 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGameDevBench: Evaluating Agentic Capabilities Through Game Development
Feb 11, 2026Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.
Reasoning in Trees: Improving Retrieval-Augmented Generation for Multi-Hop Question Answering
Jan 16, 2026Retrieval-Augmented Generation (RAG) has demonstrated significant effectiveness in enhancing large language models (LLMs) for complex multi-hop question answering (QA). For multi-hop QA tasks, current iterative approaches predominantly rely on LLMs to self-guide and plan multi-step exploration paths during retrieval, leading to substantial challenges in maintaining reasoning coherence across steps from inaccurate query decomposition and error propagation. To address these issues, we introduce Reasoning Tree Guided RAG (RT-RAG), a novel hierarchical framework for complex multi-hop QA. RT-RAG systematically decomposes multi-hop questions into explicit reasoning trees, minimizing inaccurate decomposition through structured entity analysis and consensus-based tree selection that clearly separates core queries, known entities, and unknown entities. Subsequently, a bottom-up traversal strategy employs iterative query rewriting and refinement to collect high-quality evidence, thereby mitigating error propagation. Comprehensive experiments show that RT-RAG substantially outperforms state-of-the-art methods by 7.0% F1 and 6.0% EM, demonstrating the effectiveness of RT-RAG in complex multi-hop QA.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025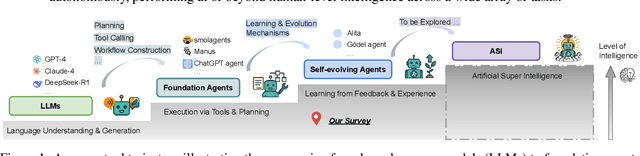

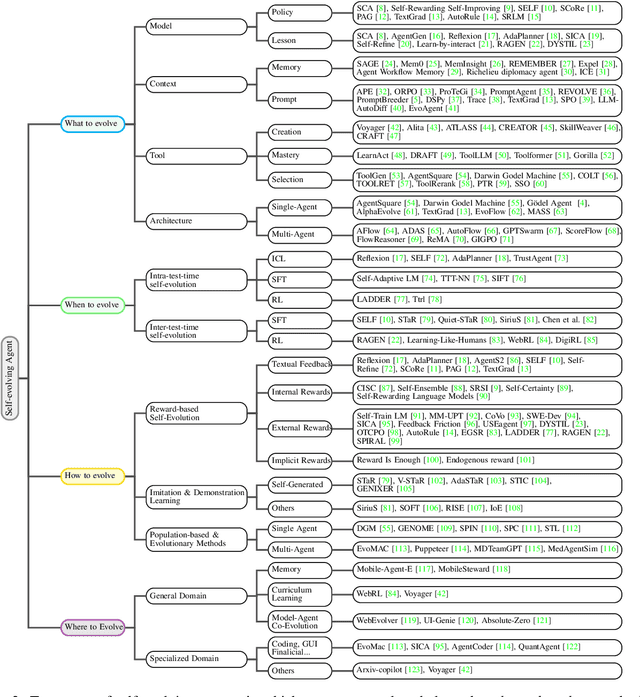
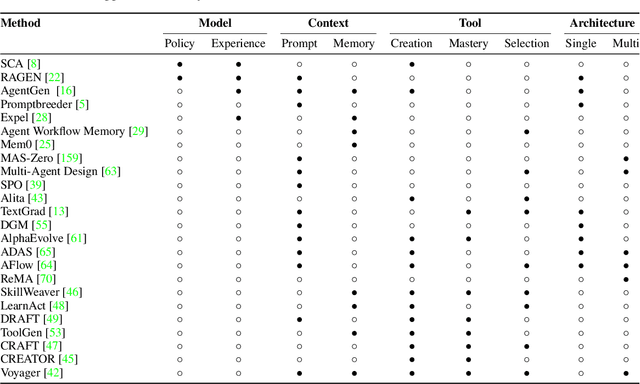
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
AttentionRAG: Attention-Guided Context Pruning in Retrieval-Augmented Generation
Mar 13, 2025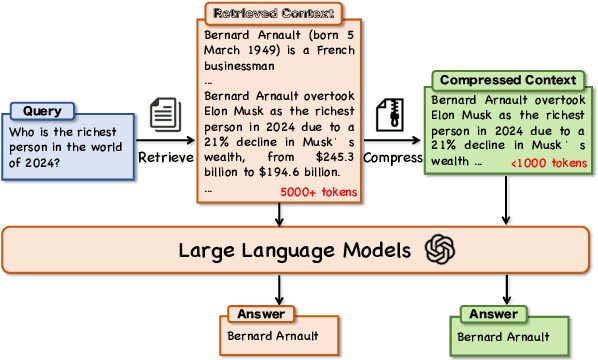



While RAG demonstrates remarkable capabilities in LLM applications, its effectiveness is hindered by the ever-increasing length of retrieved contexts, which introduces information redundancy and substantial computational overhead. Existing context pruning methods, such as LLMLingua, lack contextual awareness and offer limited flexibility in controlling compression rates, often resulting in either insufficient pruning or excessive information loss. In this paper, we propose AttentionRAG, an attention-guided context pruning method for RAG systems. The core idea of AttentionRAG lies in its attention focus mechanism, which reformulates RAG queries into a next-token prediction paradigm. This mechanism isolates the query's semantic focus to a single token, enabling precise and efficient attention calculation between queries and retrieved contexts. Extensive experiments on LongBench and Babilong benchmarks show that AttentionRAG achieves up to 6.3$\times$ context compression while outperforming LLMLingua methods by around 10\% in key metrics.
From Uncertainty to Trust: Enhancing Reliability in Vision-Language Models with Uncertainty-Guided Dropout Decoding
Dec 09, 2024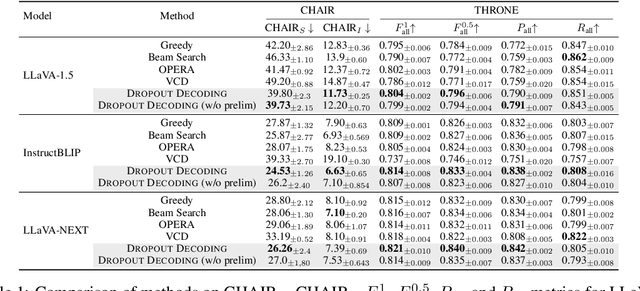

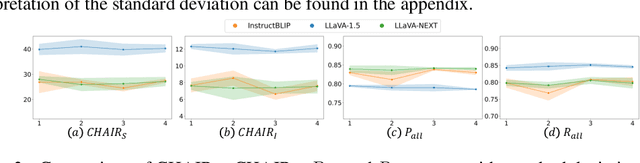

Large vision-language models (LVLMs) demonstrate remarkable capabilities in multimodal tasks but are prone to misinterpreting visual inputs, often resulting in hallucinations and unreliable outputs. To address these challenges, we propose Dropout Decoding, a novel inference-time approach that quantifies the uncertainty of visual tokens and selectively masks uncertain tokens to improve decoding. Our method measures the uncertainty of each visual token by projecting it onto the text space and decomposing it into aleatoric and epistemic components. Specifically, we focus on epistemic uncertainty, which captures perception-related errors more effectively. Inspired by dropout regularization, we introduce uncertainty-guided token dropout, which applies the dropout principle to input visual tokens instead of model parameters, and during inference rather than training. By aggregating predictions from an ensemble of masked decoding contexts, Dropout Decoding robustly mitigates errors arising from visual token misinterpretations. Evaluations on benchmarks including CHAIR, THRONE, and MMBench demonstrate that Dropout Decoding significantly reduces object hallucinations (OH) and enhances both reliability and quality of LVLM outputs across diverse visual contexts.
CodeCipher: Learning to Obfuscate Source Code Against LLMs
Oct 08, 2024



While large code language models have made significant strides in AI-assisted coding tasks, there are growing concerns about privacy challenges. The user code is transparent to the cloud LLM service provider, inducing risks of unauthorized training, reading, and execution of the user code. In this paper, we propose CodeCipher, a novel method that perturbs privacy from code while preserving the original response from LLMs. CodeCipher transforms the LLM's embedding matrix so that each row corresponds to a different word in the original matrix, forming a token-to-token confusion mapping for obfuscating source code. The new embedding matrix is optimized by minimizing the task-specific loss function. To tackle the challenge of the discrete and sparse nature of word vector spaces, CodeCipher adopts a discrete optimization strategy that aligns the updated vector to the nearest valid token in the vocabulary before each gradient update. We demonstrate the effectiveness of our approach on three AI-assisted coding tasks including code completion, summarization, and translation. Results show that our model successfully confuses the privacy in source code while preserving the original LLM's performance.