 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualGR: Generative Retrieval with Long and Short-Term Interests Modeling
Nov 16, 2025In large-scale industrial recommendation systems, retrieval must produce high-quality candidates from massive corpora under strict latency. Recently, Generative Retrieval (GR) has emerged as a viable alternative to Embedding-Based Retrieval (EBR), which quantizes items into a finite token space and decodes candidates autoregressively, providing a scalable path that explicitly models target-history interactions via cross-attention. However, three challenges persist: 1) how to balance users' long-term and short-term interests , 2) noise interference when generating hierarchical semantic IDs (SIDs), 3) the absence of explicit modeling for negative feedback such as exposed items without clicks. To address these challenges, we propose DualGR, a generative retrieval framework that explicitly models dual horizons of user interests with selective activation. Specifically, DualGR utilizes Dual-Branch Long/Short-Term Router (DBR) to cover both stable preferences and transient intents by explicitly modeling users' long- and short-term behaviors. Meanwhile, Search-based SID Decoding (S2D) is presented to control context-induced noise and enhance computational efficiency by constraining candidate interactions to the current coarse (level-1) bucket during fine-grained (level-2/3) SID prediction. % also reinforcing intra-class consistency. Finally, we propose an Exposure-aware Next-Token Prediction Loss (ENTP-Loss) that treats "exposed-but-unclicked" items as hard negatives at level-1, enabling timely interest fade-out. On the large-scale Kuaishou short-video recommendation system, DualGR has achieved outstanding performance. Online A/B testing shows +0.527% video views and +0.432% watch time lifts, validating DualGR as a practical and effective paradigm for industrial generative retrieval.
LEO-VL: Towards 3D Vision-Language Generalists via Data Scaling with Efficient Representation
Jun 11, 2025



Developing 3D-VL generalists capable of understanding 3D scenes and following natural language instructions to perform a wide range of tasks has been a long-standing goal in the 3D-VL community. Despite recent progress, 3D-VL models still lag behind their 2D counterparts in capability and robustness, falling short of the generalist standard. A key obstacle to developing 3D-VL generalists lies in data scalability, hindered by the lack of an efficient scene representation. We propose LEO-VL, a 3D-VL model built upon condensed feature grid (CFG), an efficient scene representation that bridges 2D perception and 3D spatial structure while significantly reducing token overhead. This efficiency unlocks large-scale training towards 3D-VL generalist, for which we curate over 700k high-quality 3D-VL data spanning four domains of real-world indoor scenes and five tasks such as captioning and dialogue. LEO-VL achieves state-of-the-art performance on a variety of 3D QA benchmarks, including SQA3D, MSQA, and Beacon3D. Ablation studies confirm the efficiency of our representation, the importance of task and scene diversity, and the validity of our data curation principle. Furthermore, we introduce SceneDPO, a novel post-training objective that enhances the robustness of 3D-VL models. We hope our findings contribute to the advancement of scalable and robust 3D-VL generalists.
From Objects to Anywhere: A Holistic Benchmark for Multi-level Visual Grounding in 3D Scenes
Jun 05, 2025
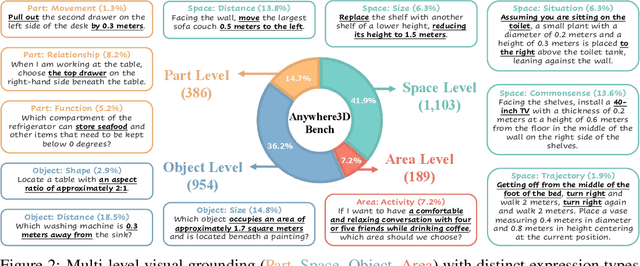

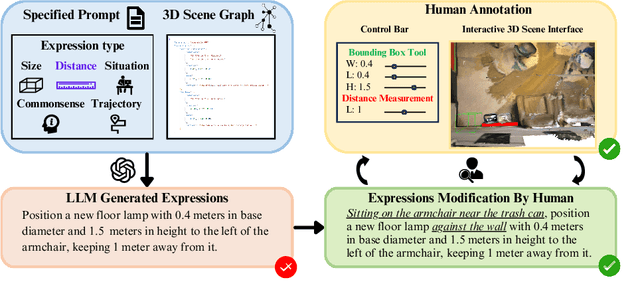
3D visual grounding has made notable progress in localizing objects within complex 3D scenes. However, grounding referring expressions beyond objects in 3D scenes remains unexplored. In this paper, we introduce Anywhere3D-Bench, a holistic 3D visual grounding benchmark consisting of 2,632 referring expression-3D bounding box pairs spanning four different grounding levels: human-activity areas, unoccupied space beyond objects, objects in the scene, and fine-grained object parts. We assess a range of state-of-the-art 3D visual grounding methods alongside large language models (LLMs) and multimodal LLMs (MLLMs) on Anywhere3D-Bench. Experimental results reveal that space-level and part-level visual grounding pose the greatest challenges: space-level tasks require a more comprehensive spatial reasoning ability, for example, modeling distances and spatial relations within 3D space, while part-level tasks demand fine-grained perception of object composition. Even the best performance model, OpenAI o4-mini, achieves only 23.57% accuracy on space-level tasks and 33.94% on part-level tasks, significantly lower than its performance on area-level and object-level tasks. These findings underscore a critical gap in current models' capacity to understand and reason about 3D scene beyond object-level semantics.
FlowDreamer: A RGB-D World Model with Flow-based Motion Representations for Robot Manipulation
May 15, 2025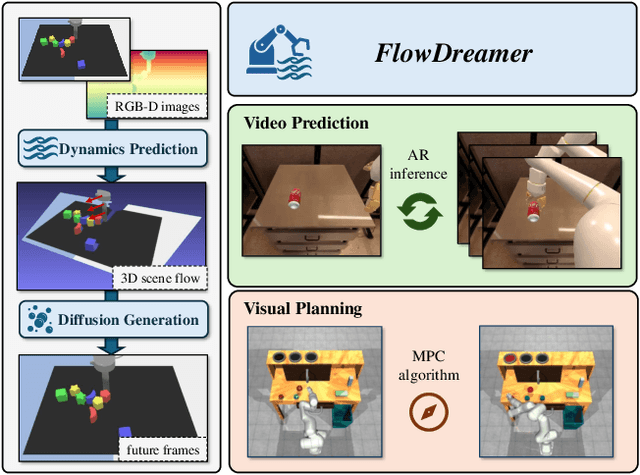

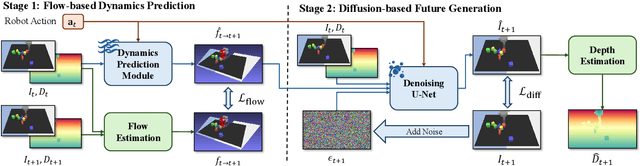

This paper investigates training better visual world models for robot manipulation, i.e., models that can predict future visual observations by conditioning on past frames and robot actions. Specifically, we consider world models that operate on RGB-D frames (RGB-D world models). As opposed to canonical approaches that handle dynamics prediction mostly implicitly and reconcile it with visual rendering in a single model, we introduce FlowDreamer, which adopts 3D scene flow as explicit motion representations. FlowDreamer first predicts 3D scene flow from past frame and action conditions with a U-Net, and then a diffusion model will predict the future frame utilizing the scene flow. FlowDreamer is trained end-to-end despite its modularized nature. We conduct experiments on 4 different benchmarks, covering both video prediction and visual planning tasks. The results demonstrate that FlowDreamer achieves better performance compared to other baseline RGB-D world models by 7% on semantic similarity, 11% on pixel quality, and 6% on success rate in various robot manipulation domains.
Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning
May 06, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
Iterative Trajectory Exploration for Multimodal Agents
Apr 30, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.
Building LLM Agents by Incorporating Insights from Computer Systems
Apr 06, 2025LLM-driven autonomous agents have emerged as a promising direction in recent years. However, many of these LLM agents are designed empirically or based on intuition, often lacking systematic design principles, which results in diverse agent structures with limited generality and scalability. In this paper, we advocate for building LLM agents by incorporating insights from computer systems. Inspired by the von Neumann architecture, we propose a structured framework for LLM agentic systems, emphasizing modular design and universal principles. Specifically, this paper first provides a comprehensive review of LLM agents from the computer system perspective, then identifies key challenges and future directions inspired by computer system design, and finally explores the learning mechanisms for LLM agents beyond the computer system. The insights gained from this comparative analysis offer a foundation for systematic LLM agent design and advancement.
JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse
Mar 20, 2025



Recently, action-based decision-making in open-world environments has gained significant attention. Visual Language Action (VLA) models, pretrained on large-scale web datasets, have shown promise in decision-making tasks. However, previous work has primarily focused on action post-training, often neglecting enhancements to the foundational model itself. In response, we introduce a novel approach, Act from Visual Language Post-Training, which refines Visual Language Models (VLMs) through visual and linguistic guidance in a self-supervised manner. This enhancement improves the models' capabilities in world knowledge, visual recognition, and spatial grounding in open-world environments. Following the above post-training paradigms, we obtain the first VLA models in Minecraft that can follow human instructions on over 1k different atomic tasks, including crafting, smelting, cooking, mining, and killing. Our experiments demonstrate that post-training on non-trajectory tasks leads to a significant 40% improvement over the best agent baseline on a diverse set of atomic tasks. Furthermore, we demonstrate that our approach surpasses traditional imitation learning-based policies in Minecraft, achieving state-of-the-art performance. We have open-sourced the code, models, and datasets to foster further research. The project page can be found in https://craftjarvis.github.io/JarvisVLA.
LongViTU: Instruction Tuning for Long-Form Video Understanding
Jan 09, 2025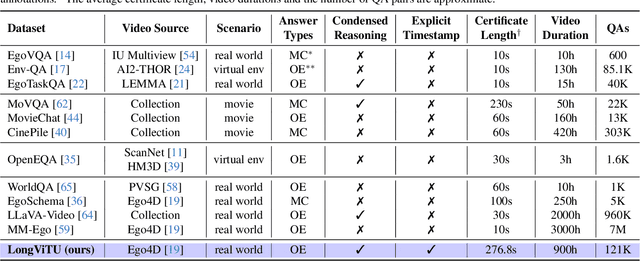
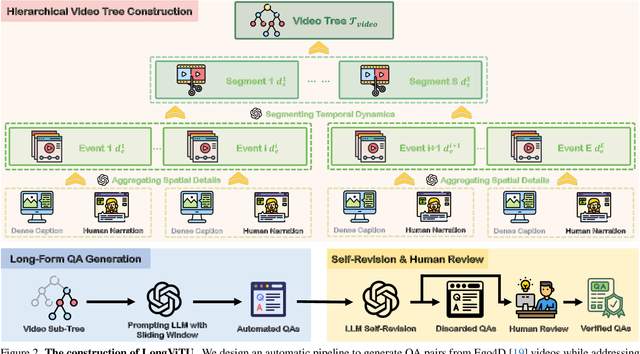
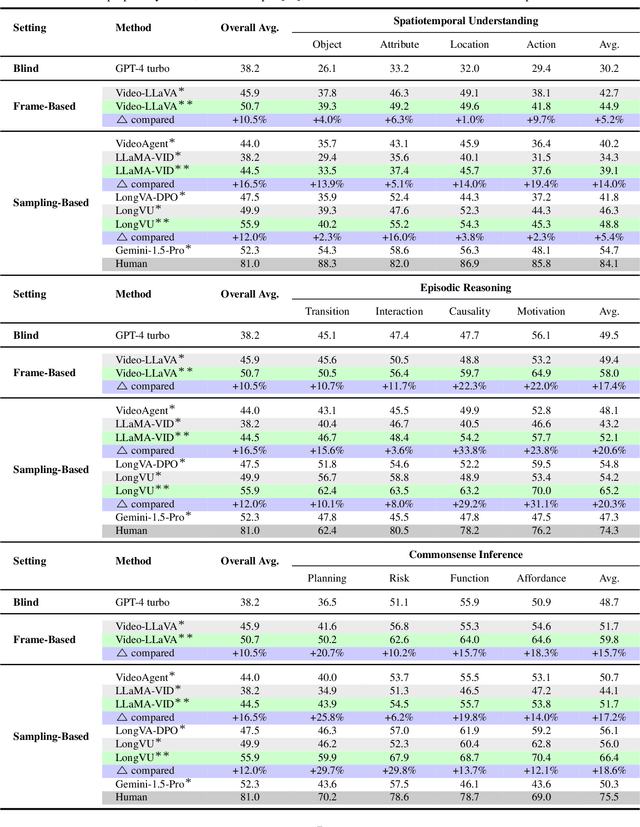
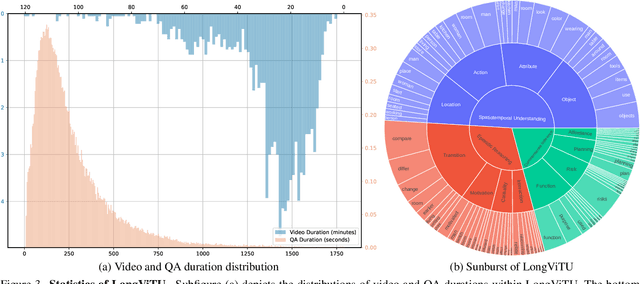
This paper introduce LongViTU, a large-scale (~121k QA pairs, ~900h videos), automatically generated dataset for long-form video understanding. We developed a systematic approach that organizes videos into a hierarchical tree structure and incorporates self-revision mechanisms to ensure high-quality QA pairs. Each QA pair in LongViTU features: 1) long-term context (average certificate length of 4.6 minutes); 2) rich knowledge and condensed reasoning (commonsense, causality, planning, etc.); and 3) explicit timestamp labels for relevant events. LongViTU also serves as a benchmark for instruction following in long-form and streaming video understanding. We evaluate the open-source state-of-the-art long video understanding model, LongVU, and the commercial model, Gemini-1.5-Pro, on our benchmark. They achieve GPT-4 scores of 49.9 and 52.3, respectively, underscoring the substantial challenge posed by our benchmark. Further supervised fine-tuning (SFT) on LongVU led to performance improvements of 12.0% on our benchmark, 2.2% on the in-distribution (ID) benchmark EgoSchema, 1.0%, 2.2% and 1.2% on the out-of-distribution (OOD) benchmarks VideoMME (Long), WorldQA and OpenEQA, respectively. These outcomes demonstrate LongViTU's high data quality and robust OOD generalizability.