 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Representing Algorithms With Chain-of-Thought Transformers
Jun 18, 2026The increasing popularity of \emph{reasoning} models -- language models that output a series of reasoning or thought tokens before producing an answer -- is justified, in part, by theoretical results showing that chain-of-thought (CoT) transformers can simulate Turing machines, and thus perform arbitrary computation. However, the Turing machine, while suitable for complexity-theoretic analysis, is not convenient, intuitive, or efficient for discussing algorithms. Algorithms are typically designed and analyzed at a higher level of abstraction, captured by the \emph{Word RAM} model with random-access memory and unit-cost operations on $\bigO(\log n)$-bit words. As a result, Word RAM algorithms can be substantially more efficient than their Turing machine counterparts, raising the question: \emph{Can CoT transformers efficiently simulate Word RAM algorithms?} For instance, can they sort $n$ items in $\bigO(n \log n)$ steps or run Dijkstra's algorithm in $\bigO(E + V \log V)$ steps? We answer affirmatively, up to poly-logarithmic overhead. We first establish this for finite-precision transformers with poly-logarithmic width and rightmost unique hard attention, then strengthen the result to two more practical settings with finite width and log-precision: \emph{continuous} CoT, where reasoning takes the form of vectors rather than tokens, and a \emph{hybrid} architecture in which transformer layers sit atop a recurrent (linear RNN) layer. In all three cases, we find that CoT \emph{can} efficiently simulate any Word RAM algorithm with only a poly-logarithmic overhead in $n$. This overhead reduces to log-square when the Word RAM has a ``flat'' instruction set, and only logarithmic for multiplication-free flat instructions -- in stark contrast to known CoT simulations of Turing machines, which require quadratic overhead over Word RAM.
Training Transformers as a Universal Computer
Apr 28, 2026We demonstrate that a small transformer can learn to execute programs in MicroPy, a simplified yet computationally universal programming language. Given procedure definitions together with an expression to evaluate, the transformer predicts small-step execution using PENCIL scaffolding for space-efficient execution within a bounded context window. After training on randomly generated, meaningless MicroPy programs, the learned transformer generalizes to various human-written programs including bit copying and flipping, binary addition and multiplication, and SAT verification and solving. We note that the trained model can achieve out-of-distribution generalization; i.e., evaluate novel programs from distribution on programs. Since MicroPy can express any computation, our results provide empirical evidence that a standard transformer can be trained to act as a universal computer.
Olmo Hybrid: From Theory to Practice and Back
Apr 07, 2026Recent work has demonstrated the potential of non-transformer language models, especially linear recurrent neural networks (RNNs) and hybrid models that mix recurrence and attention. Yet there is no consensus on whether the potential benefits of these new architectures justify the risk and effort of scaling them up. To address this, we provide evidence for the advantages of hybrid models over pure transformers on several fronts. First, theoretically, we show that hybrid models do not merely inherit the expressivity of transformers and linear RNNs, but can express tasks beyond both, such as code execution. Putting this theory to practice, we train Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B but with the sliding window layers replaced by Gated DeltaNet layers. We show that Olmo Hybrid outperforms Olmo 3 across standard pretraining and mid-training evaluations, demonstrating the benefit of hybrid models in a controlled, large-scale setting. We find that the hybrid model scales significantly more efficiently than the transformer, explaining its higher performance. However, its unclear why greater expressivity on specific formal problems should result in better scaling or superior performance on downstream tasks unrelated to those problems. To explain this apparent gap, we return to theory and argue why increased expressivity should translate to better scaling efficiency, completing the loop. Overall, our results suggest that hybrid models mixing attention and recurrent layers are a powerful extension to the language modeling paradigm: not merely to reduce memory during inference, but as a fundamental way to obtain more expressive models that scale better during pretraining.
Why Are Linear RNNs More Parallelizable?
Mar 05, 2026The community is increasingly exploring linear RNNs (LRNNs) as language models, motivated by their expressive power and parallelizability. While prior work establishes the expressivity benefits of LRNNs over transformers, it is unclear what makes LRNNs -- but not traditional, nonlinear RNNs -- as easy to parallelize in practice as transformers. We answer this question by providing a tight connection between types of RNNs and standard complexity classes. We show that LRNNs can be viewed as log-depth (bounded fan-in) arithmetic circuits, which represents only a slight depth overhead relative to log-depth boolean circuits that transformers admit. Furthermore, we show that nonlinear RNNs can solve $\mathsf{L}$-complete problems (and even $\mathsf{P}$-complete ones, under polynomial precision), revealing a fundamental barrier to parallelizing them as efficiently as transformers. Our theory also identifies fine-grained expressivity differences between recent popular LRNN variants: permutation-diagonal LRNNs are $\mathsf{NC}^1$-complete whereas diagonal-plus-low-rank LRNNs are more expressive ($\mathsf{PNC}^1$-complete). We provide further insight by associating each type of RNN with a corresponding automata-theoretic model that it can simulate. Together, our results reveal fundamental tradeoffs between nonlinear RNNs and different variants of LRNNs, providing a foundation for designing LLM architectures that achieve an optimal balance between expressivity and parallelism.
Reverso: Efficient Time Series Foundation Models for Zero-shot Forecasting
Feb 19, 2026Learning time series foundation models has been shown to be a promising approach for zero-shot time series forecasting across diverse time series domains. Insofar as scaling has been a critical driver of performance of foundation models in other modalities such as language and vision, much recent work on time series foundation modeling has focused on scaling. This has resulted in time series foundation models with hundreds of millions of parameters that are, while performant, inefficient and expensive to use in practice. This paper describes a simple recipe for learning efficient foundation models for zero-shot time series forecasting that are orders of magnitude smaller. We show that large-scale transformers are not necessary: small hybrid models that interleave long convolution and linear RNN layers (in particular DeltaNet layers) can match the performance of larger transformer-based models while being more than a hundred times smaller. We also describe several data augmentation and inference strategies that further improve performance. This recipe results in Reverso, a family of efficient time series foundation models for zero-shot forecasting that significantly push the performance-efficiency Pareto frontier.
Distilling to Hybrid Attention Models via KL-Guided Layer Selection
Dec 23, 2025Distilling pretrained softmax attention Transformers into more efficient hybrid architectures that interleave softmax and linear attention layers is a promising approach for improving the inference efficiency of LLMs without requiring expensive pretraining from scratch. A critical factor in the conversion process is layer selection, i.e., deciding on which layers to convert to linear attention variants. This paper describes a simple and efficient recipe for layer selection that uses layer importance scores derived from a small amount of training on generic text data. Once the layers have been selected we use a recent pipeline for the distillation process itself \citep[RADLADS;][]{goldstein2025radlads}, which consists of attention weight transfer, hidden state alignment, KL-based distribution matching, followed by a small amount of finetuning. We find that this approach is more effective than existing approaches for layer selection, including heuristics that uniformly interleave linear attentions based on a fixed ratio, as well as more involved approaches that rely on specialized diagnostic datasets.
DIY-MKG: An LLM-Based Polyglot Language Learning System
Jul 02, 2025Existing language learning tools, even those powered by Large Language Models (LLMs), often lack support for polyglot learners to build linguistic connections across vocabularies in multiple languages, provide limited customization for individual learning paces or needs, and suffer from detrimental cognitive offloading. To address these limitations, we design Do-It-Yourself Multilingual Knowledge Graph (DIY-MKG), an open-source system that supports polyglot language learning. DIY-MKG allows the user to build personalized vocabulary knowledge graphs, which are constructed by selective expansion with related words suggested by an LLM. The system further enhances learning through rich annotation capabilities and an adaptive review module that leverages LLMs for dynamic, personalized quiz generation. In addition, DIY-MKG allows users to flag incorrect quiz questions, simultaneously increasing user engagement and providing a feedback loop for prompt refinement. Our evaluation of LLM-based components in DIY-MKG shows that vocabulary expansion is reliable and fair across multiple languages, and that the generated quizzes are highly accurate, validating the robustness of DIY-MKG.
How Instruction and Reasoning Data shape Post-Training: Data Quality through the Lens of Layer-wise Gradients
Apr 14, 2025

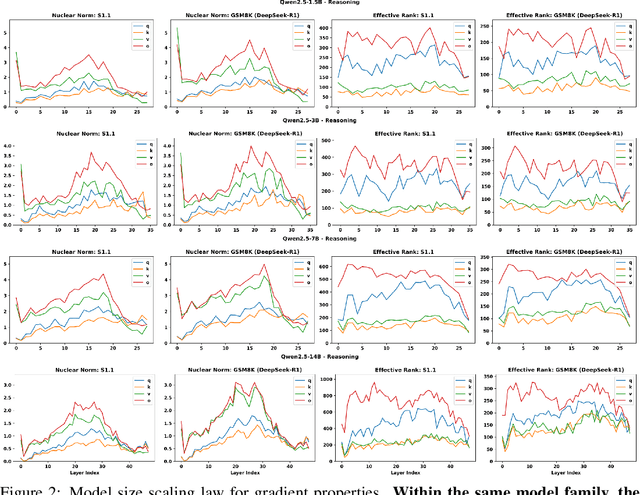

As the post-training of large language models (LLMs) advances from instruction-following to complex reasoning tasks, understanding how different data affect finetuning dynamics remains largely unexplored. In this paper, we present a spectral analysis of layer-wise gradients induced by low/high-quality instruction and reasoning data for LLM post-training. Our analysis reveals that widely-studied metrics for data evaluation, e.g., IFD, InsTag, Difficulty, and Reward, can be explained and unified by spectral properties computed from gradients' singular value decomposition (SVD). Specifically, higher-quality data are usually associated with lower nuclear norms and higher effective ranks. Notably, effective rank exhibits better robustness and resolution than nuclear norm in capturing subtle quality differences. For example, reasoning data achieves substantially higher effective ranks than instruction data, implying richer gradient structures on more complex tasks. Our experiments also highlight that models within the same family share similar gradient patterns regardless of their sizes, whereas different model families diverge significantly. Providing a unified view on the effects of data quality across instruction and reasoning data, this work illuminates the interplay between data quality and training stability, shedding novel insights into developing better data exploration strategies for post-training.
SPICE: A Synergistic, Precise, Iterative, and Customizable Image Editing Workflow
Apr 13, 2025Recent prompt-based image editing models have demonstrated impressive prompt-following capability at structural editing tasks. However, existing models still fail to perform local edits, follow detailed editing prompts, or maintain global image quality beyond a single editing step. To address these challenges, we introduce SPICE, a training-free workflow that accepts arbitrary resolutions and aspect ratios, accurately follows user requirements, and improves image quality consistently during more than 100 editing steps. By synergizing the strengths of a base diffusion model and a Canny edge ControlNet model, SPICE robustly handles free-form editing instructions from the user. SPICE outperforms state-of-the-art baselines on a challenging realistic image-editing dataset consisting of semantic editing (object addition, removal, replacement, and background change), stylistic editing (texture changes), and structural editing (action change) tasks. Not only does SPICE achieve the highest quantitative performance according to standard evaluation metrics, but it is also consistently preferred by users over existing image-editing methods. We release the workflow implementation for popular diffusion model Web UIs to support further research and artistic exploration.
Context-Efficient Retrieval with Factual Decomposition
Mar 25, 2025There has recently been considerable interest in incorporating information retrieval into large language models (LLMs). Retrieval from a dynamically expanding external corpus of text allows a model to incorporate current events and can be viewed as a form of episodic memory. Here we demonstrate that pre-processing the external corpus into semi-structured ''atomic facts'' makes retrieval more efficient. More specifically, we demonstrate that our particular form of atomic facts improves performance on various question answering tasks when the amount of retrieved text is limited. Limiting the amount of retrieval reduces the size of the context and improves inference efficiency.