 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Dec 31, 2025World models have become crucial for autonomous driving, as they learn how scenarios evolve over time to address the long-tail challenges of the real world. However, current approaches relegate world models to limited roles: they operate within ostensibly unified architectures that still keep world prediction and motion planning as decoupled processes. To bridge this gap, we propose DriveLaW, a novel paradigm that unifies video generation and motion planning. By directly injecting the latent representation from its video generator into the planner, DriveLaW ensures inherent consistency between high-fidelity future generation and reliable trajectory planning. Specifically, DriveLaW consists of two core components: DriveLaW-Video, our powerful world model that generates high-fidelity forecasting with expressive latent representations, and DriveLaW-Act, a diffusion planner that generates consistent and reliable trajectories from the latent of DriveLaW-Video, with both components optimized by a three-stage progressive training strategy. The power of our unified paradigm is demonstrated by new state-of-the-art results across both tasks. DriveLaW not only advances video prediction significantly, surpassing best-performing work by 33.3% in FID and 1.8% in FVD, but also achieves a new record on the NAVSIM planning benchmark.
A Compositional Framework for On-the-Fly LTLf Synthesis
Aug 06, 2025Reactive synthesis from Linear Temporal Logic over finite traces (LTLf) can be reduced to a two-player game over a Deterministic Finite Automaton (DFA) of the LTLf specification. The primary challenge here is DFA construction, which is 2EXPTIME-complete in the worst case. Existing techniques either construct the DFA compositionally before solving the game, leveraging automata minimization to mitigate state-space explosion, or build the DFA incrementally during game solving to avoid full DFA construction. However, neither is dominant. In this paper, we introduce a compositional on-the-fly synthesis framework that integrates the strengths of both approaches, focusing on large conjunctions of smaller LTLf formulas common in practice. This framework applies composition during game solving instead of automata (game arena) construction. While composing all intermediate results may be necessary in the worst case, pruning these results simplifies subsequent compositions and enables early detection of unrealizability. Specifically, the framework allows two composition variants: pruning before composition to take full advantage of minimization or pruning during composition to guide on-the-fly synthesis. Compared to state-of-the-art synthesis solvers, our framework is able to solve a notable number of instances that other solvers cannot handle. A detailed analysis shows that both composition variants have unique merits.
Rethinking the Privacy of Text Embeddings: A Reproducibility Study of "Text Embeddings Reveal (Almost) As Much As Text"
Jul 10, 2025Text embeddings are fundamental to many natural language processing (NLP) tasks, extensively applied in domains such as recommendation systems and information retrieval (IR). Traditionally, transmitting embeddings instead of raw text has been seen as privacy-preserving. However, recent methods such as Vec2Text challenge this assumption by demonstrating that controlled decoding can successfully reconstruct original texts from black-box embeddings. The unexpectedly strong results reported by Vec2Text motivated us to conduct further verification, particularly considering the typically non-intuitive and opaque structure of high-dimensional embedding spaces. In this work, we reproduce the Vec2Text framework and evaluate it from two perspectives: (1) validating the original claims, and (2) extending the study through targeted experiments. First, we successfully replicate the original key results in both in-domain and out-of-domain settings, with only minor discrepancies arising due to missing artifacts, such as model checkpoints and dataset splits. Furthermore, we extend the study by conducting a parameter sensitivity analysis, evaluating the feasibility of reconstructing sensitive inputs (e.g., passwords), and exploring embedding quantization as a lightweight privacy defense. Our results show that Vec2Text is effective under ideal conditions, capable of reconstructing even password-like sequences that lack clear semantics. However, we identify key limitations, including its sensitivity to input sequence length. We also find that Gaussian noise and quantization techniques can mitigate the privacy risks posed by Vec2Text, with quantization offering a simpler and more widely applicable solution. Our findings emphasize the need for caution in using text embeddings and highlight the importance of further research into robust defense mechanisms for NLP systems.
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Jun 09, 2025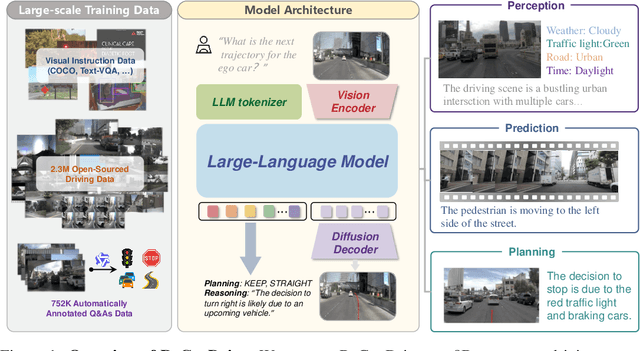
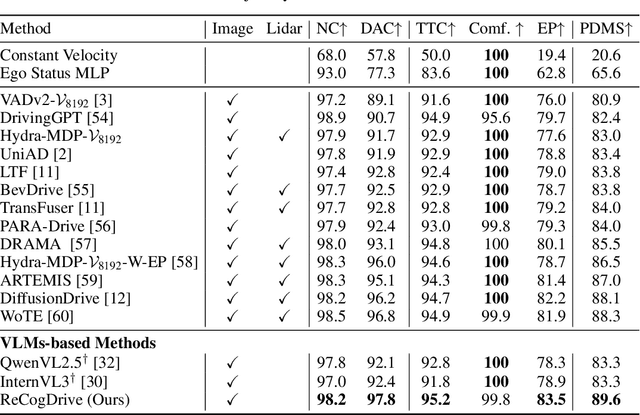
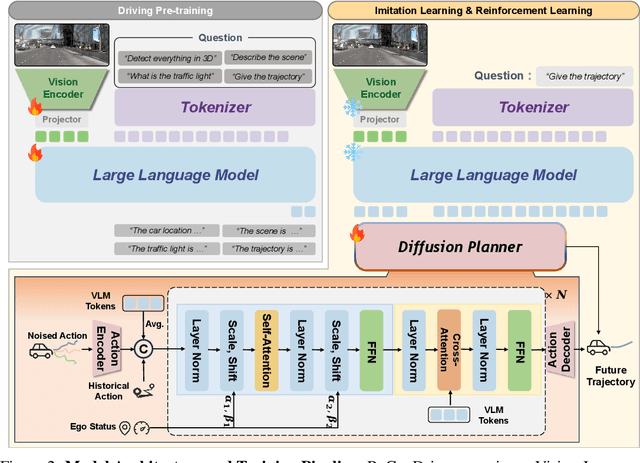
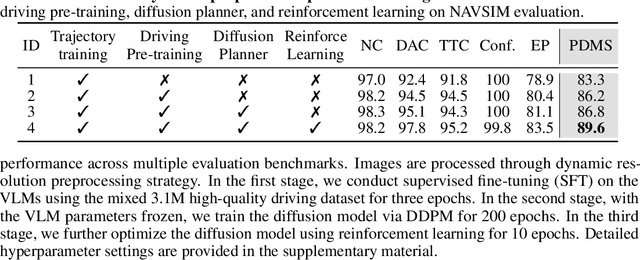
Although end-to-end autonomous driving has made remarkable progress, its performance degrades significantly in rare and long-tail scenarios. Recent approaches attempt to address this challenge by leveraging the rich world knowledge of Vision-Language Models (VLMs), but these methods suffer from several limitations: (1) a significant domain gap between the pre-training data of VLMs and real-world driving data, (2) a dimensionality mismatch between the discrete language space and the continuous action space, and (3) imitation learning tends to capture the average behavior present in the dataset, which may be suboptimal even dangerous. In this paper, we propose ReCogDrive, an autonomous driving system that integrates VLMs with diffusion planner, which adopts a three-stage paradigm for training. In the first stage, we use a large-scale driving question-answering datasets to train the VLMs, mitigating the domain discrepancy between generic content and real-world driving scenarios. In the second stage, we employ a diffusion-based planner to perform imitation learning, mapping representations from the latent language space to continuous driving actions. Finally, we fine-tune the diffusion planner using reinforcement learning with NAVSIM non-reactive simulator, enabling the model to generate safer, more human-like driving trajectories. We evaluate our approach on the planning-oriented NAVSIM benchmark, achieving a PDMS of 89.6 and setting a new state-of-the-art that surpasses the previous vision-only SOTA by 5.6 PDMS.
Unsupervised Corpus Poisoning Attacks in Continuous Space for Dense Retrieval
Apr 24, 2025This paper concerns corpus poisoning attacks in dense information retrieval, where an adversary attempts to compromise the ranking performance of a search algorithm by injecting a small number of maliciously generated documents into the corpus. Our work addresses two limitations in the current literature. First, attacks that perform adversarial gradient-based word substitution search do so in the discrete lexical space, while retrieval itself happens in the continuous embedding space. We thus propose an optimization method that operates in the embedding space directly. Specifically, we train a perturbation model with the objective of maintaining the geometric distance between the original and adversarial document embeddings, while also maximizing the token-level dissimilarity between the original and adversarial documents. Second, it is common for related work to have a strong assumption that the adversary has prior knowledge about the queries. In this paper, we focus on a more challenging variant of the problem where the adversary assumes no prior knowledge about the query distribution (hence, unsupervised). Our core contribution is an adversarial corpus attack that is fast and effective. We present comprehensive experimental results on both in- and out-of-domain datasets, focusing on two related tasks: a top-1 attack and a corpus poisoning attack. We consider attacks under both a white-box and a black-box setting. Notably, our method can generate successful adversarial examples in under two minutes per target document; four times faster compared to the fastest gradient-based word substitution methods in the literature with the same hardware. Furthermore, our adversarial generation method generates text that is more likely to occur under the distribution of natural text (low perplexity), and is therefore more difficult to detect.
Agent-centric Information Access
Feb 26, 2025As large language models (LLMs) become more specialized, we envision a future where millions of expert LLMs exist, each trained on proprietary data and excelling in specific domains. In such a system, answering a query requires selecting a small subset of relevant models, querying them efficiently, and synthesizing their responses. This paper introduces a framework for agent-centric information access, where LLMs function as knowledge agents that are dynamically ranked and queried based on their demonstrated expertise. Unlike traditional document retrieval, this approach requires inferring expertise on the fly, rather than relying on static metadata or predefined model descriptions. This shift introduces several challenges, including efficient expert selection, cost-effective querying, response aggregation across multiple models, and robustness against adversarial manipulation. To address these issues, we propose a scalable evaluation framework that leverages retrieval-augmented generation and clustering techniques to construct and assess thousands of specialized models, with the potential to scale toward millions.
Reproducing HotFlip for Corpus Poisoning Attacks in Dense Retrieval
Jan 08, 2025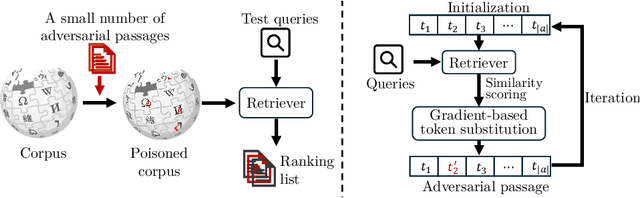
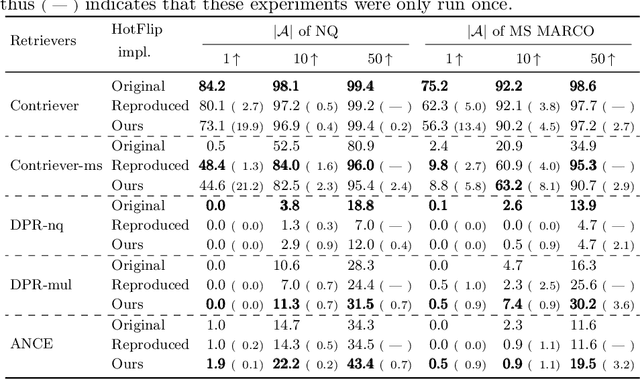
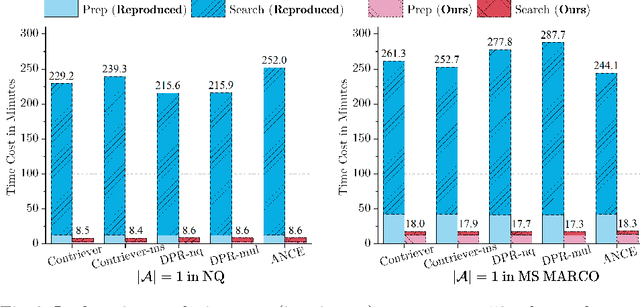
HotFlip is a topical gradient-based word substitution method for attacking language models. Recently, this method has been further applied to attack retrieval systems by generating malicious passages that are injected into a corpus, i.e., corpus poisoning. However, HotFlip is known to be computationally inefficient, with the majority of time being spent on gradient accumulation for each query-passage pair during the adversarial token generation phase, making it impossible to generate an adequate number of adversarial passages in a reasonable amount of time. Moreover, the attack method itself assumes access to a set of user queries, a strong assumption that does not correspond to how real-world adversarial attacks are usually performed. In this paper, we first significantly boost the efficiency of HotFlip, reducing the adversarial generation process from 4 hours per document to only 15 minutes, using the same hardware. We further contribute experiments and analysis on two additional tasks: (1) transfer-based black-box attacks, and (2) query-agnostic attacks. Whenever possible, we provide comparisons between the original method and our improved version. Our experiments demonstrate that HotFlip can effectively attack a variety of dense retrievers, with an observed trend that its attack performance diminishes against more advanced and recent methods. Interestingly, we observe that while HotFlip performs poorly in a black-box setting, indicating limited capacity for generalization, in query-agnostic scenarios its performance is correlated to the volume of injected adversarial passages.
Mask-Adapter: The Devil is in the Masks for Open-Vocabulary Segmentation
Dec 05, 2024Recent open-vocabulary segmentation methods adopt mask generators to predict segmentation masks and leverage pre-trained vision-language models, e.g., CLIP, to classify these masks via mask pooling. Although these approaches show promising results, it is counterintuitive that accurate masks often fail to yield accurate classification results through pooling CLIP image embeddings within the mask regions. In this paper, we reveal the performance limitations of mask pooling and introduce Mask-Adapter, a simple yet effective method to address these challenges in open-vocabulary segmentation. Compared to directly using proposal masks, our proposed Mask-Adapter extracts semantic activation maps from proposal masks, providing richer contextual information and ensuring alignment between masks and CLIP. Additionally, we propose a mask consistency loss that encourages proposal masks with similar IoUs to obtain similar CLIP embeddings to enhance models' robustness to varying predicted masks. Mask-Adapter integrates seamlessly into open-vocabulary segmentation methods based on mask pooling in a plug-and-play manner, delivering more accurate classification results. Extensive experiments across several zero-shot benchmarks demonstrate significant performance gains for the proposed Mask-Adapter on several well-established methods. Notably, Mask-Adapter also extends effectively to SAM and achieves impressive results on several open-vocabulary segmentation datasets. Code and models are available at \url{https://github.com/hustvl/MaskAdapter}.
Real-time Accident Anticipation for Autonomous Driving Through Monocular Depth-Enhanced 3D Modeling
Sep 02, 2024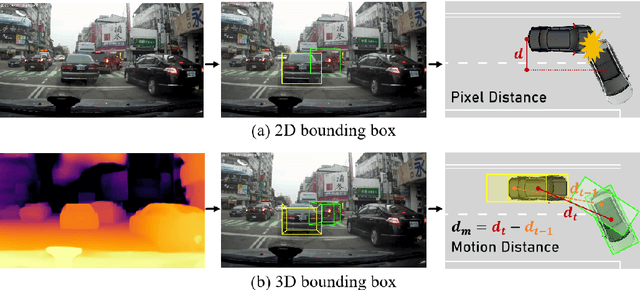
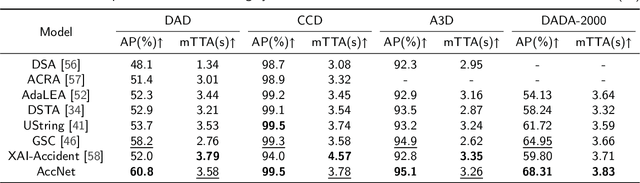
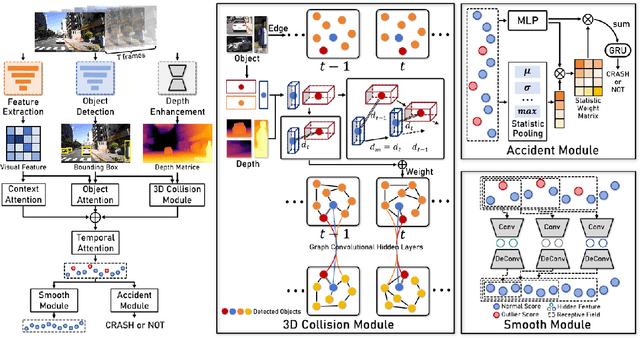
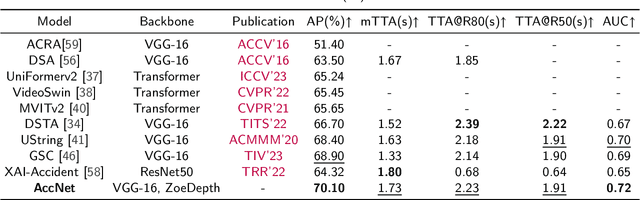
The primary goal of traffic accident anticipation is to foresee potential accidents in real time using dashcam videos, a task that is pivotal for enhancing the safety and reliability of autonomous driving technologies. In this study, we introduce an innovative framework, AccNet, which significantly advances the prediction capabilities beyond the current state-of-the-art (SOTA) 2D-based methods by incorporating monocular depth cues for sophisticated 3D scene modeling. Addressing the prevalent challenge of skewed data distribution in traffic accident datasets, we propose the Binary Adaptive Loss for Early Anticipation (BA-LEA). This novel loss function, together with a multi-task learning strategy, shifts the focus of the predictive model towards the critical moments preceding an accident. {We rigorously evaluate the performance of our framework on three benchmark datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), and DADA-2000 Dataset--demonstrating its superior predictive accuracy through key metrics such as Average Precision (AP) and mean Time-To-Accident (mTTA).
On-the-fly Synthesis for LTL over Finite Traces: An Efficient Approach that Counts
Aug 14, 2024



We present an on-the-fly synthesis framework for Linear Temporal Logic over finite traces (LTLf) based on top-down deterministic automata construction. Existing approaches rely on constructing a complete Deterministic Finite Automaton (DFA) corresponding to the LTLf specification, a process with doubly exponential complexity relative to the formula size in the worst case. In this case, the synthesis procedure cannot be conducted until the entire DFA is constructed. This inefficiency is the main bottleneck of existing approaches. To address this challenge, we first present a method for converting LTLf into Transition-based DFA (TDFA) by directly leveraging LTLf semantics, incorporating intermediate results as direct components of the final automaton to enable parallelized synthesis and automata construction. We then explore the relationship between LTLf synthesis and TDFA games and subsequently develop an algorithm for performing LTLf synthesis using on-the-fly TDFA game solving. This algorithm traverses the state space in a global forward manner combined with a local backward method, along with the detection of strongly connected components. Moreover, we introduce two optimization techniques -- model-guided synthesis and state entailment -- to enhance the practical efficiency of our approach. Experimental results demonstrate that our on-the-fly approach achieves the best performance on the tested benchmarks and effectively complements existing tools and approaches.