 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Deep Convolutional Neural Network for Multi-Task Learning
Apr 12, 2019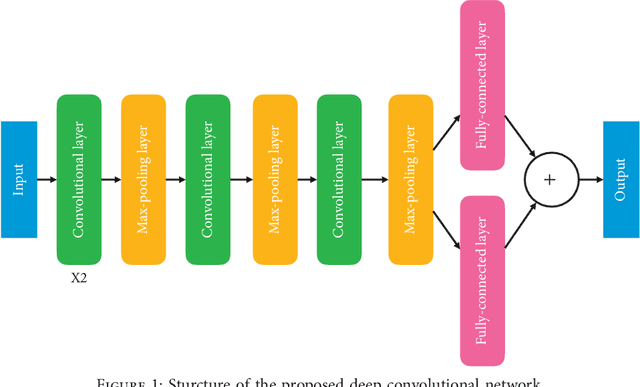
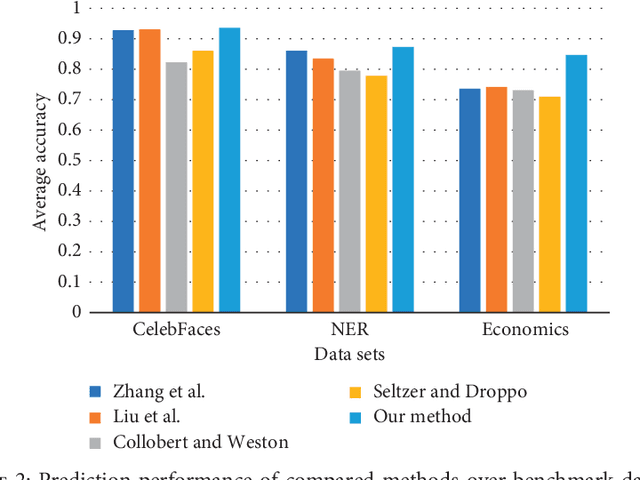
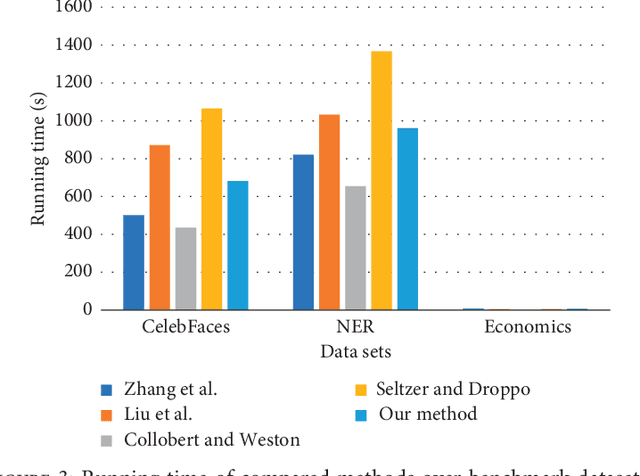
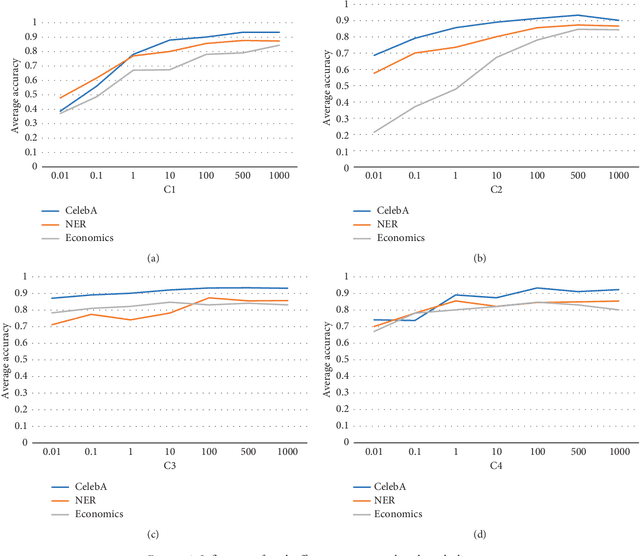
In this paper, we propose a novel multi-task learning method based on the deep convolutional network. The proposed deep network has four convolutional layers, three max-pooling layers, and two parallel fully connected layers. To adjust the deep network to multi-task learning problem, we propose to learn a low-rank deep network so that the relation among different tasks can be explored. We proposed to minimize the number of independent parameter rows of one fully connected layer to explore the relations among different tasks, which is measured by the nuclear norm of the parameter of one fully connected layer, and seek a low-rank parameter matrix. Meanwhile, we also propose to regularize another fully connected layer by sparsity penalty, so that the useful features learned by the lower layers can be selected. The learning problem is solved by an iterative algorithm based on gradient descent and back-propagation algorithms. The proposed algorithm is evaluated over benchmark data sets of multiple face attribute prediction, multi-task natural language processing, and joint economics index predictions. The evaluation results show the advantage of the low-rank deep CNN model over multi-task problems.
Cross-domain attribute representation based on convolutional neural network
May 17, 2018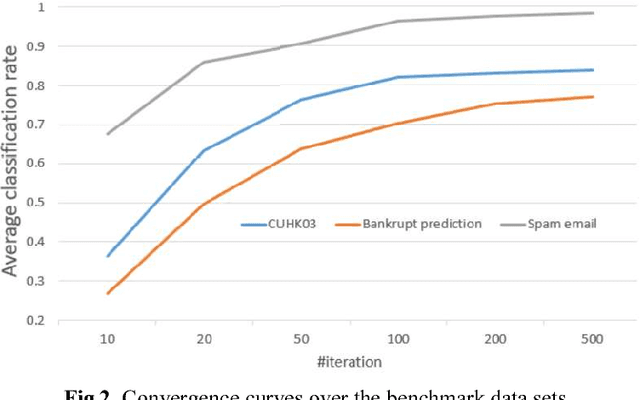
In the problem of domain transfer learning, we learn a model for the predic-tion in a target domain from the data of both some source domains and the target domain, where the target domain is in lack of labels while the source domain has sufficient labels. Besides the instances of the data, recently the attributes of data shared across domains are also explored and proven to be very helpful to leverage the information of different domains. In this paper, we propose a novel learning framework for domain-transfer learning based on both instances and attributes. We proposed to embed the attributes of dif-ferent domains by a shared convolutional neural network (CNN), learn a domain-independent CNN model to represent the information shared by dif-ferent domains by matching across domains, and a domain-specific CNN model to represent the information of each domain. The concatenation of the three CNN model outputs is used to predict the class label. An iterative algo-rithm based on gradient descent method is developed to learn the parameters of the model. The experiments over benchmark datasets show the advantage of the proposed model.
Domain transfer convolutional attribute embedding
Apr 01, 2018
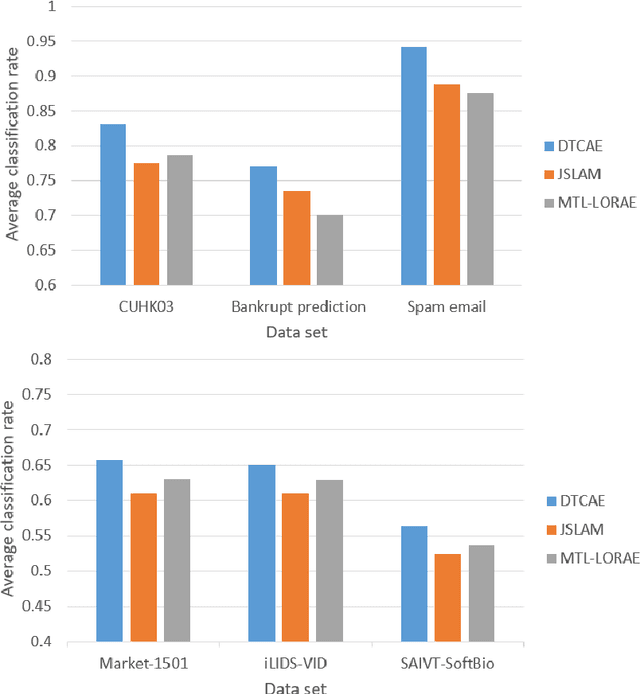
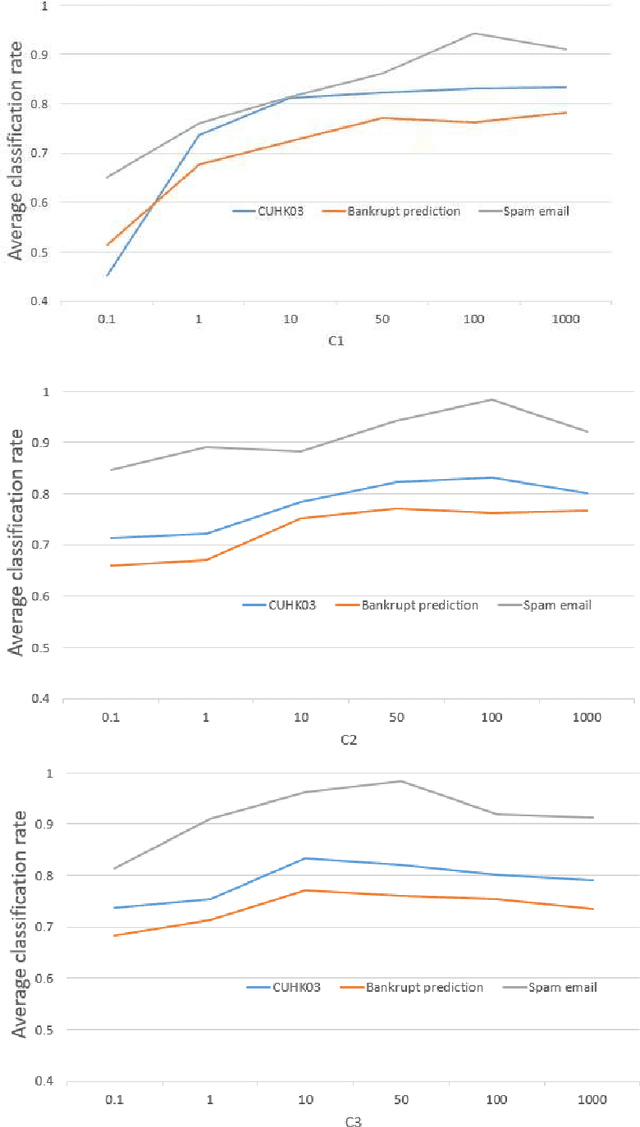
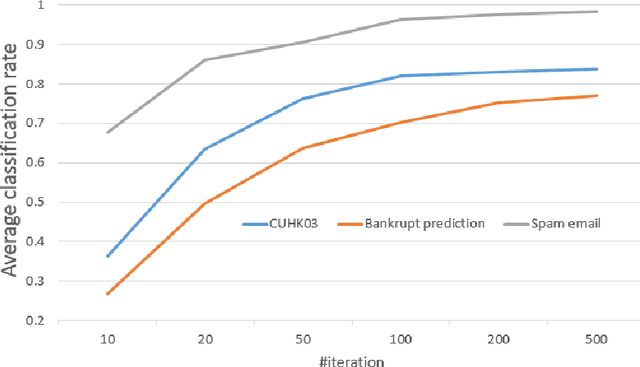
In this paper, we study the problem of transfer learning with the attribute data. In the transfer learning problem, we want to leverage the data of the auxiliary and the target domains to build an effective model for the classification problem in the target domain. Meanwhile, the attributes are naturally stable cross different domains. This strongly motives us to learn effective domain transfer attribute representations. To this end, we proposed to embed the attributes of the data to a common space by using the powerful convolutional neural network (CNN) model. The convolutional representations of the data points are mapped to the corresponding attributes so that they can be effective embedding of the attributes. We also represent the data of different domains by a domain-independent CNN, ant a domain-specific CNN, and combine their outputs with the attribute embedding to build the classification model. An joint learning framework is constructed to minimize the classification errors, the attribute mapping error, the mismatching of the domain-independent representations cross different domains, and to encourage the the neighborhood smoothness of representations in the target domain. The minimization problem is solved by an iterative algorithm based on gradient descent. Experiments over benchmark data sets of person re-identification, bankruptcy prediction, and spam email detection, show the effectiveness of the proposed method.
A novel image tag completion method based on convolutional neural network
Jun 03, 2017
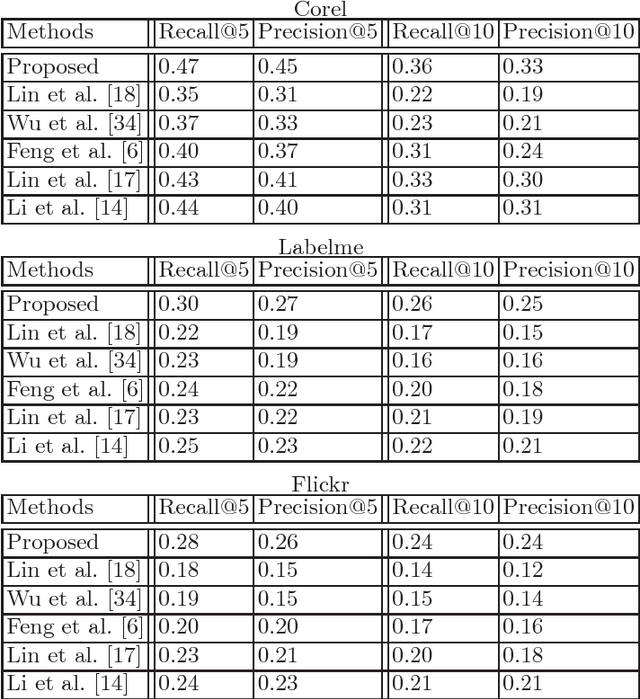

In the problems of image retrieval and annotation, complete textual tag lists of images play critical roles. However, in real-world applications, the image tags are usually incomplete, thus it is important to learn the complete tags for images. In this paper, we study the problem of image tag complete and proposed a novel method for this problem based on a popular image representation method, convolutional neural network (CNN). The method estimates the complete tags from the convolutional filtering outputs of images based on a linear predictor. The CNN parameters, linear predictor, and the complete tags are learned jointly by our method. We build a minimization problem to encourage the consistency between the complete tags and the available incomplete tags, reduce the estimation error, and reduce the model complexity. An iterative algorithm is developed to solve the minimization problem. Experiments over benchmark image data sets show its effectiveness.
Learning convolutional neural network to maximize Pos@Top performance measure
Mar 01, 2017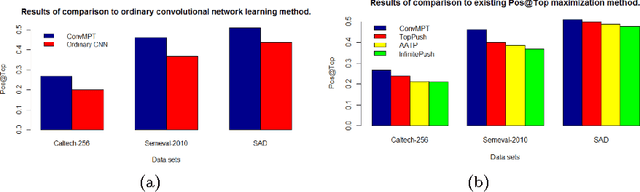
In the machine learning problems, the performance measure is used to evaluate the machine learning models. Recently, the number positive data points ranked at the top positions (Pos@Top) has been a popular performance measure in the machine learning community. In this paper, we propose to learn a convolutional neural network (CNN) model to maximize the Pos@Top performance measure. The CNN model is used to represent the multi-instance data point, and a classifier function is used to predict the label from the its CNN representation. We propose to minimize the loss function of Pos@Top over a training set to learn the filters of CNN and the classifier parameter. The classifier parameter vector is solved by the Lagrange multiplier method, and the filters are updated by the gradient descent method alternately in an iterative algorithm. Experiments over benchmark data sets show that the proposed method outperforms the state-of-the-art Pos@Top maximization methods.
Adaptive Graph via Multiple Kernel Learning for Nonnegative Matrix Factorization
Apr 03, 2013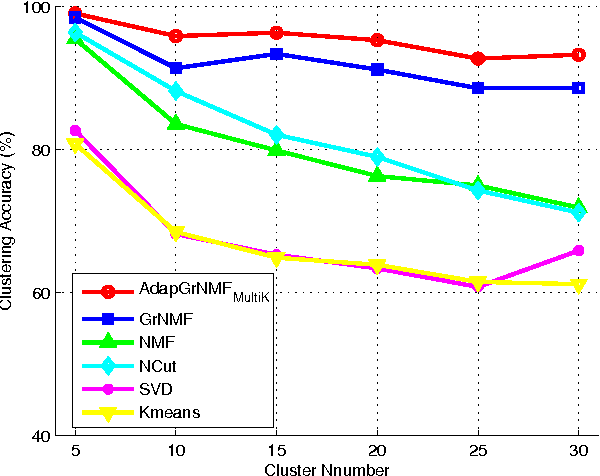


Nonnegative Matrix Factorization (NMF) has been continuously evolving in several areas like pattern recognition and information retrieval methods. It factorizes a matrix into a product of 2 low-rank non-negative matrices that will define parts-based, and linear representation of nonnegative data. Recently, Graph regularized NMF (GrNMF) is proposed to find a compact representation,which uncovers the hidden semantics and simultaneously respects the intrinsic geometric structure. In GNMF, an affinity graph is constructed from the original data space to encode the geometrical information. In this paper, we propose a novel idea which engages a Multiple Kernel Learning approach into refining the graph structure that reflects the factorization of the matrix and the new data space. The GrNMF is improved by utilizing the graph refined by the kernel learning, and then a novel kernel learning method is introduced under the GrNMF framework. Our approach shows encouraging results of the proposed algorithm in comparison to the state-of-the-art clustering algorithms like NMF, GrNMF, SVD etc.
Discriminative Sparse Coding on Multi-Manifold for Data Representation and Classification
Apr 03, 2013


Sparse coding has been popularly used as an effective data representation method in various applications, such as computer vision, medical imaging and bioinformatics, etc. However, the conventional sparse coding algorithms and its manifold regularized variants (graph sparse coding and Laplacian sparse coding), learn the codebook and codes in a unsupervised manner and neglect the class information available in the training set. To address this problem, in this paper we propose a novel discriminative sparse coding method based on multi-manifold, by learning discriminative class-conditional codebooks and sparse codes from both data feature space and class labels. First, the entire training set is partitioned into multiple manifolds according to the class labels. Then, we formulate the sparse coding as a manifold-manifold matching problem and learn class-conditional codebooks and codes to maximize the manifold margins of different classes. Lastly, we present a data point-manifold matching error based strategy to classify the unlabeled data point. Experimental results on somatic mutations identification and breast tumors classification in ultrasonic images tasks demonstrate the efficacy of the proposed data representation-classification approach.