 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised learning of sparse context reconstruction coefficients for data representation and classification
Paper and Code
Aug 18, 2015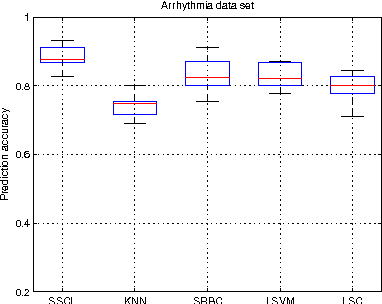
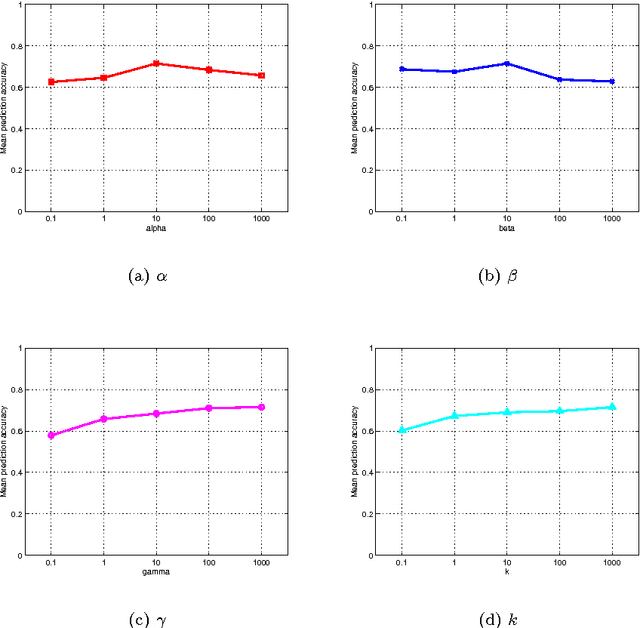
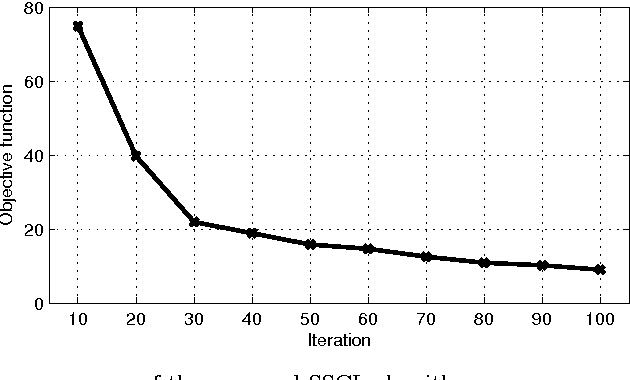
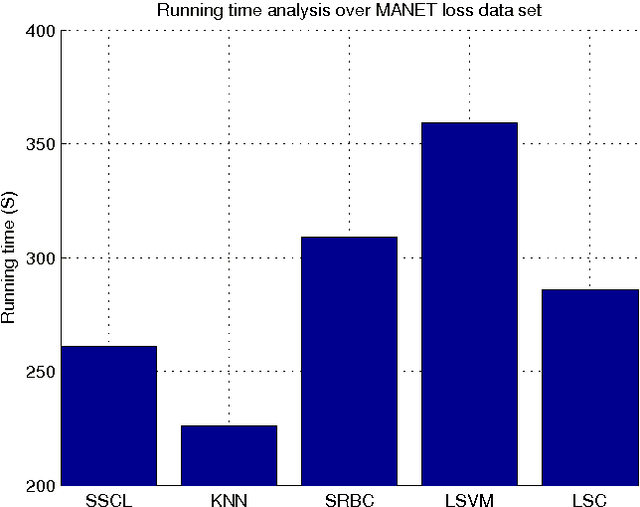
Context of data points, which is usually defined as the other data points in a data set, has been found to play important roles in data representation and classification. In this paper, we study the problem of using context of a data point for its classification problem. Our work is inspired by the observation that actually only very few data points are critical in the context of a data point for its representation and classification. We propose to represent a data point as the sparse linear combination of its context, and learn the sparse context in a supervised way to increase its discriminative ability. To this end, we proposed a novel formulation for context learning, by modeling the learning of context parameter and classifier in a unified objective, and optimizing it with an alternative strategy in an iterative algorithm. Experiments on three benchmark data set show its advantage over state-of-the-art context-based data representation and classification methods.