 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel image tag completion method based on convolutional neural network
Jun 03, 2017
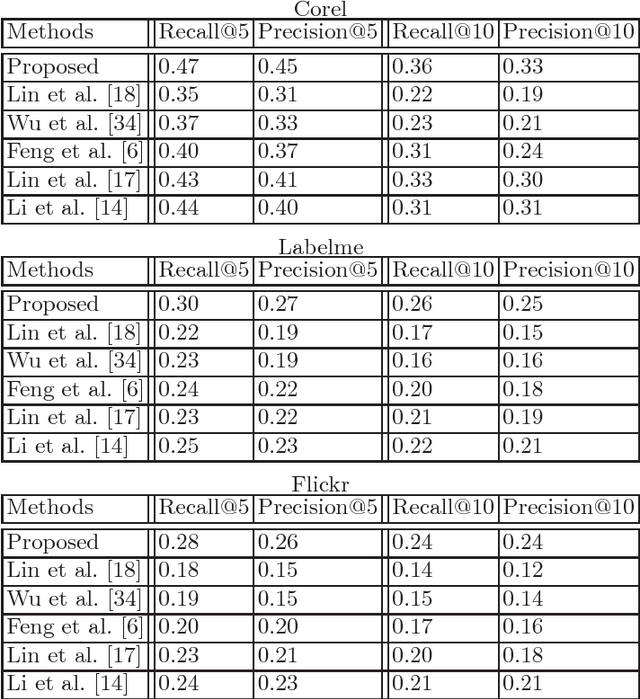

In the problems of image retrieval and annotation, complete textual tag lists of images play critical roles. However, in real-world applications, the image tags are usually incomplete, thus it is important to learn the complete tags for images. In this paper, we study the problem of image tag complete and proposed a novel method for this problem based on a popular image representation method, convolutional neural network (CNN). The method estimates the complete tags from the convolutional filtering outputs of images based on a linear predictor. The CNN parameters, linear predictor, and the complete tags are learned jointly by our method. We build a minimization problem to encourage the consistency between the complete tags and the available incomplete tags, reduce the estimation error, and reduce the model complexity. An iterative algorithm is developed to solve the minimization problem. Experiments over benchmark image data sets show its effectiveness.
Learning convolutional neural network to maximize Pos@Top performance measure
Mar 01, 2017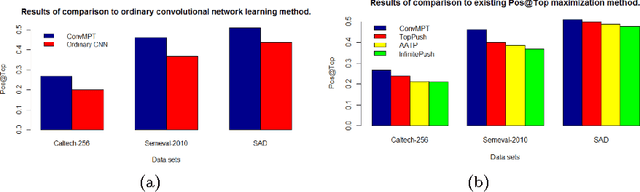
In the machine learning problems, the performance measure is used to evaluate the machine learning models. Recently, the number positive data points ranked at the top positions (Pos@Top) has been a popular performance measure in the machine learning community. In this paper, we propose to learn a convolutional neural network (CNN) model to maximize the Pos@Top performance measure. The CNN model is used to represent the multi-instance data point, and a classifier function is used to predict the label from the its CNN representation. We propose to minimize the loss function of Pos@Top over a training set to learn the filters of CNN and the classifier parameter. The classifier parameter vector is solved by the Lagrange multiplier method, and the filters are updated by the gradient descent method alternately in an iterative algorithm. Experiments over benchmark data sets show that the proposed method outperforms the state-of-the-art Pos@Top maximization methods.
Semi-supervised structured output prediction by local linear regression and sub-gradient descent
Aug 16, 2016

We propose a novel semi-supervised structured output prediction method based on local linear regression in this paper. The existing semi-supervise structured output prediction methods learn a global predictor for all the data points in a data set, which ignores the differences of local distributions of the data set, and the effects to the structured output prediction. To solve this problem, we propose to learn the missing structured outputs and local predictors for neighborhoods of different data points jointly. Using the local linear regression strategy, in the neighborhood of each data point, we propose to learn a local linear predictor by minimizing both the complexity of the predictor and the upper bound of the structured prediction loss. The minimization problem is solved by sub-gradient descent algorithms. We conduct experiments over two benchmark data sets, and the results show the advantages of the proposed method.
Multiple kernel multivariate performance learning using cutting plane algorithm
Aug 25, 2015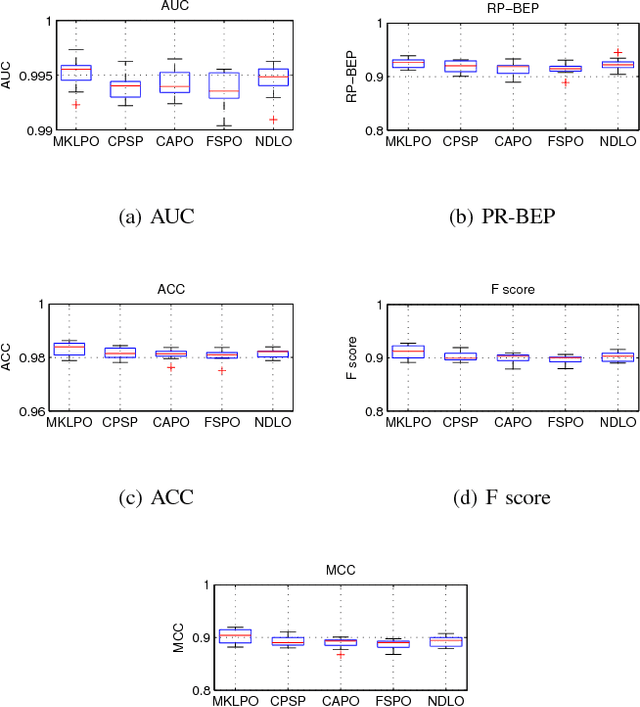
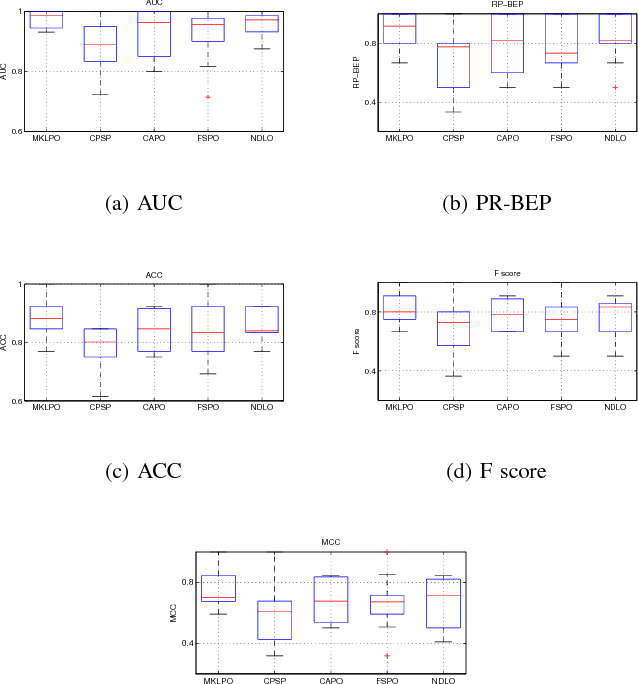
In this paper, we propose a multi-kernel classifier learning algorithm to optimize a given nonlinear and nonsmoonth multivariate classifier performance measure. Moreover, to solve the problem of kernel function selection and kernel parameter tuning, we proposed to construct an optimal kernel by weighted linear combination of some candidate kernels. The learning of the classifier parameter and the kernel weight are unified in a single objective function considering to minimize the upper boundary of the given multivariate performance measure. The objective function is optimized with regard to classifier parameter and kernel weight alternately in an iterative algorithm by using cutting plane algorithm. The developed algorithm is evaluated on two different pattern classification methods with regard to various multivariate performance measure optimization problems. The experiment results show the proposed algorithm outperforms the competing methods.
Supervised learning of sparse context reconstruction coefficients for data representation and classification
Aug 18, 2015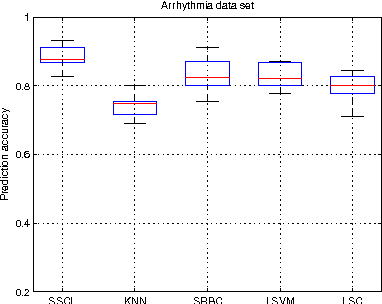
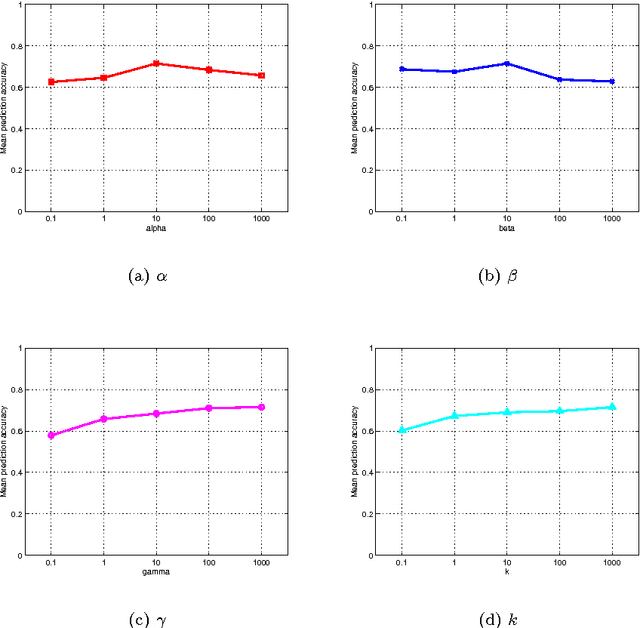
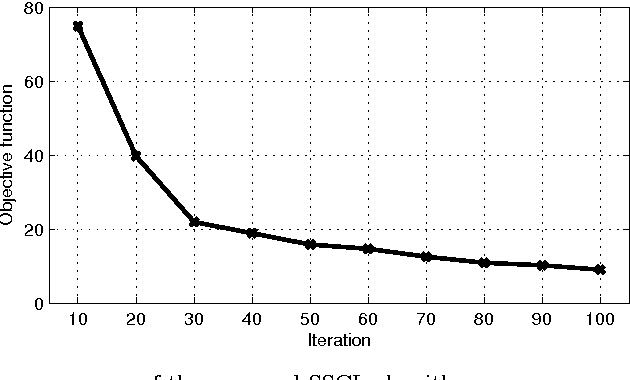
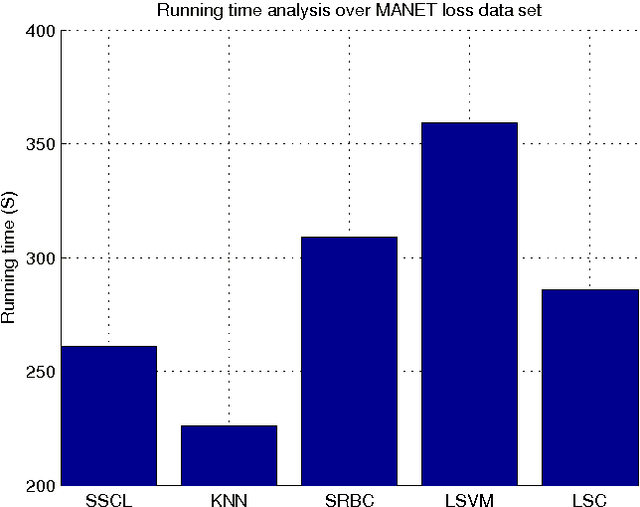
Context of data points, which is usually defined as the other data points in a data set, has been found to play important roles in data representation and classification. In this paper, we study the problem of using context of a data point for its classification problem. Our work is inspired by the observation that actually only very few data points are critical in the context of a data point for its representation and classification. We propose to represent a data point as the sparse linear combination of its context, and learn the sparse context in a supervised way to increase its discriminative ability. To this end, we proposed a novel formulation for context learning, by modeling the learning of context parameter and classifier in a unified objective, and optimizing it with an alternative strategy in an iterative algorithm. Experiments on three benchmark data set show its advantage over state-of-the-art context-based data representation and classification methods.
Supervised cross-modal factor analysis for multiple modal data classification
Aug 18, 2015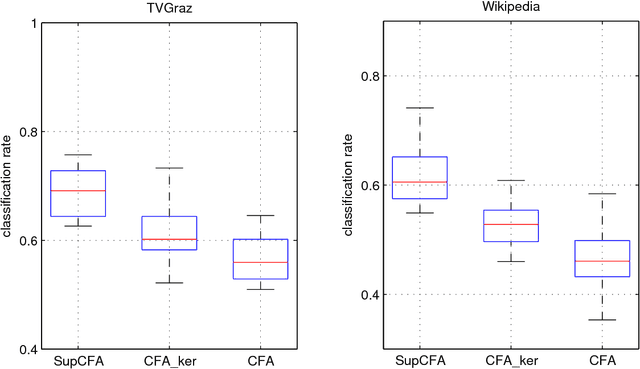
In this paper we study the problem of learning from multiple modal data for purpose of document classification. In this problem, each document is composed two different modals of data, i.e., an image and a text. Cross-modal factor analysis (CFA) has been proposed to project the two different modals of data to a shared data space, so that the classification of a image or a text can be performed directly in this space. A disadvantage of CFA is that it has ignored the supervision information. In this paper, we improve CFA by incorporating the supervision information to represent and classify both image and text modals of documents. We project both image and text data to a shared data space by factor analysis, and then train a class label predictor in the shared space to use the class label information. The factor analysis parameter and the predictor parameter are learned jointly by solving one single objective function. With this objective function, we minimize the distance between the projections of image and text of the same document, and the classification error of the projection measured by hinge loss function. The objective function is optimized by an alternate optimization strategy in an iterative algorithm. Experiments in two different multiple modal document data sets show the advantage of the proposed algorithm over other CFA methods.
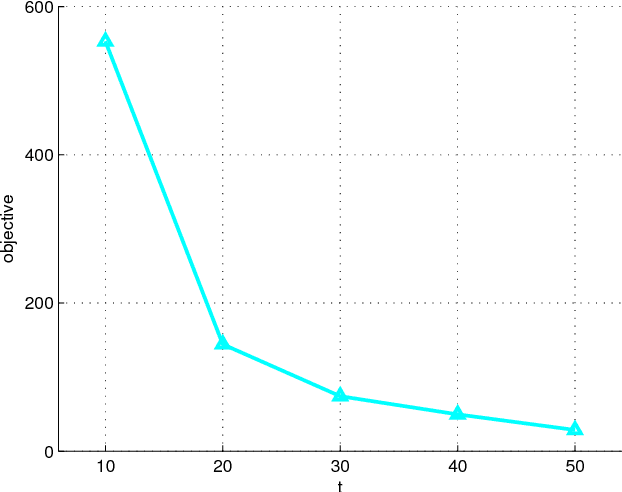
Vector Quantization by Minimizing Kullback-Leibler Divergence
Jan 30, 2015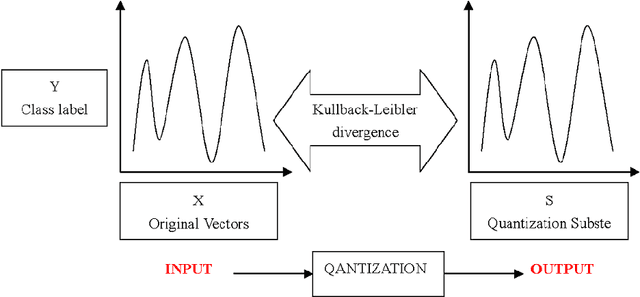
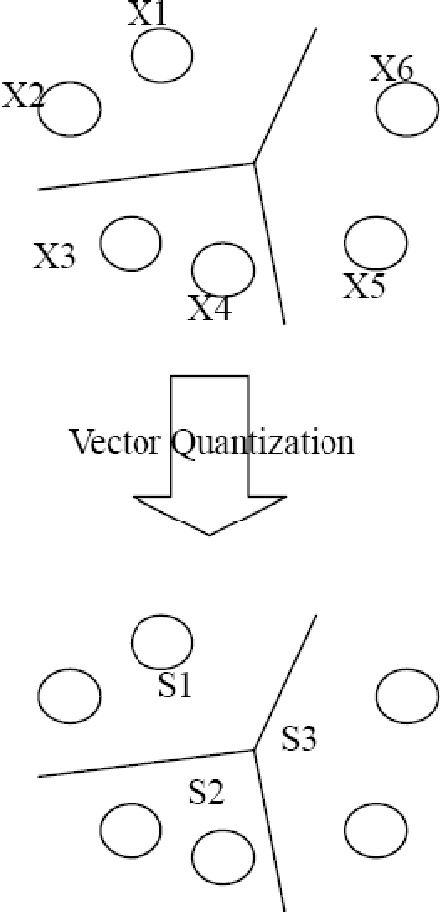

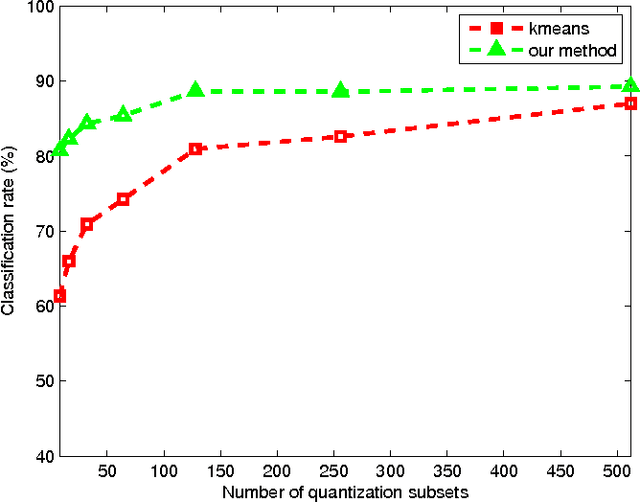
This paper proposes a new method for vector quantization by minimizing the Kullback-Leibler Divergence between the class label distributions over the quantization inputs, which are original vectors, and the output, which is the quantization subsets of the vector set. In this way, the vector quantization output can keep as much information of the class label as possible. An objective function is constructed and we also developed an iterative algorithm to minimize it. The new method is evaluated on bag-of-features based image classification problem.