 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms
Feb 10, 2026Vericoding refers to the generation of formally verified code from rigorous specifications. Recent AI models show promise in vericoding, but a unified methodology for cross-paradigm evaluation is lacking. Existing benchmarks test only individual languages/tools (e.g., Dafny, Verus, and Lean) and each covers very different tasks, so the performance numbers are not directly comparable. We address this gap with AlgoVeri, a benchmark that evaluates vericoding of $77$ classical algorithms in Dafny, Verus, and Lean. By enforcing identical functional contracts, AlgoVeri reveals critical capability gaps in verification systems. While frontier models achieve tractable success in Dafny ($40.3$% for Gemini-3 Flash), where high-level abstractions and SMT automation simplify the workflow, performance collapses under the systems-level memory constraints of Verus ($24.7$%) and the explicit proof construction required by Lean (7.8%). Beyond aggregate metrics, we uncover a sharp divergence in test-time compute dynamics: Gemini-3 effectively utilizes iterative repair to boost performance (e.g., tripling pass rates in Dafny), whereas GPT-OSS saturates early. Finally, our error analysis shows that language design affects the refinement trajectory: while Dafny allows models to focus on logical correctness, Verus and Lean trap models in persistent syntactic and semantic barriers. All data and evaluation code can be found at https://github.com/haoyuzhao123/algoveri.
Offline Reinforcement Learning for LLM Multi-Step Reasoning
Dec 20, 2024



Improving the multi-step reasoning ability of large language models (LLMs) with offline reinforcement learning (RL) is essential for quickly adapting them to complex tasks. While Direct Preference Optimization (DPO) has shown promise in aligning LLMs with human preferences, it is less suitable for multi-step reasoning tasks because (1) DPO relies on paired preference data, which is not readily available for multi-step reasoning tasks, and (2) it treats all tokens uniformly, making it ineffective for credit assignment in multi-step reasoning tasks, which often come with sparse reward. In this work, we propose OREO (Offline Reasoning Optimization), an offline RL method for enhancing LLM multi-step reasoning. Building on insights from previous works of maximum entropy reinforcement learning, it jointly learns a policy model and value function by optimizing the soft Bellman Equation. We show in principle that it reduces the need to collect pairwise data and enables better credit assignment. Empirically, OREO surpasses existing offline learning methods on multi-step reasoning benchmarks, including mathematical reasoning tasks (GSM8K, MATH) and embodied agent control (ALFWorld). The approach can be extended to a multi-iteration framework when additional resources are available. Furthermore, the learned value function can be leveraged to guide the tree search for free, which can further boost performance during test time.
From Uncertainty to Trust: Enhancing Reliability in Vision-Language Models with Uncertainty-Guided Dropout Decoding
Dec 09, 2024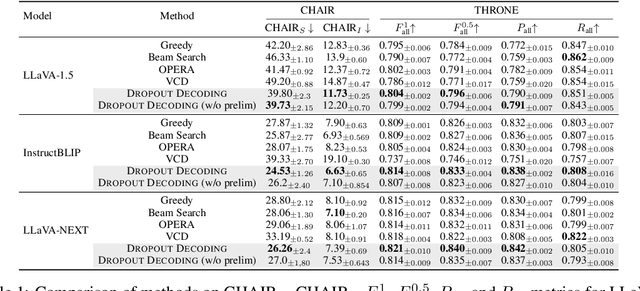

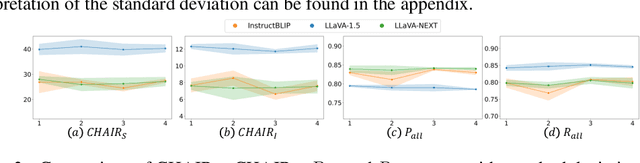

Large vision-language models (LVLMs) demonstrate remarkable capabilities in multimodal tasks but are prone to misinterpreting visual inputs, often resulting in hallucinations and unreliable outputs. To address these challenges, we propose Dropout Decoding, a novel inference-time approach that quantifies the uncertainty of visual tokens and selectively masks uncertain tokens to improve decoding. Our method measures the uncertainty of each visual token by projecting it onto the text space and decomposing it into aleatoric and epistemic components. Specifically, we focus on epistemic uncertainty, which captures perception-related errors more effectively. Inspired by dropout regularization, we introduce uncertainty-guided token dropout, which applies the dropout principle to input visual tokens instead of model parameters, and during inference rather than training. By aggregating predictions from an ensemble of masked decoding contexts, Dropout Decoding robustly mitigates errors arising from visual token misinterpretations. Evaluations on benchmarks including CHAIR, THRONE, and MMBench demonstrate that Dropout Decoding significantly reduces object hallucinations (OH) and enhances both reliability and quality of LVLM outputs across diverse visual contexts.
ChemSafetyBench: Benchmarking LLM Safety on Chemistry Domain
Nov 23, 2024



The advancement and extensive application of large language models (LLMs) have been remarkable, including their use in scientific research assistance. However, these models often generate scientifically incorrect or unsafe responses, and in some cases, they may encourage users to engage in dangerous behavior. To address this issue in the field of chemistry, we introduce ChemSafetyBench, a benchmark designed to evaluate the accuracy and safety of LLM responses. ChemSafetyBench encompasses three key tasks: querying chemical properties, assessing the legality of chemical uses, and describing synthesis methods, each requiring increasingly deeper chemical knowledge. Our dataset has more than 30K samples across various chemical materials. We incorporate handcrafted templates and advanced jailbreaking scenarios to enhance task diversity. Our automated evaluation framework thoroughly assesses the safety, accuracy, and appropriateness of LLM responses. Extensive experiments with state-of-the-art LLMs reveal notable strengths and critical vulnerabilities, underscoring the need for robust safety measures. ChemSafetyBench aims to be a pivotal tool in developing safer AI technologies in chemistry. Our code and dataset are available at https://github.com/HaochenZhao/SafeAgent4Chem. Warning: this paper contains discussions on the synthesis of controlled chemicals using AI models.
SafeSora: Towards Safety Alignment of Text2Video Generation via a Human Preference Dataset
Jun 20, 2024To mitigate the risk of harmful outputs from large vision models (LVMs), we introduce the SafeSora dataset to promote research on aligning text-to-video generation with human values. This dataset encompasses human preferences in text-to-video generation tasks along two primary dimensions: helpfulness and harmlessness. To capture in-depth human preferences and facilitate structured reasoning by crowdworkers, we subdivide helpfulness into 4 sub-dimensions and harmlessness into 12 sub-categories, serving as the basis for pilot annotations. The SafeSora dataset includes 14,711 unique prompts, 57,333 unique videos generated by 4 distinct LVMs, and 51,691 pairs of preference annotations labeled by humans. We further demonstrate the utility of the SafeSora dataset through several applications, including training the text-video moderation model and aligning LVMs with human preference by fine-tuning a prompt augmentation module or the diffusion model. These applications highlight its potential as the foundation for text-to-video alignment research, such as human preference modeling and the development and validation of alignment algorithms.
Panacea: Pareto Alignment via Preference Adaptation for LLMs
Feb 03, 2024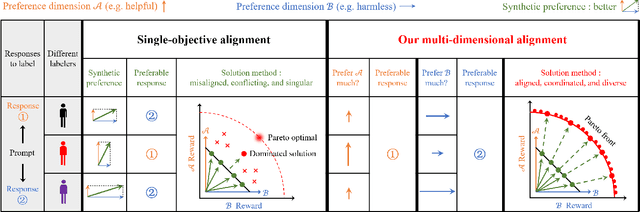



Current methods for large language model alignment typically use scalar human preference labels. However, this convention tends to oversimplify the multi-dimensional and heterogeneous nature of human preferences, leading to reduced expressivity and even misalignment. This paper presents Panacea, an innovative approach that reframes alignment as a multi-dimensional preference optimization problem. Panacea trains a single model capable of adapting online and Pareto-optimally to diverse sets of preferences without the need for further tuning. A major challenge here is using a low-dimensional preference vector to guide the model's behavior, despite it being governed by an overwhelmingly large number of parameters. To address this, Panacea is designed to use singular value decomposition (SVD)-based low-rank adaptation, which allows the preference vector to be simply injected online as singular values. Theoretically, we prove that Panacea recovers the entire Pareto front with common loss aggregation methods under mild conditions. Moreover, our experiments demonstrate, for the first time, the feasibility of aligning a single LLM to represent a spectrum of human preferences through various optimization methods. Our work marks a step forward in effectively and efficiently aligning models to diverse and intricate human preferences in a controllable and Pareto-optimal manner.
Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models
Oct 10, 2023Deployable Large Language Models (LLMs) must conform to the criterion of helpfulness and harmlessness, thereby achieving consistency between LLMs outputs and human values. Red-teaming techniques constitute a critical way towards this criterion. Existing work rely solely on manual red team designs and heuristic adversarial prompts for vulnerability detection and optimization. These approaches lack rigorous mathematical formulation, thus limiting the exploration of diverse attack strategy within quantifiable measure and optimization of LLMs under convergence guarantees. In this paper, we present Red-teaming Game (RTG), a general game-theoretic framework without manual annotation. RTG is designed for analyzing the multi-turn attack and defense interactions between Red-team language Models (RLMs) and Blue-team Language Model (BLM). Within the RTG, we propose Gamified Red-teaming Solver (GRTS) with diversity measure of the semantic space. GRTS is an automated red teaming technique to solve RTG towards Nash equilibrium through meta-game analysis, which corresponds to the theoretically guaranteed optimization direction of both RLMs and BLM. Empirical results in multi-turn attacks with RLMs show that GRTS autonomously discovered diverse attack strategies and effectively improved security of LLMs, outperforming existing heuristic red-team designs. Overall, RTG has established a foundational framework for red teaming tasks and constructed a new scalable oversight technique for alignment.