 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskFocus: Focusing Policy Optimization on Critical Steps for Masked Image Generation
Dec 21, 2025Reinforcement learning (RL) has demonstrated significant potential for post-training language models and autoregressive visual generative models, but adapting RL to masked generative models remains challenging. The core factor is that policy optimization requires accounting for the probability likelihood of each step due to its multi-step and iterative refinement process. This reliance on entire sampling trajectories introduces high computational cost, whereas natively optimizing random steps often yields suboptimal results. In this paper, we present MaskFocus, a novel RL framework that achieves effective policy optimization for masked generative models by focusing on critical steps. Specifically, we determine the step-level information gain by measuring the similarity between the intermediate images at each sampling step and the final generated image. Crucially, we leverage this to identify the most critical and valuable steps and execute focused policy optimization on them. Furthermore, we design a dynamic routing sampling mechanism based on entropy to encourage the model to explore more valuable masking strategies for samples with low entropy. Extensive experiments on multiple Text-to-Image benchmarks validate the effectiveness of our method.
Group Critical-token Policy Optimization for Autoregressive Image Generation
Sep 26, 2025Recent studies have extended Reinforcement Learning with Verifiable Rewards (RLVR) to autoregressive (AR) visual generation and achieved promising progress. However, existing methods typically apply uniform optimization across all image tokens, while the varying contributions of different image tokens for RLVR's training remain unexplored. In fact, the key obstacle lies in how to identify more critical image tokens during AR generation and implement effective token-wise optimization for them. To tackle this challenge, we propose $\textbf{G}$roup $\textbf{C}$ritical-token $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{GCPO}$), which facilitates effective policy optimization on critical tokens. We identify the critical tokens in RLVR-based AR generation from three perspectives, specifically: $\textbf{(1)}$ Causal dependency: early tokens fundamentally determine the later tokens and final image effect due to unidirectional dependency; $\textbf{(2)}$ Entropy-induced spatial structure: tokens with high entropy gradients correspond to image structure and bridges distinct visual regions; $\textbf{(3)}$ RLVR-focused token diversity: tokens with low visual similarity across a group of sampled images contribute to richer token-level diversity. For these identified critical tokens, we further introduce a dynamic token-wise advantage weight to encourage exploration, based on confidence divergence between the policy model and reference model. By leveraging 30\% of the image tokens, GCPO achieves better performance than GRPO with full tokens. Extensive experiments on multiple text-to-image benchmarks for both AR models and unified multimodal models demonstrate the effectiveness of GCPO for AR visual generation.
Towards Human-Like Trajectory Prediction for Autonomous Driving: A Behavior-Centric Approach
May 27, 2025



Predicting the trajectories of vehicles is crucial for the development of autonomous driving (AD) systems, particularly in complex and dynamic traffic environments. In this study, we introduce HiT (Human-like Trajectory Prediction), a novel model designed to enhance trajectory prediction by incorporating behavior-aware modules and dynamic centrality measures. Unlike traditional methods that primarily rely on static graph structures, HiT leverages a dynamic framework that accounts for both direct and indirect interactions among traffic participants. This allows the model to capture the subtle yet significant influences of surrounding vehicles, enabling more accurate and human-like predictions. To evaluate HiT's performance, we conducted extensive experiments using diverse and challenging real-world datasets, including NGSIM, HighD, RounD, ApolloScape, and MoCAD++. The results demonstrate that HiT consistently outperforms other top models across multiple metrics, particularly excelling in scenarios involving aggressive driving behaviors. This research presents a significant step forward in trajectory prediction, offering a more reliable and interpretable approach for enhancing the safety and efficiency of fully autonomous driving systems.
DEMO: A Dynamics-Enhanced Learning Model for Multi-Horizon Trajectory Prediction in Autonomous Vehicles
Dec 30, 2024



Autonomous vehicles (AVs) rely on accurate trajectory prediction of surrounding vehicles to ensure the safety of both passengers and other road users. Trajectory prediction spans both short-term and long-term horizons, each requiring distinct considerations: short-term predictions rely on accurately capturing the vehicle's dynamics, while long-term predictions rely on accurately modeling the interaction patterns within the environment. However current approaches, either physics-based or learning-based models, always ignore these distinct considerations, making them struggle to find the optimal prediction for both short-term and long-term horizon. In this paper, we introduce the Dynamics-Enhanced Learning MOdel (DEMO), a novel approach that combines a physics-based Vehicle Dynamics Model with advanced deep learning algorithms. DEMO employs a two-stage architecture, featuring a Dynamics Learning Stage and an Interaction Learning Stage, where the former stage focuses on capturing vehicle motion dynamics and the latter focuses on modeling interaction. By capitalizing on the respective strengths of both methods, DEMO facilitates multi-horizon predictions for future trajectories. Experimental results on the Next Generation Simulation (NGSIM), Macau Connected Autonomous Driving (MoCAD), Highway Drone (HighD), and nuScenes datasets demonstrate that DEMO outperforms state-of-the-art (SOTA) baselines in both short-term and long-term prediction horizons.
Real-time Accident Anticipation for Autonomous Driving Through Monocular Depth-Enhanced 3D Modeling
Sep 02, 2024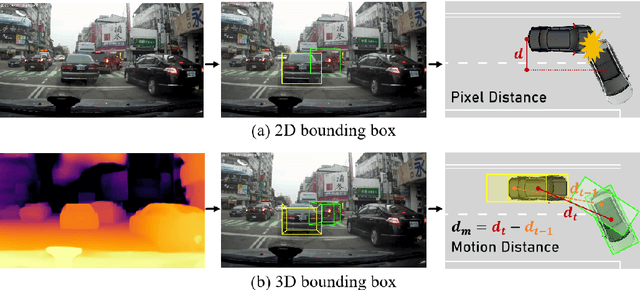
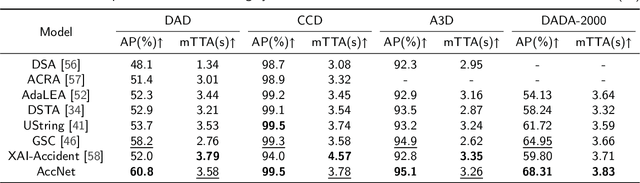
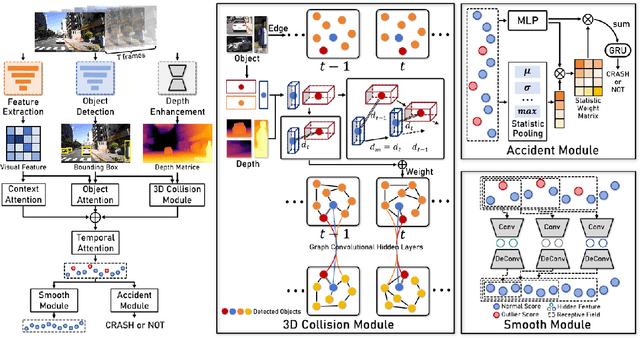
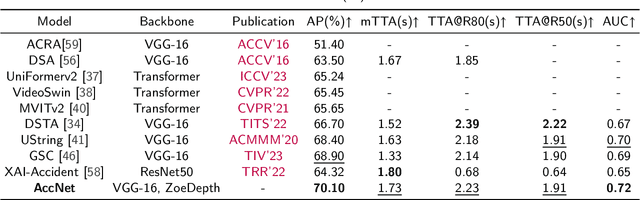
The primary goal of traffic accident anticipation is to foresee potential accidents in real time using dashcam videos, a task that is pivotal for enhancing the safety and reliability of autonomous driving technologies. In this study, we introduce an innovative framework, AccNet, which significantly advances the prediction capabilities beyond the current state-of-the-art (SOTA) 2D-based methods by incorporating monocular depth cues for sophisticated 3D scene modeling. Addressing the prevalent challenge of skewed data distribution in traffic accident datasets, we propose the Binary Adaptive Loss for Early Anticipation (BA-LEA). This novel loss function, together with a multi-task learning strategy, shifts the focus of the predictive model towards the critical moments preceding an accident. {We rigorously evaluate the performance of our framework on three benchmark datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), and DADA-2000 Dataset--demonstrating its superior predictive accuracy through key metrics such as Average Precision (AP) and mean Time-To-Accident (mTTA).
World Models for Autonomous Driving: An Initial Survey
Mar 05, 2024



In the rapidly evolving landscape of autonomous driving, the capability to accurately predict future events and assess their implications is paramount for both safety and efficiency, critically aiding the decision-making process. World models have emerged as a transformative approach, enabling autonomous driving systems to synthesize and interpret vast amounts of sensor data, thereby predicting potential future scenarios and compensating for information gaps. This paper provides an initial review of the current state and prospective advancements of world models in autonomous driving, spanning their theoretical underpinnings, practical applications, and the ongoing research efforts aimed at overcoming existing limitations. Highlighting the significant role of world models in advancing autonomous driving technologies, this survey aspires to serve as a foundational reference for the research community, facilitating swift access to and comprehension of this burgeoning field, and inspiring continued innovation and exploration.
A Deep Reinforcement Learning Approach for Traffic Signal Control Optimization
Jul 13, 2021


Inefficient traffic signal control methods may cause numerous problems, such as traffic congestion and waste of energy. Reinforcement learning (RL) is a trending data-driven approach for adaptive traffic signal control in complex urban traffic networks. Although the development of deep neural networks (DNN) further enhances its learning capability, there are still some challenges in applying deep RLs to transportation networks with multiple signalized intersections, including non-stationarity environment, exploration-exploitation dilemma, multi-agent training schemes, continuous action spaces, etc. In order to address these issues, this paper first proposes a multi-agent deep deterministic policy gradient (MADDPG) method by extending the actor-critic policy gradient algorithms. MADDPG has a centralized learning and decentralized execution paradigm in which critics use additional information to streamline the training process, while actors act on their own local observations. The model is evaluated via simulation on the Simulation of Urban MObility (SUMO) platform. Model comparison results show the efficiency of the proposed algorithm in controlling traffic lights.
Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning
Apr 20, 2021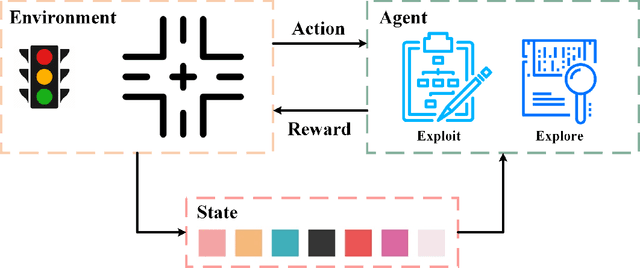


Inefficient traffic control may cause numerous problems such as traffic congestion and energy waste. This paper proposes a novel multi-agent reinforcement learning method, named KS-DDPG (Knowledge Sharing Deep Deterministic Policy Gradient) to achieve optimal control by enhancing the cooperation between traffic signals. By introducing the knowledge-sharing enabled communication protocol, each agent can access to the collective representation of the traffic environment collected by all agents. The proposed method is evaluated through two experiments respectively using synthetic and real-world datasets. The comparison with state-of-the-art reinforcement learning-based and conventional transportation methods demonstrate the proposed KS-DDPG has significant efficiency in controlling large-scale transportation networks and coping with fluctuations in traffic flow. In addition, the introduced communication mechanism has also been proven to speed up the convergence of the model without significantly increasing the computational burden.
Cascade Feature Aggregation for Human Pose Estimation
Apr 08, 2019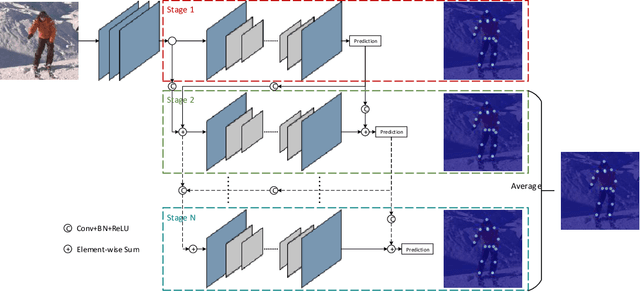
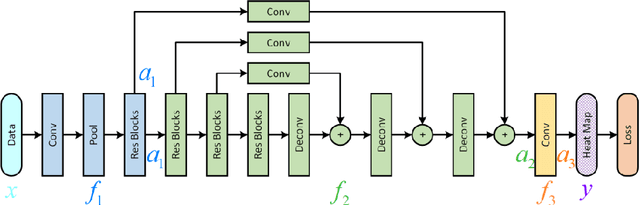
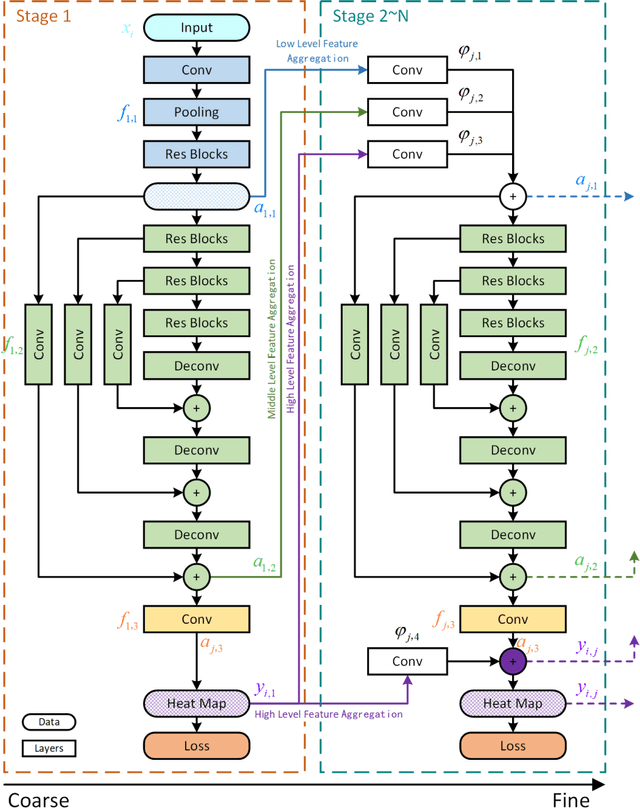
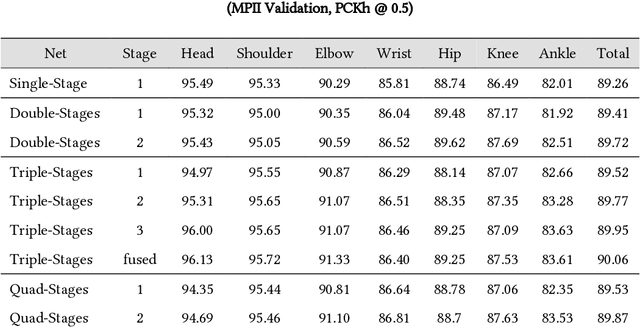
Human pose estimation plays an important role in many computer vision tasks and has been studied for many decades. However, due to complex appearance variations from poses, illuminations, occlusions and low resolutions, it still remains a challenging problem. Taking the advantage of high-level semantic information from deep convolutional neural networks is an effective way to improve the accuracy of human pose estimation. In this paper, we propose a novel Cascade Feature Aggregation (CFA) method, which cascades several hourglass networks for robust human pose estimation. Features from different stages are aggregated to obtain abundant contextual information, leading to robustness to poses, partial occlusions and low resolution. Moreover, results from different stages are fused to further improve the localization accuracy. The extensive experiments on MPII datasets and LIP datasets demonstrate that our proposed CFA outperforms the state-of-the-art and achieves the best performance on the state-of-the-art benchmark MPII.
Cross-domain attribute representation based on convolutional neural network
May 17, 2018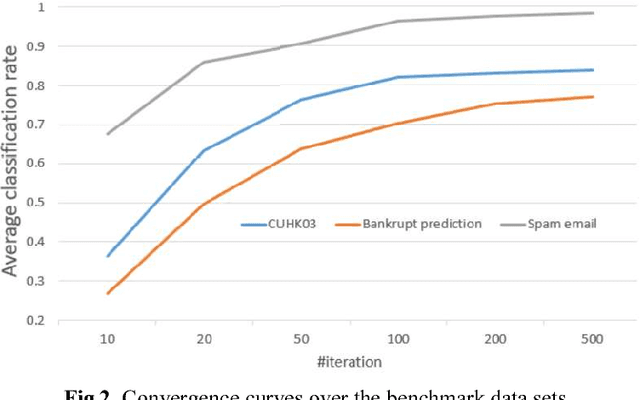
In the problem of domain transfer learning, we learn a model for the predic-tion in a target domain from the data of both some source domains and the target domain, where the target domain is in lack of labels while the source domain has sufficient labels. Besides the instances of the data, recently the attributes of data shared across domains are also explored and proven to be very helpful to leverage the information of different domains. In this paper, we propose a novel learning framework for domain-transfer learning based on both instances and attributes. We proposed to embed the attributes of dif-ferent domains by a shared convolutional neural network (CNN), learn a domain-independent CNN model to represent the information shared by dif-ferent domains by matching across domains, and a domain-specific CNN model to represent the information of each domain. The concatenation of the three CNN model outputs is used to predict the class label. An iterative algo-rithm based on gradient descent method is developed to learn the parameters of the model. The experiments over benchmark datasets show the advantage of the proposed model.