 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookahead Path Likelihood Optimization for Diffusion LLMs
Feb 03, 2026Diffusion Large Language Models (dLLMs) support arbitrary-order generation, yet their inference performance critically depends on the unmasking order. Existing strategies rely on heuristics that greedily optimize local confidence, offering limited guidance for identifying unmasking paths that are globally consistent and accurate. To bridge this gap, we introduce path log-likelihood (Path LL), a trajectory-conditioned objective that strongly correlates with downstream accuracy and enables principled selection of unmasking paths. To optimize Path LL at inference time, we propose POKE, an efficient value estimator that predicts the expected future Path LL of a partial decoding trajectory. We then integrate this lookahead signal into POKE-SMC, a Sequential Monte Carlo-based search framework for dynamically identifying optimal unmasking paths. Extensive experiments across 6 reasoning tasks show that POKE-SMC consistently improves accuracy, achieving 2%--3% average gains over strong decoding-time scaling baselines at comparable inference overhead on LLaDA models and advancing the accuracy--compute Pareto frontier.
Agentic AI for Integrated Sensing and Communication: Analysis, Framework, and Case Study
Dec 17, 2025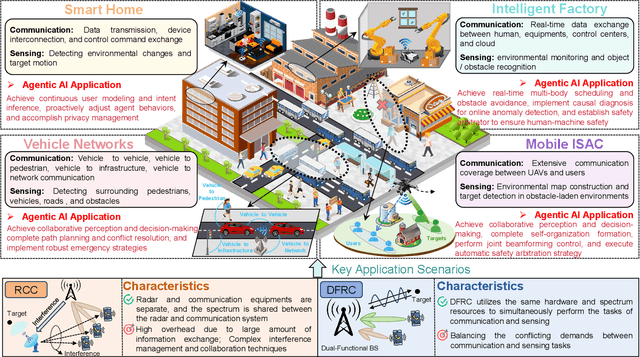
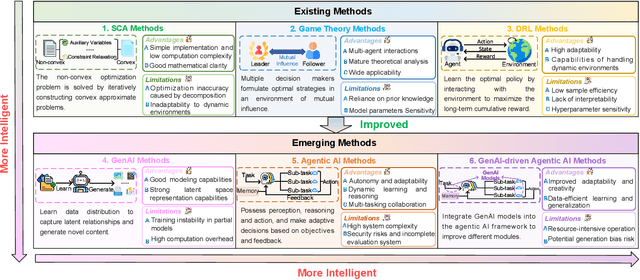
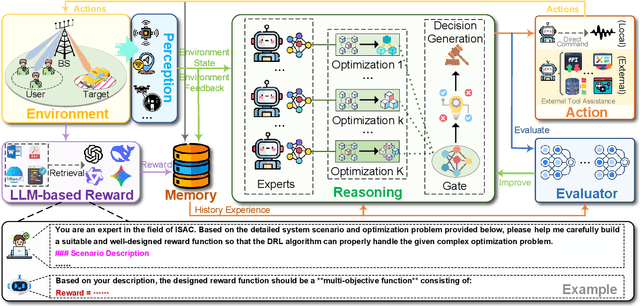
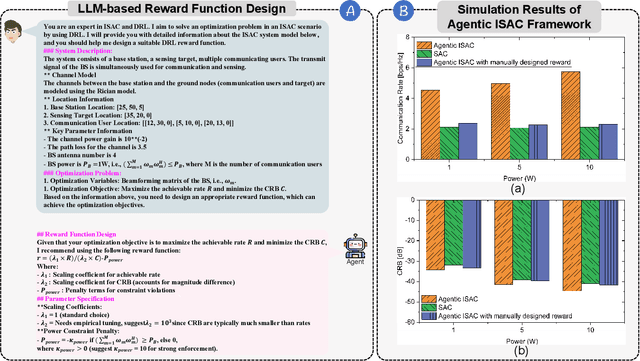
Integrated sensing and communication (ISAC) has emerged as a key development direction in the sixth-generation (6G) era, which provides essential support for the collaborative sensing and communication of future intelligent networks. However, as wireless environments become increasingly dynamic and complex, ISAC systems require more intelligent processing and more autonomous operation to maintain efficiency and adaptability. Meanwhile, agentic artificial intelligence (AI) offers a feasible solution to address these challenges by enabling continuous perception-reasoning-action loops in dynamic environments to support intelligent, autonomous, and efficient operation for ISAC systems. As such, we delve into the application value and prospects of agentic AI in ISAC systems in this work. Firstly, we provide a comprehensive review of agentic AI and ISAC systems to demonstrate their key characteristics. Secondly, we show several common optimization approaches for ISAC systems and highlight the significant advantages of generative artificial intelligence (GenAI)-based agentic AI. Thirdly, we propose a novel agentic ISAC framework and prensent a case study to verify its superiority in optimizing ISAC performance. Finally, we clarify future research directions for agentic AI-based ISAC systems.
Energy Efficient Trajectory Control and Resource Allocation in Multi-UAV-assisted MEC via Deep Reinforcement Learning
Aug 01, 2025Mobile edge computing (MEC) is a promising technique to improve the computational capacity of smart devices (SDs) in Internet of Things (IoT). However, the performance of MEC is restricted due to its fixed location and limited service scope. Hence, we investigate an unmanned aerial vehicle (UAV)-assisted MEC system, where multiple UAVs are dispatched and each UAV can simultaneously provide computing service for multiple SDs. To improve the performance of system, we formulated a UAV-based trajectory control and resource allocation multi-objective optimization problem (TCRAMOP) to simultaneously maximize the offloading number of UAVs and minimize total offloading delay and total energy consumption of UAVs by optimizing the flight paths of UAVs as well as the computing resource allocated to served SDs. Then, consider that the solution of TCRAMOP requires continuous decision-making and the system is dynamic, we propose an enhanced deep reinforcement learning (DRL) algorithm, namely, distributed proximal policy optimization with imitation learning (DPPOIL). This algorithm incorporates the generative adversarial imitation learning technique to improve the policy performance. Simulation results demonstrate the effectiveness of our proposed DPPOIL and prove that the learned strategy of DPPOIL is better compared with other baseline methods.
Plug-and-Play Context Feature Reuse for Efficient Masked Generation
May 25, 2025Masked generative models (MGMs) have emerged as a powerful framework for image synthesis, combining parallel decoding with strong bidirectional context modeling. However, generating high-quality samples typically requires many iterative decoding steps, resulting in high inference costs. A straightforward way to speed up generation is by decoding more tokens in each step, thereby reducing the total number of steps. However, when many tokens are decoded simultaneously, the model can only estimate the univariate marginal distributions independently, failing to capture the dependency among them. As a result, reducing the number of steps significantly compromises generation fidelity. In this work, we introduce ReCAP (Reused Context-Aware Prediction), a plug-and-play module that accelerates inference in MGMs by constructing low-cost steps via reusing feature embeddings from previously decoded context tokens. ReCAP interleaves standard full evaluations with lightweight steps that cache and reuse context features, substantially reducing computation while preserving the benefits of fine-grained, iterative generation. We demonstrate its effectiveness on top of three representative MGMs (MaskGIT, MAGE, and MAR), including both discrete and continuous token spaces and covering diverse architectural designs. In particular, on ImageNet256 class-conditional generation, ReCAP achieves up to 2.4x faster inference than the base model with minimal performance drop, and consistently delivers better efficiency-fidelity trade-offs under various generation settings.
Tractable Transformers for Flexible Conditional Generation
Feb 11, 2025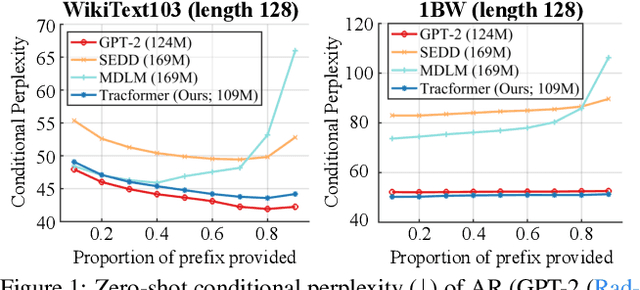
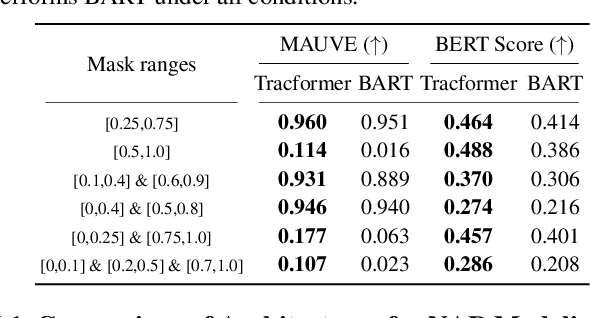

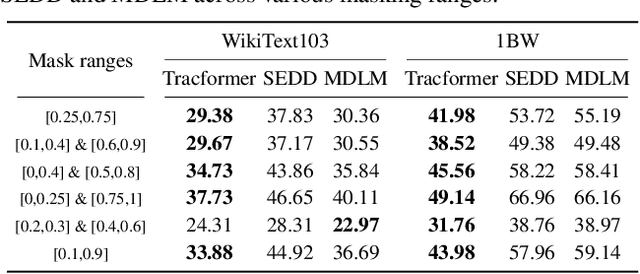
Non-autoregressive (NAR) generative models are valuable because they can handle diverse conditional generation tasks in a more principled way than their autoregressive (AR) counterparts, which are constrained by sequential dependency requirements. Recent advancements in NAR models, such as diffusion language models, have demonstrated superior performance in unconditional generation compared to AR models (e.g., GPTs) of similar sizes. However, such improvements do not always lead to improved conditional generation performance. We show that a key reason for this gap is the difficulty in generalizing to conditional probability queries unseen during training. As a result, strong unconditional generation performance does not guarantee high-quality conditional generation. This paper proposes Tractable Transformers (Tracformer), a Transformer-based generative model that is more robust to different conditional generation tasks. Unlike existing models that rely solely on global contextual features derived from full inputs, Tracformers incorporate a sparse Transformer encoder to capture both local and global contextual information. This information is routed through a decoder for conditional generation. Empirical results demonstrate that Tracformers achieve state-of-the-art conditional generation performance on text modeling compared to recent diffusion and AR model baselines.
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
Jun 27, 2024



We present OmniJARVIS, a novel Vision-Language-Action (VLA) model for open-world instruction-following agents in open-world Minecraft. Compared to prior works that either emit textual goals to separate controllers or produce the control command directly, OmniJARVIS seeks a different path to ensure both strong reasoning and efficient decision-making capabilities via unified tokenization of multimodal interaction data. First, we introduce a self-supervised approach to learn a behavior encoder that produces discretized tokens for behavior trajectories $\tau$ = {$o_0$, $a_0$, $\dots$} and an imitation learning (IL) policy decoder conditioned on these tokens. These additional behavior tokens will be augmented to the vocabulary of pretrained Multimodal Language Models (MLMs). With this encoder, we then pack long-term multimodal interactions involving task instructions, memories, thoughts, observations, textual responses, behavior trajectories, etc. into unified token sequences and model them with autoregressive transformers. Thanks to the semantically meaningful behavior tokens, the resulting VLA model, OmniJARVIS, can reason (by producing chain-of-thoughts), plan, answer questions, and act (by producing behavior tokens for the IL policy decoder). OmniJARVIS demonstrates excellent performances on a comprehensive collection of atomic, programmatic, and open-ended tasks in open-world Minecraft. Our analysis further unveils the crucial design principles in interaction data formation, unified tokenization, and its scaling potentials.
Expressive Modeling Is Insufficient for Offline RL: A Tractable Inference Perspective
Oct 31, 2023A popular paradigm for offline Reinforcement Learning (RL) tasks is to first fit the offline trajectories to a sequence model, and then prompt the model for actions that lead to high expected return. While a common consensus is that more expressive sequence models imply better performance, this paper highlights that tractability, the ability to exactly and efficiently answer various probabilistic queries, plays an equally important role. Specifically, due to the fundamental stochasticity from the offline data-collection policies and the environment dynamics, highly non-trivial conditional/constrained generation is required to elicit rewarding actions. While it is still possible to approximate such queries, we observe that such crude estimates significantly undermine the benefits brought by expressive sequence models. To overcome this problem, this paper proposes Trifle (Tractable Inference for Offline RL), which leverages modern Tractable Probabilistic Models (TPMs) to bridge the gap between good sequence models and high expected returns at evaluation time. Empirically, Trifle achieves the most state-of-the-art scores in 9 Gym-MuJoCo benchmarks against strong baselines. Further, owing to its tractability, Trifle significantly outperforms prior approaches in stochastic environments and safe RL tasks (e.g. with action constraints) with minimum algorithmic modifications.
Understanding the Distillation Process from Deep Generative Models to Tractable Probabilistic Circuits
Feb 16, 2023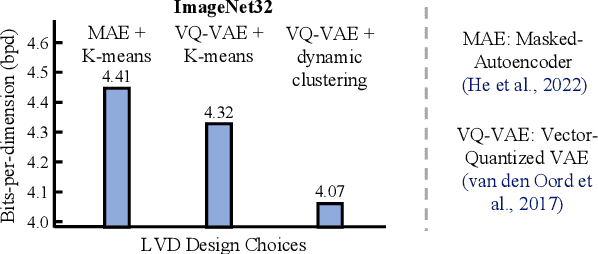
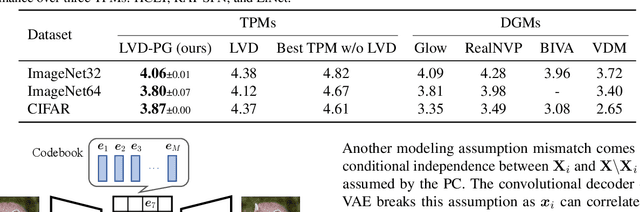
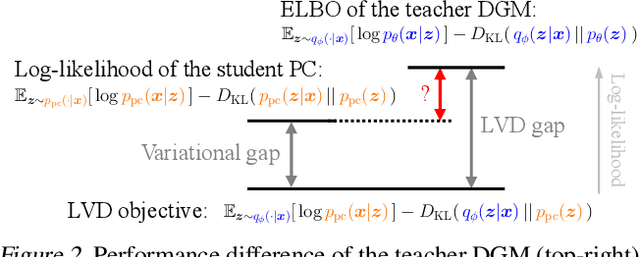
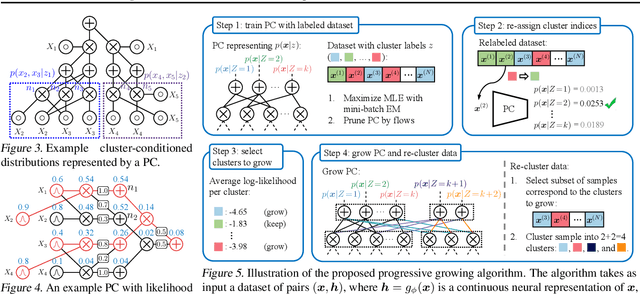
Probabilistic Circuits (PCs) are a general and unified computational framework for tractable probabilistic models that support efficient computation of various inference tasks (e.g., computing marginal probabilities). Towards enabling such reasoning capabilities in complex real-world tasks, Liu et al. (2022) propose to distill knowledge (through latent variable assignments) from less tractable but more expressive deep generative models. However, it is still unclear what factors make this distillation work well. In this paper, we theoretically and empirically discover that the performance of a PC can exceed that of its teacher model. Therefore, instead of performing distillation from the most expressive deep generative model, we study what properties the teacher model and the PC should have in order to achieve good distillation performance. This leads to a generic algorithmic improvement as well as other data-type-specific ones over the existing latent variable distillation pipeline. Empirically, we outperform SoTA TPMs by a large margin on challenging image modeling benchmarks. In particular, on ImageNet32, PCs achieve 4.06 bits-per-dimension, which is only 0.34 behind variational diffusion models (Kingma et al., 2021).
Sparse Coding with Earth Mover's Distance for Multi-Instance Histogram Representation
Mar 14, 2016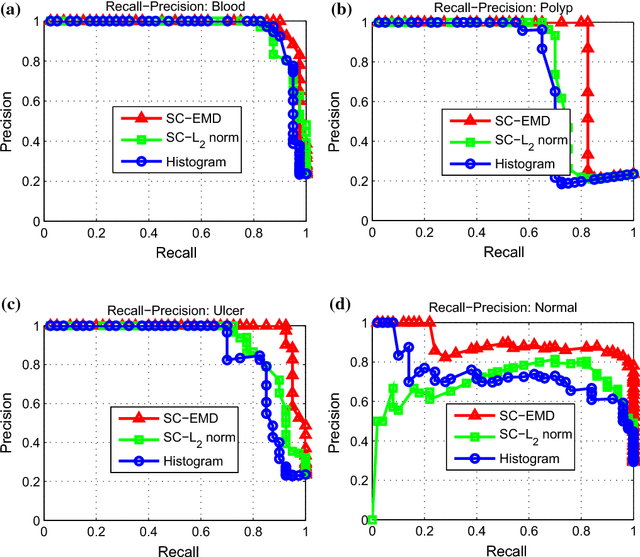
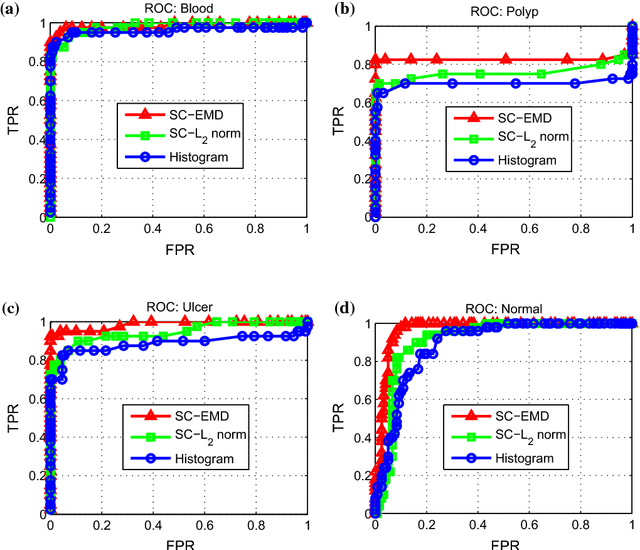
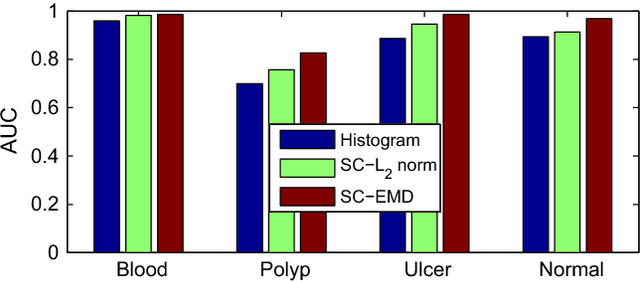
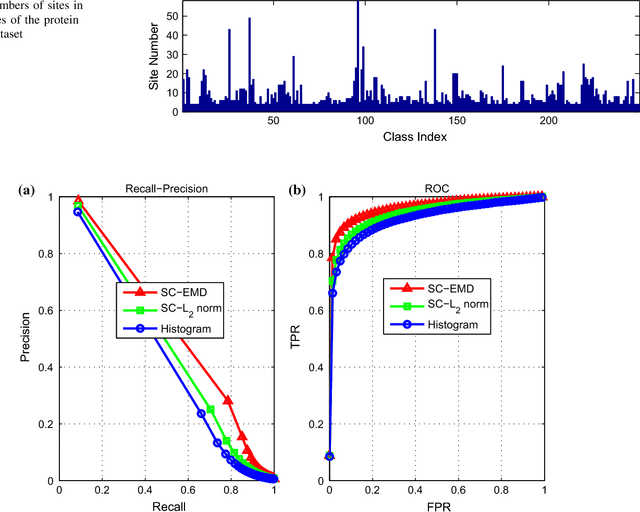
Sparse coding (Sc) has been studied very well as a powerful data representation method. It attempts to represent the feature vector of a data sample by reconstructing it as the sparse linear combination of some basic elements, and a $L_2$ norm distance function is usually used as the loss function for the reconstruction error. In this paper, we investigate using Sc as the representation method within multi-instance learning framework, where a sample is given as a bag of instances, and further represented as a histogram of the quantized instances. We argue that for the data type of histogram, using $L_2$ norm distance is not suitable, and propose to use the earth mover's distance (EMD) instead of $L_2$ norm distance as a measure of the reconstruction error. By minimizing the EMD between the histogram of a sample and the its reconstruction from some basic histograms, a novel sparse coding method is developed, which is refereed as SC-EMD. We evaluate its performances as a histogram representation method in tow multi-instance learning problems --- abnormal image detection in wireless capsule endoscopy videos, and protein binding site retrieval. The encouraging results demonstrate the advantages of the new method over the traditional method using $L_2$ norm distance.
Supervised learning of sparse context reconstruction coefficients for data representation and classification
Aug 18, 2015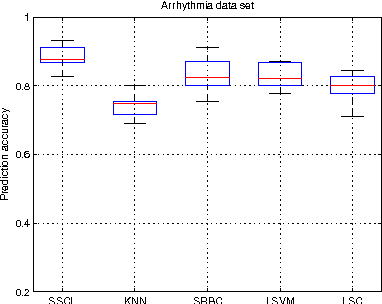
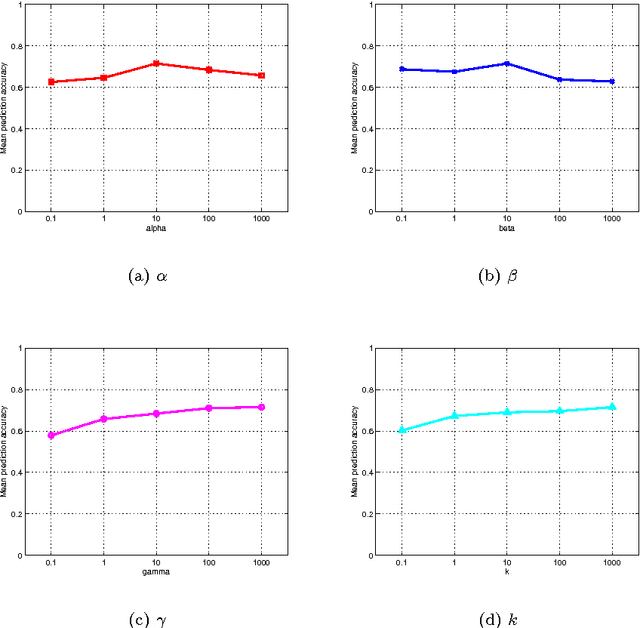
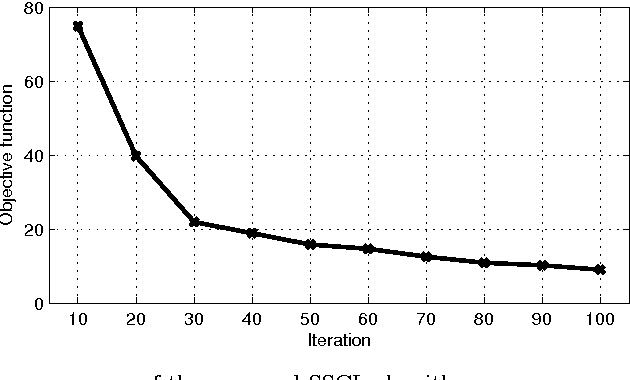
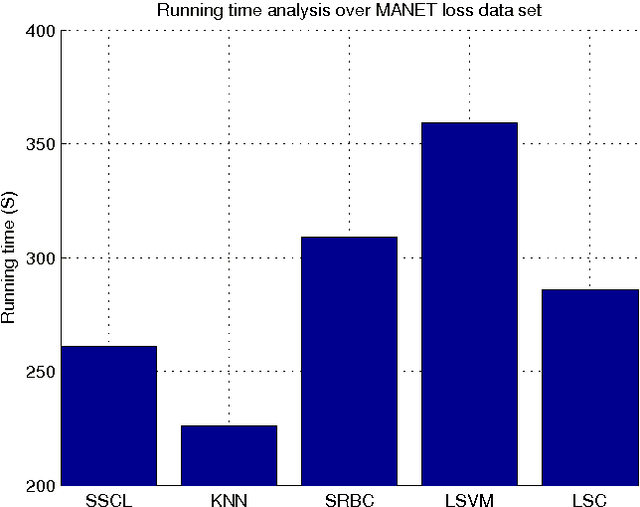
Context of data points, which is usually defined as the other data points in a data set, has been found to play important roles in data representation and classification. In this paper, we study the problem of using context of a data point for its classification problem. Our work is inspired by the observation that actually only very few data points are critical in the context of a data point for its representation and classification. We propose to represent a data point as the sparse linear combination of its context, and learn the sparse context in a supervised way to increase its discriminative ability. To this end, we proposed a novel formulation for context learning, by modeling the learning of context parameter and classifier in a unified objective, and optimizing it with an alternative strategy in an iterative algorithm. Experiments on three benchmark data set show its advantage over state-of-the-art context-based data representation and classification methods.