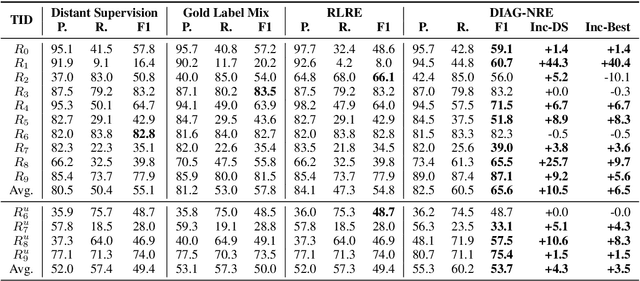
Modern neural network models have achieved the state-of-the-art performance on relation extraction (RE) tasks. Although distant supervision (DS) can automatically generate training labels for RE, the effectiveness of DS highly depends on datasets and relation types, and sometimes it may introduce large labeling noises. In this paper, we propose a deep pattern diagnosis framework, DIAG-NRE, that aims to diagnose and improve neural relation extraction (NRE) models trained on DS-generated data. DIAG-NRE includes three stages: (1) The deep pattern extraction stage employs reinforcement learning to extract regular-expression-style patterns from NRE models. (2) The pattern refinement stage builds a pattern hierarchy to find the most representative patterns and lets human reviewers evaluate them quantitatively by annotating a certain number of pattern-matched examples. In this way, we minimize both the number of labels to annotate and the difficulty of writing heuristic patterns. (3) The weak label fusion stage fuses multiple weak label sources, including DS and refined patterns, to produce noise-reduced labels that can train a better NRE model. To demonstrate the broad applicability of DIAG-NRE, we use it to diagnose 14 relation types of two public datasets with one simple hyper-parameter configuration. We observe different noise behaviors and obtain significant F1 improvements on all relation types suffering from large labeling noises.