 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025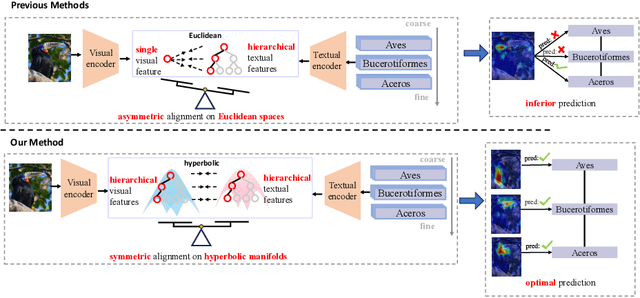
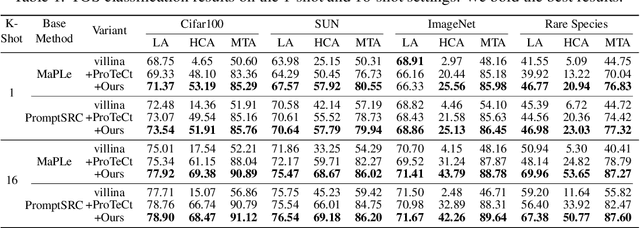
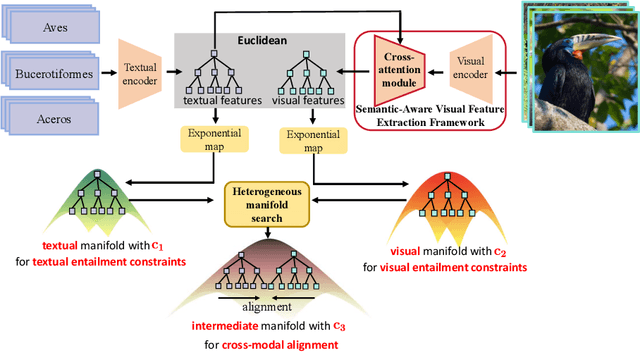

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
Beyond the Seen: Bounded Distribution Estimation for Open-Vocabulary Learning
Oct 06, 2025



Open-vocabulary learning requires modeling the data distribution in open environments, which consists of both seen-class and unseen-class data. Existing methods estimate the distribution in open environments using seen-class data, where the absence of unseen classes makes the estimation error inherently unidentifiable. Intuitively, learning beyond the seen classes is crucial for distribution estimation to bound the estimation error. We theoretically demonstrate that the distribution can be effectively estimated by generating unseen-class data, through which the estimation error is upper-bounded. Building on this theoretical insight, we propose a novel open-vocabulary learning method, which generates unseen-class data for estimating the distribution in open environments. The method consists of a class-domain-wise data generation pipeline and a distribution alignment algorithm. The data generation pipeline generates unseen-class data under the guidance of a hierarchical semantic tree and domain information inferred from the seen-class data, facilitating accurate distribution estimation. With the generated data, the distribution alignment algorithm estimates and maximizes the posterior probability to enhance generalization in open-vocabulary learning. Extensive experiments on $11$ datasets demonstrate that our method outperforms baseline approaches by up to $14\%$, highlighting its effectiveness and superiority.
Curvature Learning for Generalization of Hyperbolic Neural Networks
Aug 24, 2025Hyperbolic neural networks (HNNs) have demonstrated notable efficacy in representing real-world data with hierarchical structures via exploiting the geometric properties of hyperbolic spaces characterized by negative curvatures. Curvature plays a crucial role in optimizing HNNs. Inappropriate curvatures may cause HNNs to converge to suboptimal parameters, degrading overall performance. So far, the theoretical foundation of the effect of curvatures on HNNs has not been developed. In this paper, we derive a PAC-Bayesian generalization bound of HNNs, highlighting the role of curvatures in the generalization of HNNs via their effect on the smoothness of the loss landscape. Driven by the derived bound, we propose a sharpness-aware curvature learning method to smooth the loss landscape, thereby improving the generalization of HNNs. In our method, we design a scope sharpness measure for curvatures, which is minimized through a bi-level optimization process. Then, we introduce an implicit differentiation algorithm that efficiently solves the bi-level optimization by approximating gradients of curvatures. We present the approximation error and convergence analyses of the proposed method, showing that the approximation error is upper-bounded, and the proposed method can converge by bounding gradients of HNNs. Experiments on four settings: classification, learning from long-tailed data, learning from noisy data, and few-shot learning show that our method can improve the performance of HNNs.
Hyperbolic Dual Feature Augmentation for Open-Environment
Jun 10, 2025Feature augmentation generates novel samples in the feature space, providing an effective way to enhance the generalization ability of learning algorithms with hyperbolic geometry. Most hyperbolic feature augmentation is confined to closed-environment, assuming the number of classes is fixed (\emph{i.e.}, seen classes) and generating features only for these classes. In this paper, we propose a hyperbolic dual feature augmentation method for open-environment, which augments features for both seen and unseen classes in the hyperbolic space. To obtain a more precise approximation of the real data distribution for efficient training, (1) we adopt a neural ordinary differential equation module, enhanced by meta-learning, estimating the feature distributions of both seen and unseen classes; (2) we then introduce a regularizer to preserve the latent hierarchical structures of data in the hyperbolic space; (3) we also derive an upper bound for the hyperbolic dual augmentation loss, allowing us to train a hyperbolic model using infinite augmentations for seen and unseen classes. Extensive experiments on five open-environment tasks: class-incremental learning, few-shot open-set recognition, few-shot learning, zero-shot learning, and general image classification, demonstrate that our method effectively enhances the performance of hyperbolic algorithms in open-environment.
Large-Scale Riemannian Meta-Optimization via Subspace Adaptation
Jan 25, 2025
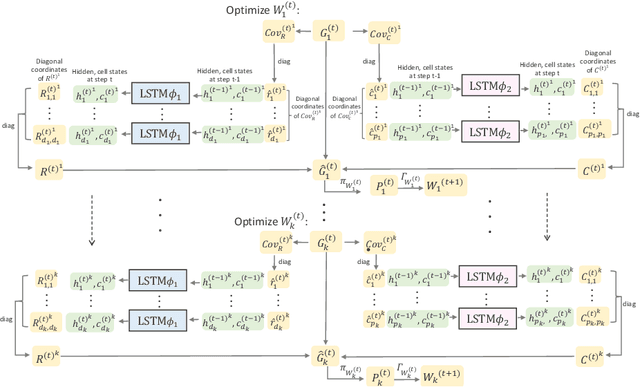

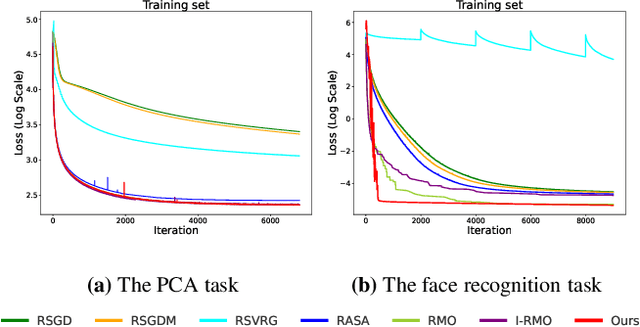
Riemannian meta-optimization provides a promising approach to solving non-linear constrained optimization problems, which trains neural networks as optimizers to perform optimization on Riemannian manifolds. However, existing Riemannian meta-optimization methods take up huge memory footprints in large-scale optimization settings, as the learned optimizer can only adapt gradients of a fixed size and thus cannot be shared across different Riemannian parameters. In this paper, we propose an efficient Riemannian meta-optimization method that significantly reduces the memory burden for large-scale optimization via a subspace adaptation scheme. Our method trains neural networks to individually adapt the row and column subspaces of Riemannian gradients, instead of directly adapting the full gradient matrices in existing Riemannian meta-optimization methods. In this case, our learned optimizer can be shared across Riemannian parameters with different sizes. Our method reduces the model memory consumption by six orders of magnitude when optimizing an orthogonal mainstream deep neural network (e.g., ResNet50). Experiments on multiple Riemannian tasks show that our method can not only reduce the memory consumption but also improve the performance of Riemannian meta-optimization.
Consistency of Compositional Generalization across Multiple Levels
Dec 18, 2024



Compositional generalization is the capability of a model to understand novel compositions composed of seen concepts. There are multiple levels of novel compositions including phrase-phrase level, phrase-word level, and word-word level. Existing methods achieve promising compositional generalization, but the consistency of compositional generalization across multiple levels of novel compositions remains unexplored. The consistency refers to that a model should generalize to a phrase-phrase level novel composition, and phrase-word/word-word level novel compositions that can be derived from it simultaneously. In this paper, we propose a meta-learning based framework, for achieving consistent compositional generalization across multiple levels. The basic idea is to progressively learn compositions from simple to complex for consistency. Specifically, we divide the original training set into multiple validation sets based on compositional complexity, and introduce multiple meta-weight-nets to generate sample weights for samples in different validation sets. To fit the validation sets in order of increasing compositional complexity, we optimize the parameters of each meta-weight-net independently and sequentially in a multilevel optimization manner. We build a GQA-CCG dataset to quantitatively evaluate the consistency. Experimental results on visual question answering and temporal video grounding, demonstrate the effectiveness of the proposed framework. We release GQA-CCG at https://github.com/NeverMoreLCH/CCG.
Traffic Flow Prediction via Variational Bayesian Inference-based Encoder-Decoder Framework
Dec 14, 2022Accurate traffic flow prediction, a hotspot for intelligent transportation research, is the prerequisite for mastering traffic and making travel plans. The speed of traffic flow can be affected by roads condition, weather, holidays, etc. Furthermore, the sensors to catch the information about traffic flow will be interfered with by environmental factors such as illumination, collection time, occlusion, etc. Therefore, the traffic flow in the practical transportation system is complicated, uncertain, and challenging to predict accurately. This paper proposes a deep encoder-decoder prediction framework based on variational Bayesian inference. A Bayesian neural network is constructed by combining variational inference with gated recurrent units (GRU) and used as the deep neural network unit of the encoder-decoder framework to mine the intrinsic dynamics of traffic flow. Then, the variational inference is introduced into the multi-head attention mechanism to avoid noise-induced deterioration of prediction accuracy. The proposed model achieves superior prediction performance on the Guangzhou urban traffic flow dataset over the benchmarks, particularly when the long-term prediction.