 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
CoCoPlan: Adaptive Coordination and Communication for Multi-robot Systems in Dynamic and Unknown Environments
Jan 15, 2026Multi-robot systems can greatly enhance efficiency through coordination and collaboration, yet in practice, full-time communication is rarely available and interactions are constrained to close-range exchanges. Existing methods either maintain all-time connectivity, rely on fixed schedules, or adopt pairwise protocols, but none adapt effectively to dynamic spatio-temporal task distributions under limited communication, resulting in suboptimal coordination. To address this gap, we propose CoCoPlan, a unified framework that co-optimizes collaborative task planning and team-wise intermittent communication. Our approach integrates a branch-and-bound architecture that jointly encodes task assignments and communication events, an adaptive objective function that balances task efficiency against communication latency, and a communication event optimization module that strategically determines when, where and how the global connectivity should be re-established. Extensive experiments demonstrate that it outperforms state-of-the-art methods by achieving a 22.4% higher task completion rate, reducing communication overhead by 58.6%, and improving the scalability by supporting up to 100 robots in dynamic environments. Hardware experiments include the complex 2D office environment and large-scale 3D disaster-response scenario.
SLEI3D: Simultaneous Exploration and Inspection via Heterogeneous Fleets under Limited Communication
Jan 01, 2026Robotic fleets such as unmanned aerial and ground vehicles have been widely used for routine inspections of static environments, where the areas of interest are known and planned in advance. However, in many applications, such areas of interest are unknown and should be identified online during exploration. Thus, this paper considers the problem of simultaneous exploration, inspection of unknown environments and then real-time communication to a mobile ground control station to report the findings. The heterogeneous robots are equipped with different sensors, e.g., long-range lidars for fast exploration and close-range cameras for detailed inspection. Furthermore, global communication is often unavailable in such environments, where the robots can only communicate with each other via ad-hoc wireless networks when they are in close proximity and free of obstruction. This work proposes a novel planning and coordination framework (SLEI3D) that integrates the online strategies for collaborative 3D exploration, adaptive inspection and timely communication (via the intermit-tent or proactive protocols). To account for uncertainties w.r.t. the number and location of features, a multi-layer and multi-rate planning mechanism is developed for inter-and-intra robot subgroups, to actively meet and coordinate their local plans. The proposed framework is validated extensively via high-fidelity simulations of numerous large-scale missions with up to 48 robots and 384 thousand cubic meters. Hardware experiments of 7 robots are also conducted. Project website is available at https://junfengchen-robotics.github.io/SLEI3D/.
DEXTER-LLM: Dynamic and Explainable Coordination of Multi-Robot Systems in Unknown Environments via Large Language Models
Aug 20, 2025



Online coordination of multi-robot systems in open and unknown environments faces significant challenges, particularly when semantic features detected during operation dynamically trigger new tasks. Recent large language model (LLMs)-based approaches for scene reasoning and planning primarily focus on one-shot, end-to-end solutions in known environments, lacking both dynamic adaptation capabilities for online operation and explainability in the processes of planning. To address these issues, a novel framework (DEXTER-LLM) for dynamic task planning in unknown environments, integrates four modules: (i) a mission comprehension module that resolves partial ordering of tasks specified by natural languages or linear temporal logic formulas (LTL); (ii) an online subtask generator based on LLMs that improves the accuracy and explainability of task decomposition via multi-stage reasoning; (iii) an optimal subtask assigner and scheduler that allocates subtasks to robots via search-based optimization; and (iv) a dynamic adaptation and human-in-the-loop verification module that implements multi-rate, event-based updates for both subtasks and their assignments, to cope with new features and tasks detected online. The framework effectively combines LLMs' open-world reasoning capabilities with the optimality of model-based assignment methods, simultaneously addressing the critical issue of online adaptability and explainability. Experimental evaluations demonstrate exceptional performances, with 100% success rates across all scenarios, 160 tasks and 480 subtasks completed on average (3 times the baselines), 62% less queries to LLMs during adaptation, and superior plan quality (2 times higher) for compound tasks. Project page at https://tcxm.github.io/DEXTER-LLM/
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025
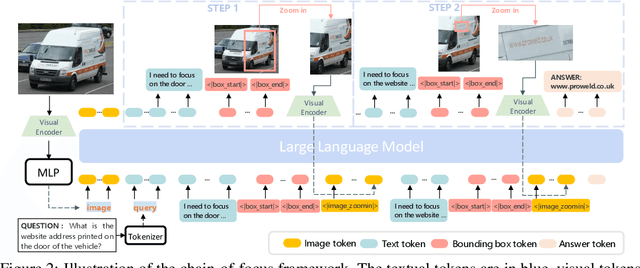


Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
On Domain-Specific Post-Training for Multimodal Large Language Models
Nov 29, 2024



Recent years have witnessed the rapid development of general multimodal large language models (MLLMs). However, adapting general MLLMs to specific domains, such as scientific fields and industrial applications, remains less explored. This paper systematically investigates domain adaptation of MLLMs through post-training, focusing on data synthesis, training pipelines, and task evaluation. (1) Data Synthesis: Using open-source models, we develop a visual instruction synthesizer that effectively generates diverse visual instruction tasks from domain-specific image-caption pairs. Our synthetic tasks surpass those generated by manual rules, GPT-4, and GPT-4V in enhancing the domain-specific performance of MLLMs. (2) Training Pipeline: While the two-stage training--initially on image-caption pairs followed by visual instruction tasks--is commonly adopted for developing general MLLMs, we apply a single-stage training pipeline to enhance task diversity for domain-specific post-training. (3) Task Evaluation: We conduct experiments in two domains, biomedicine and food, by post-training MLLMs of different sources and scales (e.g., Qwen2-VL-2B, LLaVA-v1.6-8B, Llama-3.2-11B), and then evaluating MLLM performance on various domain-specific tasks. To support further research in MLLM domain adaptation, we will open-source our implementations.
CLOVA: A Closed-Loop Visual Assistant with Tool Usage and Update
Dec 18, 2023Leveraging large language models (LLMs) to integrate off-the-shelf tools (e.g., visual models and image processing functions) is a promising research direction to build powerful visual assistants for solving diverse visual tasks. However, the learning capability is rarely explored in existing methods, as they freeze the used tools after deployment, thereby limiting the generalization to new environments requiring specific knowledge. In this paper, we propose CLOVA, a Closed-LOop Visual Assistant to address this limitation, which encompasses inference, reflection, and learning phases in a closed-loop framework. During inference, LLMs generate programs and execute corresponding tools to accomplish given tasks. The reflection phase introduces a multimodal global-local reflection scheme to analyze whether and which tool needs to be updated based on environmental feedback. Lastly, the learning phase uses three flexible manners to collect training data in real-time and introduces a novel prompt tuning scheme to update the tools, enabling CLOVA to efficiently learn specific knowledge for new environments without human involvement. Experiments show that CLOVA outperforms tool-usage methods by 5% in visual question answering and multiple-image reasoning tasks, by 10% in knowledge tagging tasks, and by 20% in image editing tasks, highlighting the significance of the learning capability for general visual assistants.
Enhance Reasoning Ability of Visual-Language Models via Large Language Models
May 22, 2023Pre-trained visual language models (VLM) have shown excellent performance in image caption tasks. However, it sometimes shows insufficient reasoning ability. In contrast, large language models (LLMs) emerge with powerful reasoning capabilities. Therefore, we propose a method called TReE, which transfers the reasoning ability of a large language model to a visual language model in zero-shot scenarios. TReE contains three stages: observation, thinking, and re-thinking. Observation stage indicates that VLM obtains the overall information of the relative image. Thinking stage combines the image information and task description as the prompt of the LLM, inference with the rationals. Re-Thinking stage learns from rationale and then inference the final result through VLM.