 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Privilege Usage of Agents on Real-World Tools
Mar 30, 2026Equipping LLM agents with real-world tools can substantially improve productivity. However, granting agents autonomy over tool use also transfers the associated privileges to both the agent and the underlying LLM. Improper privilege usage may lead to serious consequences, including information leakage and infrastructure damage. While several benchmarks have been built to study agents' security, they often rely on pre-coded tools and restricted interaction patterns. Such crafted environments differ substantially from the real-world, making it hard to assess agents' security capabilities in critical privilege control and usage. Therefore, we propose GrantBox, a security evaluation sandbox for analyzing agent privilege usage. GrantBox automatically integrates real-world tools and allows LLM agents to invoke genuine privileges, enabling the evaluation of privilege usage under prompt injection attacks. Our results indicate that while LLMs exhibit basic security awareness and can block some direct attacks, they remain vulnerable to more sophisticated attacks, resulting in an average attack success rate of 84.80% in carefully crafted scenarios.
Verify Claimed Text-to-Image Models via Boundary-Aware Prompt Optimization
Mar 27, 2026As Text-to-Image (T2I) generation becomes widespread, third-party platforms increasingly integrate multiple model APIs for convenient image creation. However, false claims of using official models can mislead users and harm model owners' reputations, making model verification essential to confirm whether an API's underlying model matches its claim. Existing methods address this by using verification prompts generated by official model owners, but the generation relies on multiple reference models for optimization, leading to high computational cost and sensitivity to model selection. To address this problem, we propose a reference-free T2I model verification method called Boundary-aware Prompt Optimization (BPO). It directly explores the intrinsic characteristics of the target model. The key insight is that although different T2I models produce similar outputs for normal prompts, their semantic boundaries in the embedding space (transition zones between two concepts such as "corgi" and "bagel") are distinct. Prompts near these boundaries generate unstable outputs (e.g., sometimes a corgi and sometimes a bagel) on the target model but remain stable on other models. By identifying such boundary-adjacent prompts, BPO captures model-specific behaviors that serve as reliable verification cues for distinguishing T2I models. Experiments on five T2I models and four baselines demonstrate that BPO achieves superior verification accuracy.
MEMTS: Internalizing Domain Knowledge via Parameterized Memory for Retrieval-Free Domain Adaptation of Time Series Foundation Models
Feb 14, 2026While Time Series Foundation Models (TSFMs) have demonstrated exceptional performance in generalized forecasting, their performance often degrades significantly when deployed in real-world vertical domains characterized by temporal distribution shifts and domain-specific periodic structures. Current solutions are primarily constrained by two paradigms: Domain-Adaptive Pretraining (DAPT), which improves short-term domain fitting but frequently disrupts previously learned global temporal patterns due to catastrophic forgetting; and Retrieval-Augmented Generation (RAG), which incorporates external knowledge but introduces substantial retrieval overhead. This creates a severe scalability bottleneck that fails to meet the high-efficiency requirements of real-time stream processing. To break this impasse, we propose Memory for Time Series (MEMTS), a lightweight and plug-and-play method for retrieval-free domain adaptation in time series forecasting. The key component of MEMTS is a Knowledge Persistence Module (KPM), which internalizes domain-specific temporal dynamics, such as recurring seasonal patterns and trends into a compact set of learnable latent prototypes. In doing so, it transforms fragmented historical observations into continuous, parameterized knowledge representations. This paradigm shift enables MEMTS to achieve accurate domain adaptation with constant-time inference and near-zero latency, while effectively mitigating catastrophic forgetting of general temporal patterns, all without requiring any architectural modifications to the frozen TSFM backbone. Extensive experiments on multiple datasets demonstrate the SOTA performance of MEMTS.
Beyond Pixels: Semantic-aware Typographic Attack for Geo-Privacy Protection
Nov 16, 2025Large Visual Language Models (LVLMs) now pose a serious yet overlooked privacy threat, as they can infer a social media user's geolocation directly from shared images, leading to unintended privacy leakage. While adversarial image perturbations provide a potential direction for geo-privacy protection, they require relatively strong distortions to be effective against LVLMs, which noticeably degrade visual quality and diminish an image's value for sharing. To overcome this limitation, we identify typographical attacks as a promising direction for protecting geo-privacy by adding text extension outside the visual content. We further investigate which textual semantics are effective in disrupting geolocation inference and design a two-stage, semantics-aware typographical attack that generates deceptive text to protect user privacy. Extensive experiments across three datasets demonstrate that our approach significantly reduces geolocation prediction accuracy of five state-of-the-art commercial LVLMs, establishing a practical and visually-preserving protection strategy against emerging geo-privacy threats.
A Compositional Framework for On-the-Fly LTLf Synthesis
Aug 06, 2025Reactive synthesis from Linear Temporal Logic over finite traces (LTLf) can be reduced to a two-player game over a Deterministic Finite Automaton (DFA) of the LTLf specification. The primary challenge here is DFA construction, which is 2EXPTIME-complete in the worst case. Existing techniques either construct the DFA compositionally before solving the game, leveraging automata minimization to mitigate state-space explosion, or build the DFA incrementally during game solving to avoid full DFA construction. However, neither is dominant. In this paper, we introduce a compositional on-the-fly synthesis framework that integrates the strengths of both approaches, focusing on large conjunctions of smaller LTLf formulas common in practice. This framework applies composition during game solving instead of automata (game arena) construction. While composing all intermediate results may be necessary in the worst case, pruning these results simplifies subsequent compositions and enables early detection of unrealizability. Specifically, the framework allows two composition variants: pruning before composition to take full advantage of minimization or pruning during composition to guide on-the-fly synthesis. Compared to state-of-the-art synthesis solvers, our framework is able to solve a notable number of instances that other solvers cannot handle. A detailed analysis shows that both composition variants have unique merits.
Privacy Protection Against Personalized Text-to-Image Synthesis via Cross-image Consistency Constraints
Apr 17, 2025The rapid advancement of diffusion models and personalization techniques has made it possible to recreate individual portraits from just a few publicly available images. While such capabilities empower various creative applications, they also introduce serious privacy concerns, as adversaries can exploit them to generate highly realistic impersonations. To counter these threats, anti-personalization methods have been proposed, which add adversarial perturbations to published images to disrupt the training of personalization models. However, existing approaches largely overlook the intrinsic multi-image nature of personalization and instead adopt a naive strategy of applying perturbations independently, as commonly done in single-image settings. This neglects the opportunity to leverage inter-image relationships for stronger privacy protection. Therefore, we advocate for a group-level perspective on privacy protection against personalization. Specifically, we introduce Cross-image Anti-Personalization (CAP), a novel framework that enhances resistance to personalization by enforcing style consistency across perturbed images. Furthermore, we develop a dynamic ratio adjustment strategy that adaptively balances the impact of the consistency loss throughout the attack iterations. Extensive experiments on the classical CelebHQ and VGGFace2 benchmarks show that CAP substantially improves existing methods.
Automated detection of atomicity violations in large-scale systems
Apr 01, 2025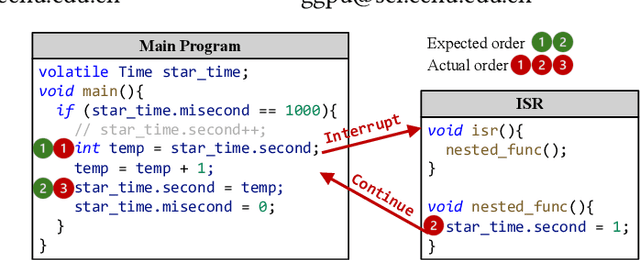

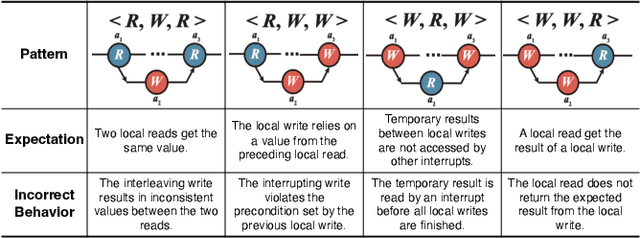

Atomicity violations in interrupt-driven programs pose a significant threat to software safety in critical systems. These violations occur when the execution sequence of operations on shared resources is disrupted by asynchronous interrupts. Detecting atomicity violations is challenging due to the vast program state space, application-level code dependencies, and complex domain-specific knowledge. We propose Clover, a hybrid framework that integrates static analysis with large language model (LLM) agents to detect atomicity violations in real-world programs. Clover first performs static analysis to extract critical code snippets and operation information. It then initiates a multi-agent process, where the expert agent leverages domain-specific knowledge to detect atomicity violations, which are subsequently validated by the judge agent. Evaluations on RaceBench 2.1, SV-COMP, and RWIP demonstrate that Clover achieves a precision/recall of 92.3%/86.6%, outperforming existing approaches by 27.4-118.2% on F1-score.
Scale-Invariant Adversarial Attack against Arbitrary-scale Super-resolution
Mar 06, 2025



The advent of local continuous image function (LIIF) has garnered significant attention for arbitrary-scale super-resolution (SR) techniques. However, while the vulnerabilities of fixed-scale SR have been assessed, the robustness of continuous representation-based arbitrary-scale SR against adversarial attacks remains an area warranting further exploration. The elaborately designed adversarial attacks for fixed-scale SR are scale-dependent, which will cause time-consuming and memory-consuming problems when applied to arbitrary-scale SR. To address this concern, we propose a simple yet effective ``scale-invariant'' SR adversarial attack method with good transferability, termed SIAGT. Specifically, we propose to construct resource-saving attacks by exploiting finite discrete points of continuous representation. In addition, we formulate a coordinate-dependent loss to enhance the cross-model transferability of the attack. The attack can significantly deteriorate the SR images while introducing imperceptible distortion to the targeted low-resolution (LR) images. Experiments carried out on three popular LIIF-based SR approaches and four classical SR datasets show remarkable attack performance and transferability of SIAGT.
A Study of In-Context-Learning-Based Text-to-SQL Errors
Jan 16, 2025


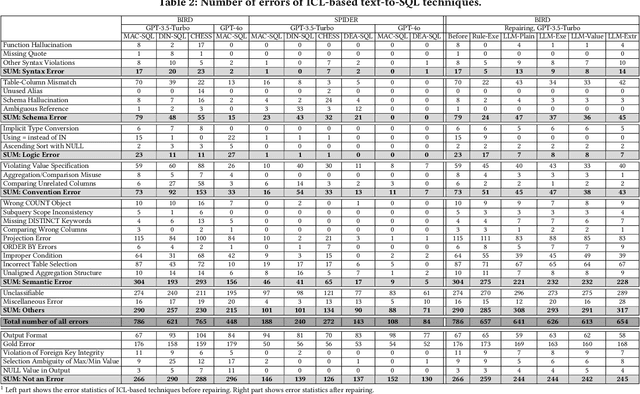
Large language models (LLMs) have been adopted to perform text-to-SQL tasks, utilizing their in-context learning (ICL) capability to translate natural language questions into structured query language (SQL). However, such a technique faces correctness problems and requires efficient repairing solutions. In this paper, we conduct the first comprehensive study of text-to-SQL errors. Our study covers four representative ICL-based techniques, five basic repairing methods, two benchmarks, and two LLM settings. We find that text-to-SQL errors are widespread and summarize 29 error types of 7 categories. We also find that existing repairing attempts have limited correctness improvement at the cost of high computational overhead with many mis-repairs. Based on the findings, we propose MapleRepair, a novel text-to-SQL error detection and repairing framework. The evaluation demonstrates that MapleRepair outperforms existing solutions by repairing 13.8% more queries with neglectable mis-repairs and 67.4% less overhead.
Concept Guided Co-saliency Objection Detection
Dec 21, 2024The task of co-saliency object detection (Co-SOD) seeks to identify common, salient objects across a collection of images by examining shared visual features. However, traditional Co-SOD methods often encounter limitations when faced with diverse object variations (e.g., different postures) and irrelevant background elements that introduce noise. To address these challenges, we propose ConceptCoSOD, a novel concept-guided approach that leverages text semantic information to enhance Co-SOD performance by guiding the model to focus on consistent object features. Through rethinking Co-SOD as an (image-text)-to-image task instead of an image-to-image task, ConceptCoSOD first captures shared semantic concepts within an image group and then uses them as guidance for precise object segmentation in complex scenarios. Experimental results on three benchmark datasets and six corruptions reveal that ConceptCoSOD significantly improves detection accuracy, especially in challenging settings with considerable background distractions and object variability.