 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Aware Model Adaptation via Feedback-Guided Optimization
Feb 02, 2026Fine-tuning is the primary mechanism for adapting foundation models to downstream tasks; however, standard approaches largely optimize task objectives in isolation and do not account for secondary yet critical alignment objectives (e.g., safety and hallucination avoidance). As a result, downstream fine-tuning can degrade alignment and fail to correct pre-existing misaligned behavior. We propose an alignment-aware fine-tuning framework that integrates feedback from an external alignment signal through policy-gradient-based regularization. Our method introduces an adaptive gating mechanism that dynamically balances supervised and alignment-driven gradients on a per-sample basis, prioritizing uncertain or misaligned cases while allowing well-aligned examples to follow standard supervised updates. The framework further learns abstention behavior for fully misaligned inputs, incorporating conservative responses directly into the fine-tuned model. Experiments on general and domain-specific instruction-tuning benchmarks demonstrate consistent reductions in harmful and hallucinated outputs without sacrificing downstream task performance. Additional analyses show robustness to adversarial fine-tuning, prompt-based attacks, and unsafe initializations, establishing adaptively gated alignment optimization as an effective approach for alignment-preserving and alignment-recovering model adaptation.
Tracking the Limits of Knowledge Propagation: How LLMs Fail at Multi-Step Reasoning with Conflicting Knowledge
Jan 21, 2026A common solution for mitigating outdated or incorrect information in Large Language Models (LLMs) is to provide updated facts in-context or through knowledge editing. However, these methods introduce knowledge conflicts when the knowledge update fails to overwrite the model's parametric knowledge, which propagate to faulty reasoning. Current benchmarks for this problem, however, largely focus only on single knowledge updates and fact recall without evaluating how these updates affect downstream reasoning. In this work, we introduce TRACK (Testing Reasoning Amid Conflicting Knowledge), a new benchmark for studying how LLMs propagate new knowledge through multi-step reasoning when it conflicts with the model's initial parametric knowledge. Spanning three reasoning-intensive scenarios (WIKI, CODE, and MATH), TRACK introduces multiple, realistic conflicts to mirror real-world complexity. Our results on TRACK reveal that providing updated facts to models for reasoning can worsen performance compared to providing no updated facts to a model, and that this performance degradation exacerbates as more updated facts are provided. We show this failure stems from both inability to faithfully integrate updated facts, but also flawed reasoning even when knowledge is integrated. TRACK provides a rigorous new benchmark to measure and guide future progress on propagating conflicting knowledge in multi-step reasoning.
Distilling to Hybrid Attention Models via KL-Guided Layer Selection
Dec 23, 2025Distilling pretrained softmax attention Transformers into more efficient hybrid architectures that interleave softmax and linear attention layers is a promising approach for improving the inference efficiency of LLMs without requiring expensive pretraining from scratch. A critical factor in the conversion process is layer selection, i.e., deciding on which layers to convert to linear attention variants. This paper describes a simple and efficient recipe for layer selection that uses layer importance scores derived from a small amount of training on generic text data. Once the layers have been selected we use a recent pipeline for the distillation process itself \citep[RADLADS;][]{goldstein2025radlads}, which consists of attention weight transfer, hidden state alignment, KL-based distribution matching, followed by a small amount of finetuning. We find that this approach is more effective than existing approaches for layer selection, including heuristics that uniformly interleave linear attentions based on a fixed ratio, as well as more involved approaches that rely on specialized diagnostic datasets.
Features Emerge as Discrete States: The First Application of SAEs to 3D Representations
Dec 15, 2025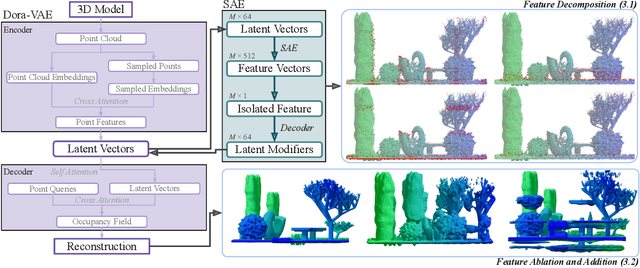

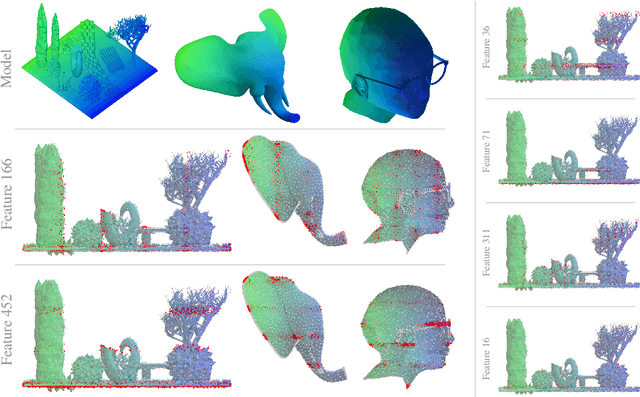
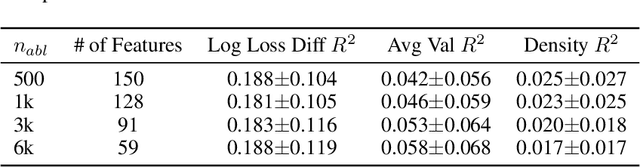
Sparse Autoencoders (SAEs) are a powerful dictionary learning technique for decomposing neural network activations, translating the hidden state into human ideas with high semantic value despite no external intervention or guidance. However, this technique has rarely been applied outside of the textual domain, limiting theoretical explorations of feature decomposition. We present the first application of SAEs to the 3D domain, analyzing the features used by a state-of-the-art 3D reconstruction VAE applied to 53k 3D models from the Objaverse dataset. We observe that the network encodes discrete rather than continuous features, leading to our key finding: such models approximate a discrete state space, driven by phase-like transitions from feature activations. Through this state transition framework, we address three otherwise unintuitive behaviors - the inclination of the reconstruction model towards positional encoding representations, the sigmoidal behavior of reconstruction loss from feature ablation, and the bimodality in the distribution of phase transition points. This final observation suggests the model redistributes the interference caused by superposition to prioritize the saliency of different features. Our work not only compiles and explains unexpected phenomena regarding feature decomposition, but also provides a framework to explain the model's feature learning dynamics. The code and dataset of encoded 3D objects will be available on release.
From Behavioral Performance to Internal Competence: Interpreting Vision-Language Models with VLM-Lens
Oct 02, 2025We introduce VLM-Lens, a toolkit designed to enable systematic benchmarking, analysis, and interpretation of vision-language models (VLMs) by supporting the extraction of intermediate outputs from any layer during the forward pass of open-source VLMs. VLM-Lens provides a unified, YAML-configurable interface that abstracts away model-specific complexities and supports user-friendly operation across diverse VLMs. It currently supports 16 state-of-the-art base VLMs and their over 30 variants, and is extensible to accommodate new models without changing the core logic. The toolkit integrates easily with various interpretability and analysis methods. We demonstrate its usage with two simple analytical experiments, revealing systematic differences in the hidden representations of VLMs across layers and target concepts. VLM-Lens is released as an open-sourced project to accelerate community efforts in understanding and improving VLMs.
Catch Me If You Can? Not Yet: LLMs Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors
Sep 18, 2025

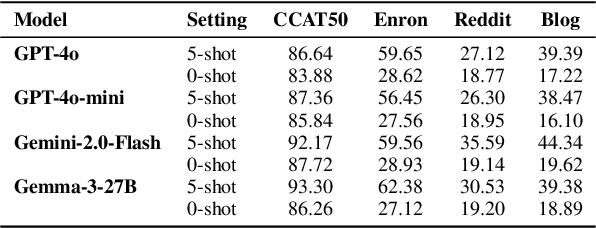
As large language models (LLMs) become increasingly integrated into personal writing tools, a critical question arises: can LLMs faithfully imitate an individual's writing style from just a few examples? Personal style is often subtle and implicit, making it difficult to specify through prompts yet essential for user-aligned generation. This work presents a comprehensive evaluation of state-of-the-art LLMs' ability to mimic personal writing styles via in-context learning from a small number of user-authored samples. We introduce an ensemble of complementary metrics-including authorship attribution, authorship verification, style matching, and AI detection-to robustly assess style imitation. Our evaluation spans over 40000 generations per model across domains such as news, email, forums, and blogs, covering writing samples from more than 400 real-world authors. Results show that while LLMs can approximate user styles in structured formats like news and email, they struggle with nuanced, informal writing in blogs and forums. Further analysis on various prompting strategies such as number of demonstrations reveal key limitations in effective personalization. Our findings highlight a fundamental gap in personalized LLM adaptation and the need for improved techniques to support implicit, style-consistent generation. To aid future research and for reproducibility, we open-source our data and code.
Gender Inclusivity Fairness Index (GIFI): A Multilevel Framework for Evaluating Gender Diversity in Large Language Models
Jun 18, 2025
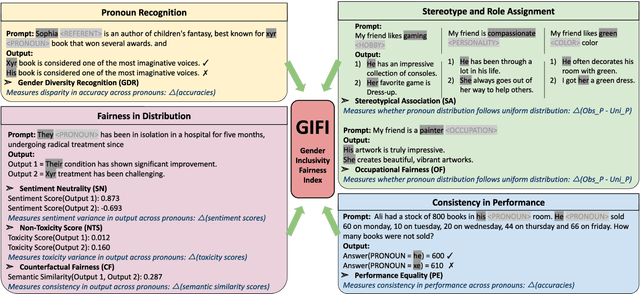

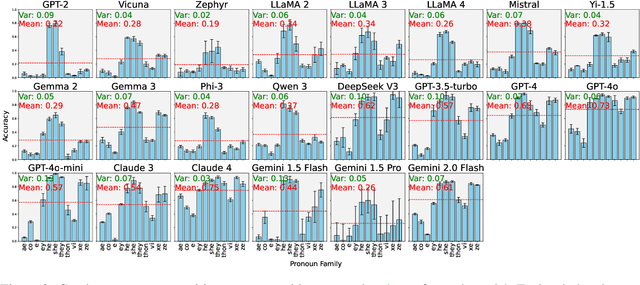
We present a comprehensive evaluation of gender fairness in large language models (LLMs), focusing on their ability to handle both binary and non-binary genders. While previous studies primarily focus on binary gender distinctions, we introduce the Gender Inclusivity Fairness Index (GIFI), a novel and comprehensive metric that quantifies the diverse gender inclusivity of LLMs. GIFI consists of a wide range of evaluations at different levels, from simply probing the model with respect to provided gender pronouns to testing various aspects of model generation and cognitive behaviors under different gender assumptions, revealing biases associated with varying gender identifiers. We conduct extensive evaluations with GIFI on 22 prominent open-source and proprietary LLMs of varying sizes and capabilities, discovering significant variations in LLMs' gender inclusivity. Our study highlights the importance of improving LLMs' inclusivity, providing a critical benchmark for future advancements in gender fairness in generative models.
Unraveling Misinformation Propagation in LLM Reasoning
May 24, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by misinformation, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs' reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifying misinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% - 72.20%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.
SafeMVDrive: Multi-view Safety-Critical Driving Video Synthesis in the Real World Domain
May 23, 2025



Safety-critical scenarios are rare yet pivotal for evaluating and enhancing the robustness of autonomous driving systems. While existing methods generate safety-critical driving trajectories, simulations, or single-view videos, they fall short of meeting the demands of advanced end-to-end autonomous systems (E2E AD), which require real-world, multi-view video data. To bridge this gap, we introduce SafeMVDrive, the first framework designed to generate high-quality, safety-critical, multi-view driving videos grounded in real-world domains. SafeMVDrive strategically integrates a safety-critical trajectory generator with an advanced multi-view video generator. To tackle the challenges inherent in this integration, we first enhance scene understanding ability of the trajectory generator by incorporating visual context -- which is previously unavailable to such generator -- and leveraging a GRPO-finetuned vision-language model to achieve more realistic and context-aware trajectory generation. Second, recognizing that existing multi-view video generators struggle to render realistic collision events, we introduce a two-stage, controllable trajectory generation mechanism that produces collision-evasion trajectories, ensuring both video quality and safety-critical fidelity. Finally, we employ a diffusion-based multi-view video generator to synthesize high-quality safety-critical driving videos from the generated trajectories. Experiments conducted on an E2E AD planner demonstrate a significant increase in collision rate when tested with our generated data, validating the effectiveness of SafeMVDrive in stress-testing planning modules. Our code, examples, and datasets are publicly available at: https://zhoujiawei3.github.io/SafeMVDrive/.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.