 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Uncertainty to Trust: Enhancing Reliability in Vision-Language Models with Uncertainty-Guided Dropout Decoding
Paper and Code
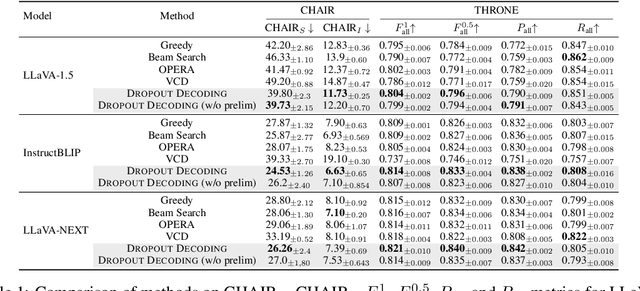

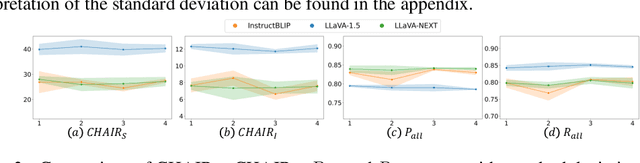

Large vision-language models (LVLMs) demonstrate remarkable capabilities in multimodal tasks but are prone to misinterpreting visual inputs, often resulting in hallucinations and unreliable outputs. To address these challenges, we propose Dropout Decoding, a novel inference-time approach that quantifies the uncertainty of visual tokens and selectively masks uncertain tokens to improve decoding. Our method measures the uncertainty of each visual token by projecting it onto the text space and decomposing it into aleatoric and epistemic components. Specifically, we focus on epistemic uncertainty, which captures perception-related errors more effectively. Inspired by dropout regularization, we introduce uncertainty-guided token dropout, which applies the dropout principle to input visual tokens instead of model parameters, and during inference rather than training. By aggregating predictions from an ensemble of masked decoding contexts, Dropout Decoding robustly mitigates errors arising from visual token misinterpretations. Evaluations on benchmarks including CHAIR, THRONE, and MMBench demonstrate that Dropout Decoding significantly reduces object hallucinations (OH) and enhances both reliability and quality of LVLM outputs across diverse visual contexts.