 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching an Agent to Sketch One Part at a Time
Mar 19, 2026We develop a method for producing vector sketches one part at a time. To do this, we train a multi-modal language model-based agent using a novel multi-turn process-reward reinforcement learning following supervised fine-tuning. Our approach is enabled by a new dataset we call ControlSketch-Part, containing rich part-level annotations for sketches, obtained using a novel, generic automatic annotation pipeline that segments vector sketches into semantic parts and assigns paths to parts with a structured multi-stage labeling process. Our results indicate that incorporating structured part-level data and providing agent with the visual feedback through the process enables interpretable, controllable, and locally editable text-to-vector sketch generation.
Context-Efficient Retrieval with Factual Decomposition
Mar 25, 2025There has recently been considerable interest in incorporating information retrieval into large language models (LLMs). Retrieval from a dynamically expanding external corpus of text allows a model to incorporate current events and can be viewed as a form of episodic memory. Here we demonstrate that pre-processing the external corpus into semi-structured ''atomic facts'' makes retrieval more efficient. More specifically, we demonstrate that our particular form of atomic facts improves performance on various question answering tasks when the amount of retrieved text is limited. Limiting the amount of retrieval reduces the size of the context and improves inference efficiency.
Reducing the Scope of Language Models with Circuit Breakers
Oct 28, 2024Language models are now deployed in a wide variety of user-facing applications, often for specific purposes like answering questions about documentation or acting as coding assistants. As these models are intended for particular purposes, they should not be able to answer irrelevant queries like requests for poetry or questions about physics, or even worse, queries that can only be answered by humans like sensitive company policies. Instead we would like them to only answer queries corresponding to desired behavior and refuse all other requests, which we refer to as scoping. We find that, despite the use of system prompts, two representative language models can be poorly scoped and respond to queries they should not be addressing. We then conduct a comprehensive empirical evaluation of methods which could be used for scoping the behavior of language models. Among many other results, we show that a recently-proposed method for general alignment, Circuit Breakers (CB), can be adapted to scope language models to very specific tasks like sentiment analysis or summarization or even tasks with finer-grained scoping (e.g. summarizing only news articles). When compared to standard methods like fine-tuning or preference learning, CB is more robust both for out of distribution tasks, and to adversarial prompting techniques. We also show that layering SFT and CB together often results in the best of both worlds: improved performance only on relevant queries, while rejecting irrelevant ones.
Approaching Deep Learning through the Spectral Dynamics of Weights
Aug 21, 2024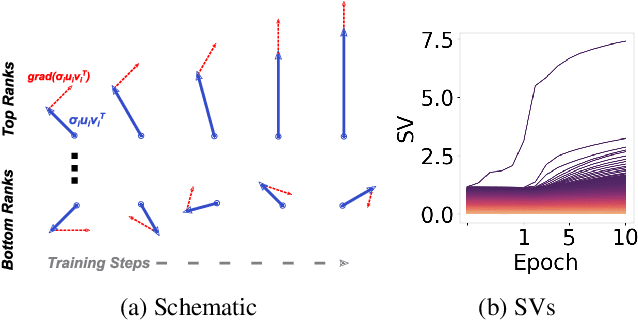
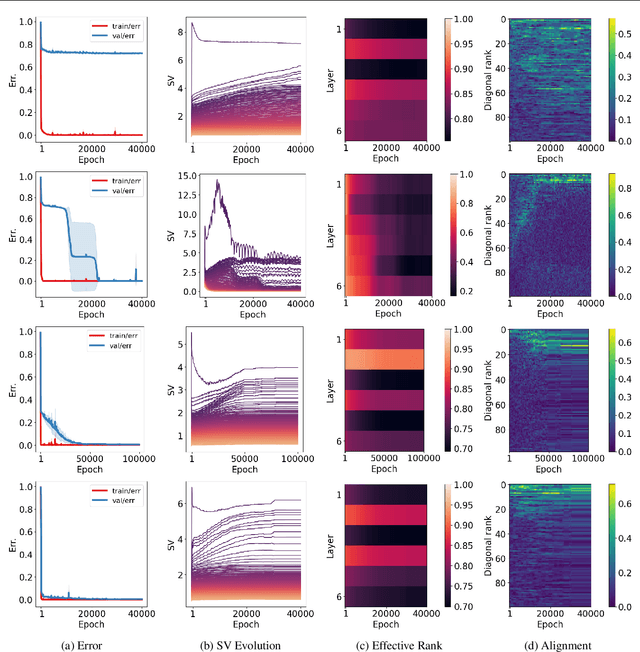
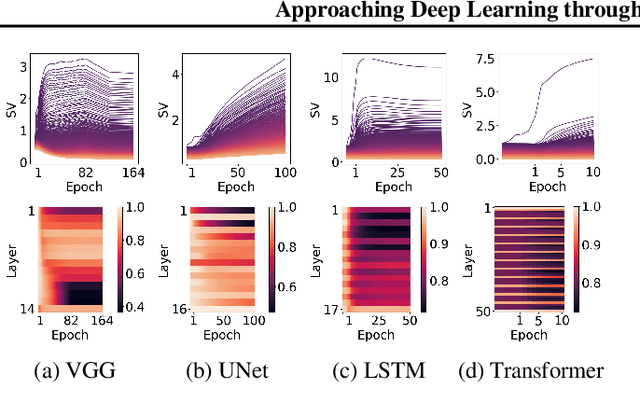
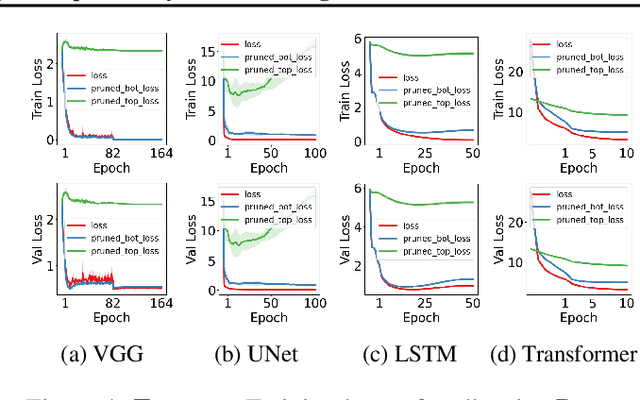
We propose an empirical approach centered on the spectral dynamics of weights -- the behavior of singular values and vectors during optimization -- to unify and clarify several phenomena in deep learning. We identify a consistent bias in optimization across various experiments, from small-scale ``grokking'' to large-scale tasks like image classification with ConvNets, image generation with UNets, speech recognition with LSTMs, and language modeling with Transformers. We also demonstrate that weight decay enhances this bias beyond its role as a norm regularizer, even in practical systems. Moreover, we show that these spectral dynamics distinguish memorizing networks from generalizing ones, offering a novel perspective on this longstanding conundrum. Additionally, we leverage spectral dynamics to explore the emergence of well-performing sparse subnetworks (lottery tickets) and the structure of the loss surface through linear mode connectivity. Our findings suggest that spectral dynamics provide a coherent framework to better understand the behavior of neural networks across diverse settings.
Deciphering 'What' and 'Where' Visual Pathways from Spectral Clustering of Layer-Distributed Neural Representations
Dec 11, 2023We present an approach for analyzing grouping information contained within a neural network's activations, permitting extraction of spatial layout and semantic segmentation from the behavior of large pre-trained vision models. Unlike prior work, our method conducts a wholistic analysis of a network's activation state, leveraging features from all layers and obviating the need to guess which part of the model contains relevant information. Motivated by classic spectral clustering, we formulate this analysis in terms of an optimization objective involving a set of affinity matrices, each formed by comparing features within a different layer. Solving this optimization problem using gradient descent allows our technique to scale from single images to dataset-level analysis, including, in the latter, both intra- and inter-image relationships. Analyzing a pre-trained generative transformer provides insight into the computational strategy learned by such models. Equating affinity with key-query similarity across attention layers yields eigenvectors encoding scene spatial layout, whereas defining affinity by value vector similarity yields eigenvectors encoding object identity. This result suggests that key and query vectors coordinate attentional information flow according to spatial proximity (a `where' pathway), while value vectors refine a semantic category representation (a `what' pathway).
Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning
Sep 08, 2023Exploration in sparse-reward reinforcement learning is difficult due to the requirement of long, coordinated sequences of actions in order to achieve any reward. Moreover, in continuous action spaces there are an infinite number of possible actions, which only increases the difficulty of exploration. One class of methods designed to address these issues forms temporally extended actions, often called skills, from interaction data collected in the same domain, and optimizes a policy on top of this new action space. Typically such methods require a lengthy pretraining phase, especially in continuous action spaces, in order to form the skills before reinforcement learning can begin. Given prior evidence that the full range of the continuous action space is not required in such tasks, we propose a novel approach to skill-generation with two components. First we discretize the action space through clustering, and second we leverage a tokenization technique borrowed from natural language processing to generate temporally extended actions. Such a method outperforms baselines for skill-generation in several challenging sparse-reward domains, and requires orders-of-magnitude less computation in skill-generation and online rollouts.
Statler: State-Maintaining Language Models for Embodied Reasoning
Jul 03, 2023



Large language models (LLMs) provide a promising tool that enable robots to perform complex robot reasoning tasks. However, the limited context window of contemporary LLMs makes reasoning over long time horizons difficult. Embodied tasks such as those that one might expect a household robot to perform typically require that the planner consider information acquired a long time ago (e.g., properties of the many objects that the robot previously encountered in the environment). Attempts to capture the world state using an LLM's implicit internal representation is complicated by the paucity of task- and environment-relevant information available in a robot's action history, while methods that rely on the ability to convey information via the prompt to the LLM are subject to its limited context window. In this paper, we propose Statler, a framework that endows LLMs with an explicit representation of the world state as a form of ``memory'' that is maintained over time. Integral to Statler is its use of two instances of general LLMs -- a world-model reader and a world-model writer -- that interface with and maintain the world state. By providing access to this world state ``memory'', Statler improves the ability of existing LLMs to reason over longer time horizons without the constraint of context length. We evaluate the effectiveness of our approach on three simulated table-top manipulation domains and a real robot domain, and show that it improves the state-of-the-art in LLM-based robot reasoning. Project website: https://statler-lm.github.io/
Jointly Learning to Construct and Control Agents using Deep Reinforcement Learning
Sep 14, 2018
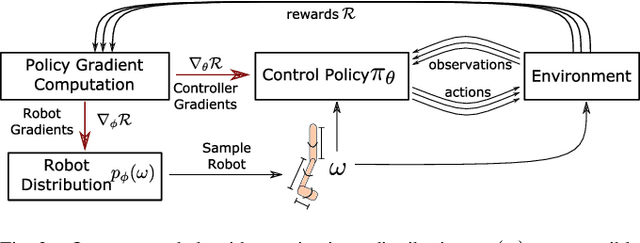
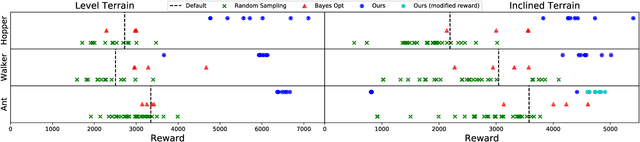
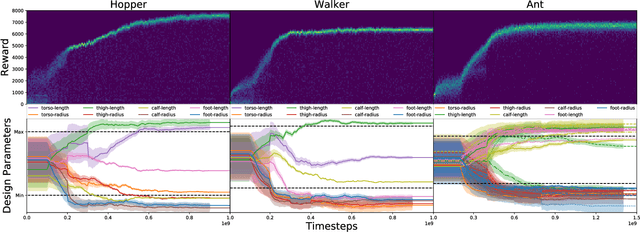
The physical design of a robot and the policy that controls its motion are inherently coupled, and should be determined according to the task and environment. In an increasing number of applications, data-driven and learning-based approaches, such as deep reinforcement learning, have proven effective at designing control policies. For most tasks, the only way to evaluate a physical design with respect to such control policies is empirical--i.e., by picking a design and training a control policy for it. Since training these policies is time-consuming, it is computationally infeasible to train separate policies for all possible designs as a means to identify the best one. In this work, we address this limitation by introducing a method that performs simultaneous joint optimization of the physical design and control network. Our approach maintains a distribution over designs and uses reinforcement learning to optimize a control policy to maximize expected reward over the design distribution. We give the controller access to design parameters to allow it to tailor its policy to each design in the distribution. Throughout training, we shift the distribution towards higher-performing designs, eventually converging to a design and control policy that are jointly optimal. We evaluate our approach in the context of legged locomotion, and demonstrate that it discovers novel designs and walking gaits, outperforming baselines in both performance and efficiency.
Jointly Optimizing Placement and Inference for Beacon-based Localization
Sep 20, 2017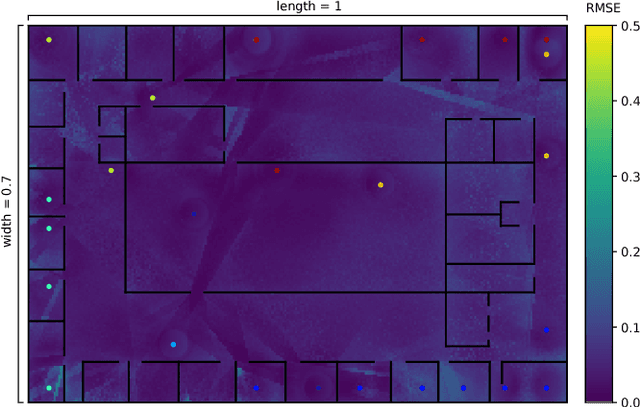
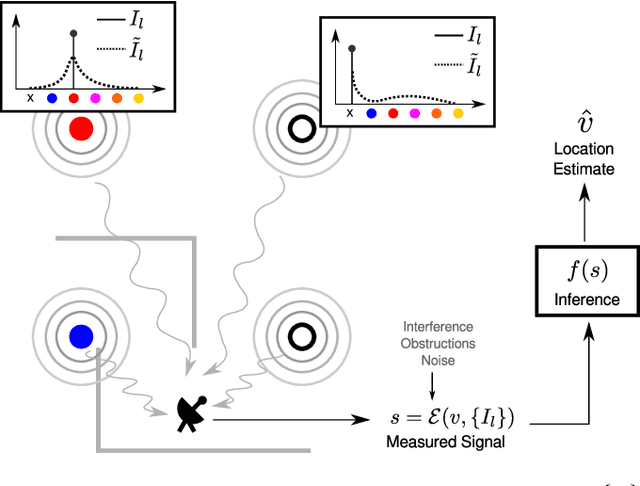
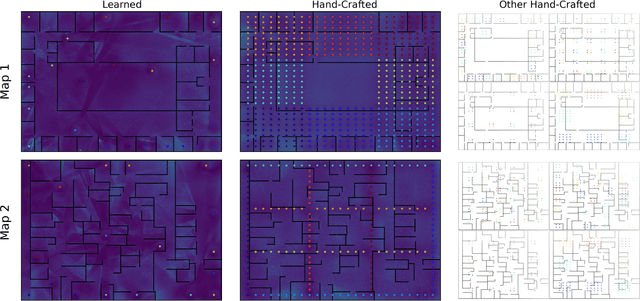
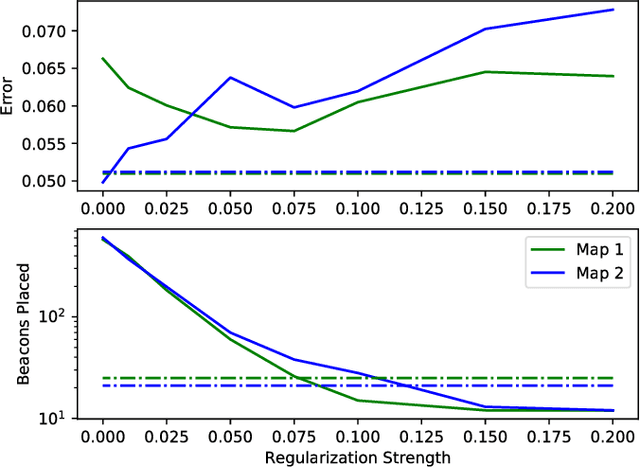
The ability of robots to estimate their location is crucial for a wide variety of autonomous operations. In settings where GPS is unavailable, measurements of transmissions from fixed beacons provide an effective means of estimating a robot's location as it navigates. The accuracy of such a beacon-based localization system depends both on how beacons are distributed in the environment, and how the robot's location is inferred based on noisy and potentially ambiguous measurements. We propose an approach for making these design decisions automatically and without expert supervision, by explicitly searching for the placement and inference strategies that, together, are optimal for a given environment. Since this search is computationally expensive, our approach encodes beacon placement as a differential neural layer that interfaces with a neural network for inference. This formulation allows us to employ standard techniques for training neural networks to carry out the joint optimization. We evaluate this approach on a variety of environments and settings, and find that it is able to discover designs that enable high localization accuracy.