 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffiSkill: Agent Skill Based Automated Code Efficiency Optimization
Mar 29, 2026Code efficiency is a fundamental aspect of software quality, yet how to harness large language models (LLMs) to optimize programs remains challenging. Prior approaches have sought for one-shot rewriting, retrieved exemplars, or prompt-based search, but they do not explicitly distill reusable optimization knowledge, which limits generalization beyond individual instances. In this paper, we present EffiSkill, a framework for code-efficiency optimization that builds a portable optimization toolbox for LLM-based agents. The key idea is to model recurring slow-to-fast transformations as reusable agent skills that capture both concrete transformation mechanisms and higher-level optimization strategies. EffiSkill adopts a two-stage design: Stage I mines Operator and Meta Skills from large-scale slow/fast program pairs to build a skill library; Stage II applies this library to unseen programs through execution-free diagnosis, skill retrieval, plan composition, and candidate generation, without runtime feedback. Results on EffiBench-X show that EffiSkill achieves higher optimization success rates, improving over the strongest baseline by 3.69 to 12.52 percentage points across model and language settings. These findings suggest that mechanism-level skill reuse provides a useful foundation for execution-free code optimization, and that the resulting skill library can serve as a reusable resource for broader agent workflows.
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Feb 02, 2026Large Language Models (LLMs) have achieved remarkable success in source code understanding, yet as software systems grow in scale, computational efficiency has become a critical bottleneck. Currently, these models rely on a text-based paradigm that treats source code as a linear sequence of tokens, which leads to a linear increase in context length and associated computational costs. The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images. Unlike text, which is difficult to compress without losing semantic meaning, the image modality is inherently suitable for compression. By adjusting resolution, images can be scaled to a fraction of their original token cost while remaining recognizable to vision-capable models. To explore the feasibility of this approach, we conduct the first systematic study on the effectiveness of MLLMs for code understanding. Our experiments reveal that: (1) MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; (2) MLLMs can effectively leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and (3) Code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs. Our findings highlight both the potential and current limitations of MLLMs in code understanding, which points out a shift toward image-modality code representation as a pathway to more efficient inference.
LocalSearchBench: Benchmarking Agentic Search in Real-World Local Life Services
Dec 08, 2025Recent advances in large reasoning models (LRMs) have enabled agentic search systems to perform complex multi-step reasoning across multiple sources. However, most studies focus on general information retrieval and rarely explores vertical domains with unique challenges. In this work, we focus on local life services and introduce LocalSearchBench, which encompass diverse and complex business scenarios. Real-world queries in this domain are often ambiguous and require multi-hop reasoning across merchants and products, remaining challenging and not fully addressed. As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types. We construct 300 multi-hop QA tasks based on real user queries, challenging agents to understand questions and retrieve information in multiple steps. We also developed LocalPlayground, a unified environment integrating multiple tools for agent interaction. Experiments show that even state-of-the-art LRMs struggle on LocalSearchBench: the best model (DeepSeek-V3.1) achieves only 34.34% correctness, and most models have issues with completeness (average 77.33%) and faithfulness (average 61.99%). This highlights the need for specialized benchmarks and domain-specific agent training in local life services. Code, Benchmark, and Leaderboard are available at localsearchbench.github.io.
Automated detection of atomicity violations in large-scale systems
Apr 01, 2025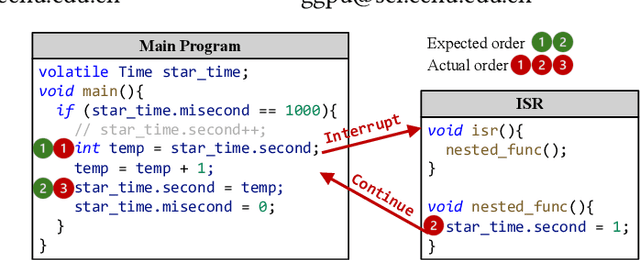


Atomicity violations in interrupt-driven programs pose a significant threat to software safety in critical systems. These violations occur when the execution sequence of operations on shared resources is disrupted by asynchronous interrupts. Detecting atomicity violations is challenging due to the vast program state space, application-level code dependencies, and complex domain-specific knowledge. We propose Clover, a hybrid framework that integrates static analysis with large language model (LLM) agents to detect atomicity violations in real-world programs. Clover first performs static analysis to extract critical code snippets and operation information. It then initiates a multi-agent process, where the expert agent leverages domain-specific knowledge to detect atomicity violations, which are subsequently validated by the judge agent. Evaluations on RaceBench 2.1, SV-COMP, and RWIP demonstrate that Clover achieves a precision/recall of 92.3%/86.6%, outperforming existing approaches by 27.4-118.2% on F1-score.
A Study of In-Context-Learning-Based Text-to-SQL Errors
Jan 16, 2025


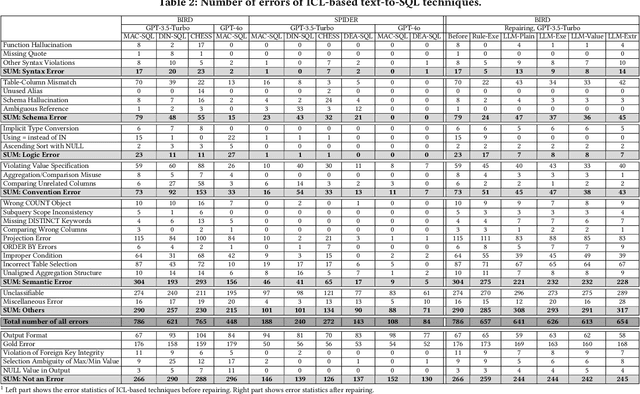
Large language models (LLMs) have been adopted to perform text-to-SQL tasks, utilizing their in-context learning (ICL) capability to translate natural language questions into structured query language (SQL). However, such a technique faces correctness problems and requires efficient repairing solutions. In this paper, we conduct the first comprehensive study of text-to-SQL errors. Our study covers four representative ICL-based techniques, five basic repairing methods, two benchmarks, and two LLM settings. We find that text-to-SQL errors are widespread and summarize 29 error types of 7 categories. We also find that existing repairing attempts have limited correctness improvement at the cost of high computational overhead with many mis-repairs. Based on the findings, we propose MapleRepair, a novel text-to-SQL error detection and repairing framework. The evaluation demonstrates that MapleRepair outperforms existing solutions by repairing 13.8% more queries with neglectable mis-repairs and 67.4% less overhead.
Towards Understanding Retrieval Accuracy and Prompt Quality in RAG Systems
Nov 29, 2024Retrieval-Augmented Generation (RAG) is a pivotal technique for enhancing the capability of large language models (LLMs) and has demonstrated promising efficacy across a diverse spectrum of tasks. While LLM-driven RAG systems show superior performance, they face unique challenges in stability and reliability. Their complexity hinders developers' efforts to design, maintain, and optimize effective RAG systems. Therefore, it is crucial to understand how RAG's performance is impacted by its design. In this work, we conduct an early exploratory study toward a better understanding of the mechanism of RAG systems, covering three code datasets, three QA datasets, and two LLMs. We focus on four design factors: retrieval document type, retrieval recall, document selection, and prompt techniques. Our study uncovers how each factor impacts system correctness and confidence, providing valuable insights for developing an accurate and reliable RAG system. Based on these findings, we present nine actionable guidelines for detecting defects and optimizing the performance of RAG systems. We hope our early exploration can inspire further advancements in engineering, improving and maintaining LLM-driven intelligent software systems for greater efficiency and reliability.
CodeCipher: Learning to Obfuscate Source Code Against LLMs
Oct 08, 2024



While large code language models have made significant strides in AI-assisted coding tasks, there are growing concerns about privacy challenges. The user code is transparent to the cloud LLM service provider, inducing risks of unauthorized training, reading, and execution of the user code. In this paper, we propose CodeCipher, a novel method that perturbs privacy from code while preserving the original response from LLMs. CodeCipher transforms the LLM's embedding matrix so that each row corresponds to a different word in the original matrix, forming a token-to-token confusion mapping for obfuscating source code. The new embedding matrix is optimized by minimizing the task-specific loss function. To tackle the challenge of the discrete and sparse nature of word vector spaces, CodeCipher adopts a discrete optimization strategy that aligns the updated vector to the nearest valid token in the vocabulary before each gradient update. We demonstrate the effectiveness of our approach on three AI-assisted coding tasks including code completion, summarization, and translation. Results show that our model successfully confuses the privacy in source code while preserving the original LLM's performance.
From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging
Oct 02, 2024



While large language models have made significant strides in code generation, the pass rate of the generated code is bottlenecked on subtle errors, often requiring human intervention to pass tests, especially for complex problems. Existing LLM-based debugging systems treat generated programs as monolithic units, failing to address bugs at multiple levels of granularity, from low-level syntax errors to high-level algorithmic flaws. In this paper, we introduce Multi-Granularity Debugger (MGDebugger), a hierarchical code debugger by isolating, identifying, and resolving bugs at various levels of granularity. MGDebugger decomposes problematic code into a hierarchical tree structure of subfunctions, with each level representing a particular granularity of error. During debugging, it analyzes each subfunction and iteratively resolves bugs in a bottom-up manner. To effectively test each subfunction, we propose an LLM-simulated Python executor, which traces code execution and tracks important variable states to pinpoint errors accurately. Extensive experiments demonstrate that MGDebugger outperforms existing debugging systems, achieving an 18.9% improvement in accuracy over seed generations in HumanEval and a 97.6% repair success rate in HumanEvalFix. Furthermore, MGDebugger effectively fixes bugs across different categories and difficulty levels, demonstrating its robustness and effectiveness.
Vortex under Ripplet: An Empirical Study of RAG-enabled Applications
Jul 06, 2024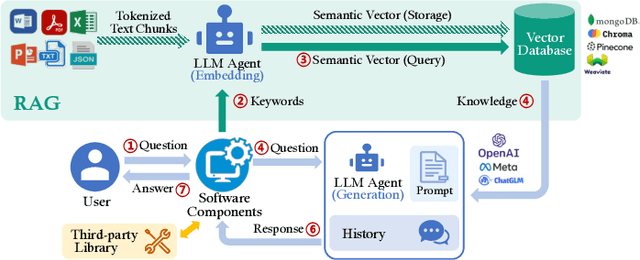
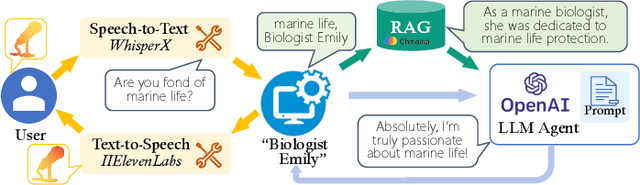


Large language models (LLMs) enhanced by retrieval-augmented generation (RAG) provide effective solutions in various application scenarios. However, developers face challenges in integrating RAG-enhanced LLMs into software systems, due to lack of interface specification, requirements from software context, and complicated system management. In this paper, we manually studied 100 open-source applications that incorporate RAG-enhanced LLMs, and their issue reports. We have found that more than 98% of applications contain multiple integration defects that harm software functionality, efficiency, and security. We have also generalized 19 defect patterns and proposed guidelines to tackle them. We hope this work could aid LLM-enabled software development and motivate future research.
Between Lines of Code: Unraveling the Distinct Patterns of Machine and Human Programmers
Jan 24, 2024



Large language models have catalyzed an unprecedented wave in code generation. While achieving significant advances, they blur the distinctions between machine-and human-authored source code, causing integrity and authenticity issues of software artifacts. Previous methods such as DetectGPT have proven effective in discerning machine-generated texts, but they do not identify and harness the unique patterns of machine-generated code. Thus, its applicability falters when applied to code. In this paper, we carefully study the specific patterns that characterize machine and human-authored code. Through a rigorous analysis of code attributes such as length, lexical diversity, and naturalness, we expose unique pat-terns inherent to each source. We particularly notice that the structural segmentation of code is a critical factor in identifying its provenance. Based on our findings, we propose a novel machine-generated code detection method called DetectCodeGPT, which improves DetectGPT by capturing the distinct structural patterns of code. Diverging from conventional techniques that depend on external LLMs for perturbations, DetectCodeGPT perturbs the code corpus by strategically inserting spaces and newlines, ensuring both efficacy and efficiency. Experiment results show that our approach significantly outperforms state-of-the-art techniques in detecting machine-generated code.