 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Happened in LLMs Layers when Trained for Fast vs. Slow Thinking: A Gradient Perspective
Paper and Code

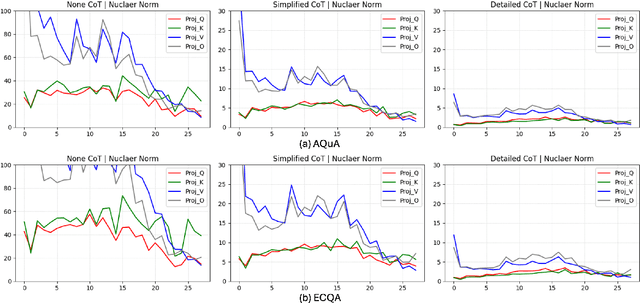


What makes a difference in the post-training of LLMs? We investigate the training patterns of different layers in large language models (LLMs), through the lens of gradient, when training with different responses and initial models. We are specifically interested in how fast vs. slow thinking affects the layer-wise gradients, given the recent popularity of training LLMs on reasoning paths such as chain-of-thoughts (CoT) and process rewards. In our study, fast thinking without CoT leads to larger gradients and larger differences of gradients across layers than slow thinking (Detailed CoT), indicating the learning stability brought by the latter. Moreover, pre-trained LLMs are less affected by the instability of fast thinking than instruction-tuned LLMs. Additionally, we study whether the gradient patterns can reflect the correctness of responses when training different LLMs using slow vs. fast thinking paths. The results show that the gradients of slow thinking can distinguish correct and irrelevant reasoning paths. As a comparison, we conduct similar gradient analyses on non-reasoning knowledge learning tasks, on which, however, trivially increasing the response length does not lead to similar behaviors of slow thinking. Our study strengthens fundamental understandings of LLM training and sheds novel insights on its efficiency and stability, which pave the way towards building a generalizable System-2 agent. Our code, data, and gradient statistics can be found in: https://github.com/MingLiiii/Layer_Gradient.