 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
Composition-Incremental Learning for Compositional Generalization
Nov 12, 2025Compositional generalization has achieved substantial progress in computer vision on pre-collected training data. Nonetheless, real-world data continually emerges, with possible compositions being nearly infinite, long-tailed, and not entirely visible. Thus, an ideal model is supposed to gradually improve the capability of compositional generalization in an incremental manner. In this paper, we explore Composition-Incremental Learning for Compositional Generalization (CompIL) in the context of the compositional zero-shot learning (CZSL) task, where models need to continually learn new compositions, intending to improve their compositional generalization capability progressively. To quantitatively evaluate CompIL, we develop a benchmark construction pipeline leveraging existing datasets, yielding MIT-States-CompIL and C-GQA-CompIL. Furthermore, we propose a pseudo-replay framework utilizing a visual synthesizer to synthesize visual representations of learned compositions and a linguistic primitive distillation mechanism to maintain aligned primitive representations across the learning process. Extensive experiments demonstrate the effectiveness of the proposed framework.
Modality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025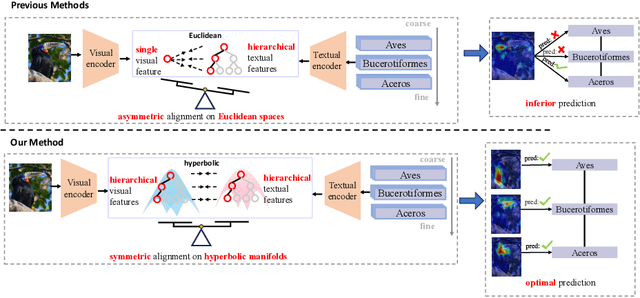
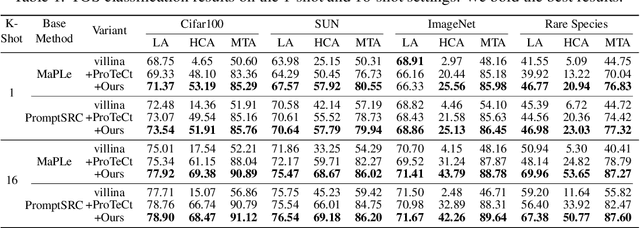
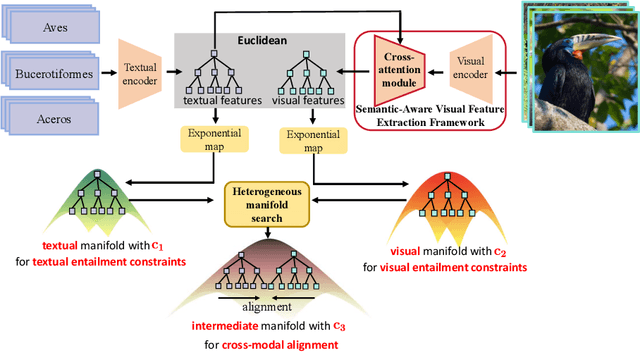

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
GUI Knowledge Bench: Revealing the Knowledge Gap Behind VLM Failures in GUI Tasks
Oct 30, 2025Large vision language models (VLMs) have advanced graphical user interface (GUI) task automation but still lag behind humans. We hypothesize this gap stems from missing core GUI knowledge, which existing training schemes (such as supervised fine tuning and reinforcement learning) alone cannot fully address. By analyzing common failure patterns in GUI task execution, we distill GUI knowledge into three dimensions: (1) interface perception, knowledge about recognizing widgets and system states; (2) interaction prediction, knowledge about reasoning action state transitions; and (3) instruction understanding, knowledge about planning, verifying, and assessing task completion progress. We further introduce GUI Knowledge Bench, a benchmark with multiple choice and yes/no questions across six platforms (Web, Android, MacOS, Windows, Linux, IOS) and 292 applications. Our evaluation shows that current VLMs identify widget functions but struggle with perceiving system states, predicting actions, and verifying task completion. Experiments on real world GUI tasks further validate the close link between GUI knowledge and task success. By providing a structured framework for assessing GUI knowledge, our work supports the selection of VLMs with greater potential prior to downstream training and provides insights for building more capable GUI agents.
Beyond the Seen: Bounded Distribution Estimation for Open-Vocabulary Learning
Oct 06, 2025



Open-vocabulary learning requires modeling the data distribution in open environments, which consists of both seen-class and unseen-class data. Existing methods estimate the distribution in open environments using seen-class data, where the absence of unseen classes makes the estimation error inherently unidentifiable. Intuitively, learning beyond the seen classes is crucial for distribution estimation to bound the estimation error. We theoretically demonstrate that the distribution can be effectively estimated by generating unseen-class data, through which the estimation error is upper-bounded. Building on this theoretical insight, we propose a novel open-vocabulary learning method, which generates unseen-class data for estimating the distribution in open environments. The method consists of a class-domain-wise data generation pipeline and a distribution alignment algorithm. The data generation pipeline generates unseen-class data under the guidance of a hierarchical semantic tree and domain information inferred from the seen-class data, facilitating accurate distribution estimation. With the generated data, the distribution alignment algorithm estimates and maximizes the posterior probability to enhance generalization in open-vocabulary learning. Extensive experiments on $11$ datasets demonstrate that our method outperforms baseline approaches by up to $14\%$, highlighting its effectiveness and superiority.
Curvature Learning for Generalization of Hyperbolic Neural Networks
Aug 24, 2025Hyperbolic neural networks (HNNs) have demonstrated notable efficacy in representing real-world data with hierarchical structures via exploiting the geometric properties of hyperbolic spaces characterized by negative curvatures. Curvature plays a crucial role in optimizing HNNs. Inappropriate curvatures may cause HNNs to converge to suboptimal parameters, degrading overall performance. So far, the theoretical foundation of the effect of curvatures on HNNs has not been developed. In this paper, we derive a PAC-Bayesian generalization bound of HNNs, highlighting the role of curvatures in the generalization of HNNs via their effect on the smoothness of the loss landscape. Driven by the derived bound, we propose a sharpness-aware curvature learning method to smooth the loss landscape, thereby improving the generalization of HNNs. In our method, we design a scope sharpness measure for curvatures, which is minimized through a bi-level optimization process. Then, we introduce an implicit differentiation algorithm that efficiently solves the bi-level optimization by approximating gradients of curvatures. We present the approximation error and convergence analyses of the proposed method, showing that the approximation error is upper-bounded, and the proposed method can converge by bounding gradients of HNNs. Experiments on four settings: classification, learning from long-tailed data, learning from noisy data, and few-shot learning show that our method can improve the performance of HNNs.
Sekai: A Video Dataset towards World Exploration
Jun 18, 2025Video generation techniques have made remarkable progress, promising to be the foundation of interactive world exploration. However, existing video generation datasets are not well-suited for world exploration training as they suffer from some limitations: limited locations, short duration, static scenes, and a lack of annotations about exploration and the world. In this paper, we introduce Sekai (meaning ``world'' in Japanese), a high-quality first-person view worldwide video dataset with rich annotations for world exploration. It consists of over 5,000 hours of walking or drone view (FPV and UVA) videos from over 100 countries and regions across 750 cities. We develop an efficient and effective toolbox to collect, pre-process and annotate videos with location, scene, weather, crowd density, captions, and camera trajectories. Experiments demonstrate the quality of the dataset. And, we use a subset to train an interactive video world exploration model, named YUME (meaning ``dream'' in Japanese). We believe Sekai will benefit the area of video generation and world exploration, and motivate valuable applications.
Hyperbolic Dual Feature Augmentation for Open-Environment
Jun 10, 2025Feature augmentation generates novel samples in the feature space, providing an effective way to enhance the generalization ability of learning algorithms with hyperbolic geometry. Most hyperbolic feature augmentation is confined to closed-environment, assuming the number of classes is fixed (\emph{i.e.}, seen classes) and generating features only for these classes. In this paper, we propose a hyperbolic dual feature augmentation method for open-environment, which augments features for both seen and unseen classes in the hyperbolic space. To obtain a more precise approximation of the real data distribution for efficient training, (1) we adopt a neural ordinary differential equation module, enhanced by meta-learning, estimating the feature distributions of both seen and unseen classes; (2) we then introduce a regularizer to preserve the latent hierarchical structures of data in the hyperbolic space; (3) we also derive an upper bound for the hyperbolic dual augmentation loss, allowing us to train a hyperbolic model using infinite augmentations for seen and unseen classes. Extensive experiments on five open-environment tasks: class-incremental learning, few-shot open-set recognition, few-shot learning, zero-shot learning, and general image classification, demonstrate that our method effectively enhances the performance of hyperbolic algorithms in open-environment.
Multi-Sourced Compositional Generalization in Visual Question Answering
May 29, 2025Compositional generalization is the ability of generalizing novel compositions from seen primitives, and has received much attention in vision-and-language (V\&L) recently. Due to the multi-modal nature of V\&L tasks, the primitives composing compositions source from different modalities, resulting in multi-sourced novel compositions. However, the generalization ability over multi-sourced novel compositions, \textit{i.e.}, multi-sourced compositional generalization (MSCG) remains unexplored. In this paper, we explore MSCG in the context of visual question answering (VQA), and propose a retrieval-augmented training framework to enhance the MSCG ability of VQA models by learning unified representations for primitives from different modalities. Specifically, semantically equivalent primitives are retrieved for each primitive in the training samples, and the retrieved features are aggregated with the original primitive to refine the model. This process helps the model learn consistent representations for the same semantic primitives across different modalities. To evaluate the MSCG ability of VQA models, we construct a new GQA-MSCG dataset based on the GQA dataset, in which samples include three types of novel compositions composed of primitives from different modalities. Experimental results demonstrate the effectiveness of the proposed framework. We release GQA-MSCG at https://github.com/NeverMoreLCH/MSCG.
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025
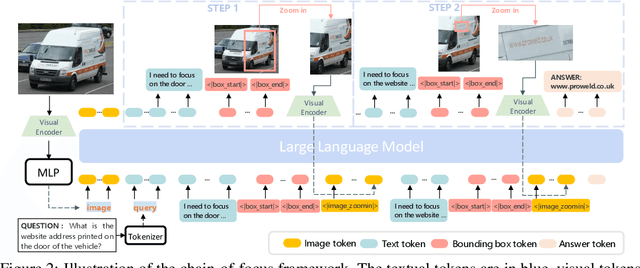


Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.