 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Approaches to Co-Optimization in Robotics
Sep 01, 2022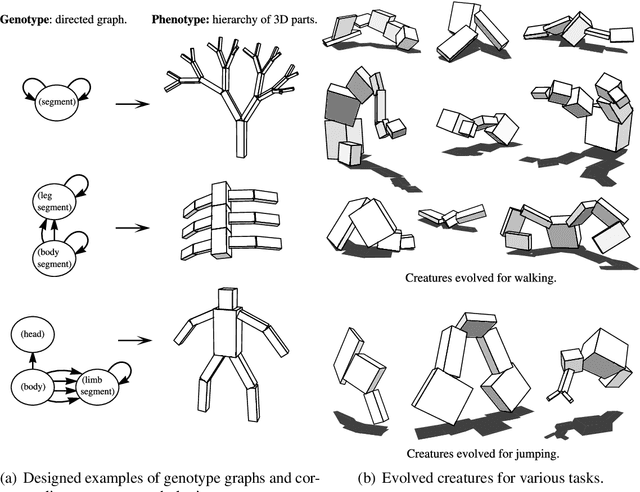
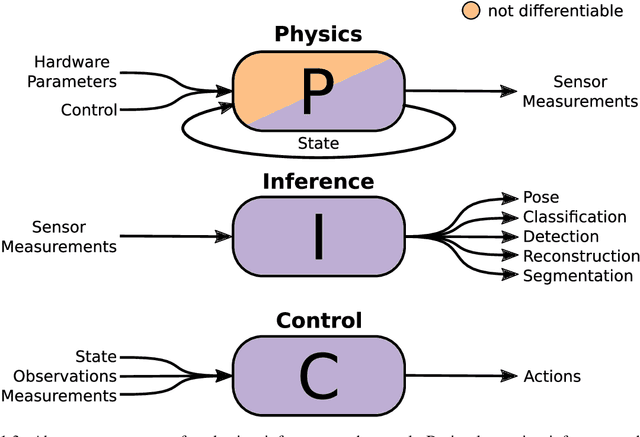
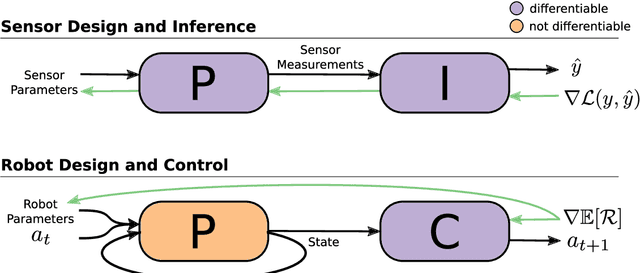
Robots and intelligent systems that sense or interact with the world are increasingly being used to automate a wide array of tasks. The ability of these systems to complete these tasks depends on a large range of technologies such as the mechanical and electrical parts that make up the physical body of the robot and its sensors, perception algorithms to perceive the environment, and planning and control algorithms to produce meaningful actions. Therefore, it is often necessary to consider the interactions between these components when designing an embodied system. This thesis explores work on the task-driven co-optimization of robotics systems in an end-to-end manner, simultaneously optimizing the physical components of the system with inference or control algorithms directly for task performance. We start by considering the problem of optimizing a beacon-based localization system directly for localization accuracy. Designing such a system involves placing beacons throughout the environment and inferring location from sensor readings. In our work, we develop a deep learning approach to optimize both beacon placement and location inference directly for localization accuracy. We then turn our attention to the related problem of task-driven optimization of robots and their controllers. In our work, we start by proposing a data-efficient algorithm based on multi-task reinforcement learning. Our approach efficiently optimizes both physical design and control parameters directly for task performance by leveraging a design-conditioned controller capable of generalizing over the space of physical designs. We then follow this up with an extension to allow for the optimization over discrete morphological parameters such as the number and configuration of limbs. Finally, we conclude by exploring the fabrication and deployment of optimized soft robots.
N-LIMB: Neural Limb Optimization for Efficient Morphological Design
Jul 24, 2022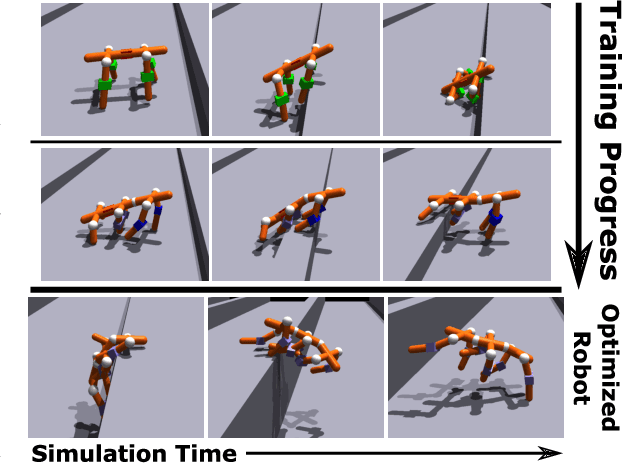
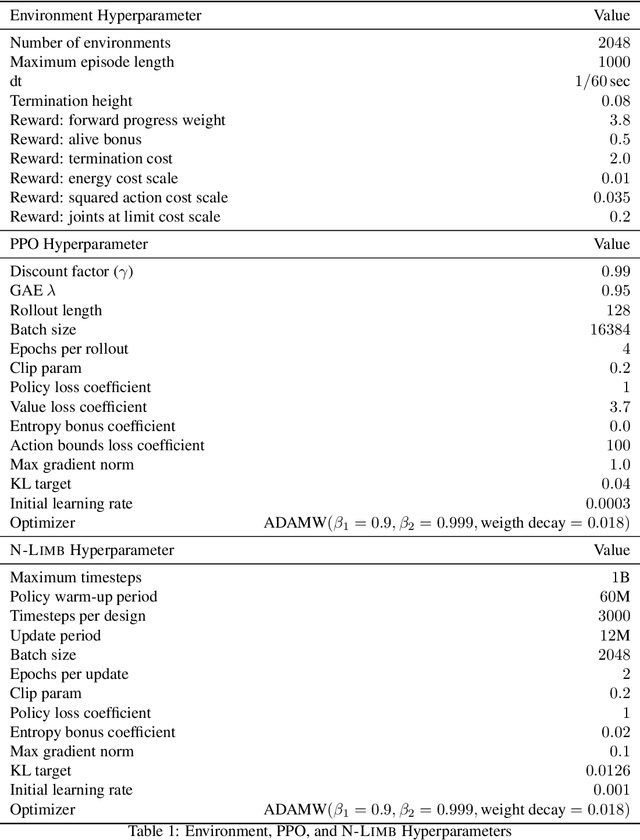
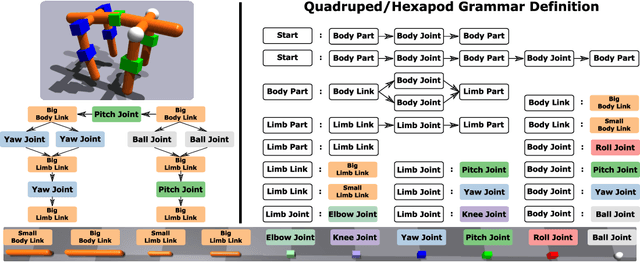
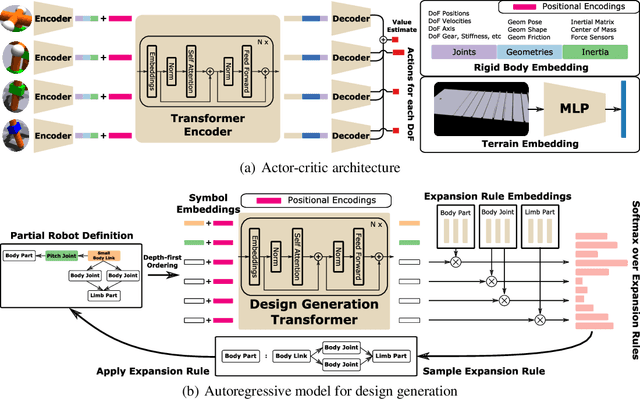
A robot's ability to complete a task is heavily dependent on its physical design. However, identifying an optimal physical design and its corresponding control policy is inherently challenging. The freedom to choose the number of links, their type, and how they are connected results in a combinatorial design space, and the evaluation of any design in that space requires deriving its optimal controller. In this work, we present N-LIMB, an efficient approach to optimizing the design and control of a robot over large sets of morphologies. Central to our framework is a universal, design-conditioned control policy capable of controlling a diverse sets of designs. This policy greatly improves the sample efficiency of our approach by allowing the transfer of experience across designs and reducing the cost to evaluate new designs. We train this policy to maximize expected return over a distribution of designs, which is simultaneously updated towards higher performing designs under the universal policy. In this way, our approach converges towards a design distribution peaked around high-performing designs and a controller that is effectively fine-tuned for those designs. We demonstrate the potential of our approach on a series of locomotion tasks across varying terrains and show the discovery novel and high-performing design-control pairs.
Soft Robots Learn to Crawl: Jointly Optimizing Design and Control with Sim-to-Real Transfer
Feb 09, 2022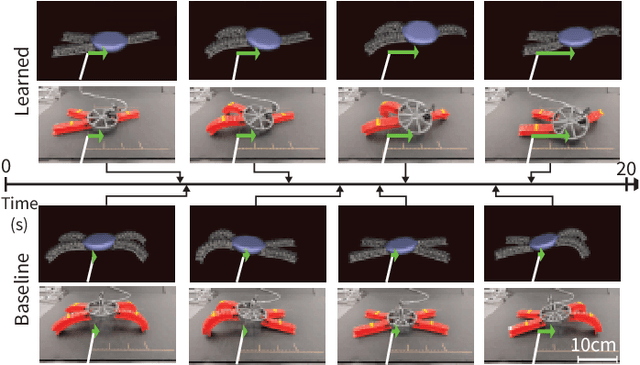
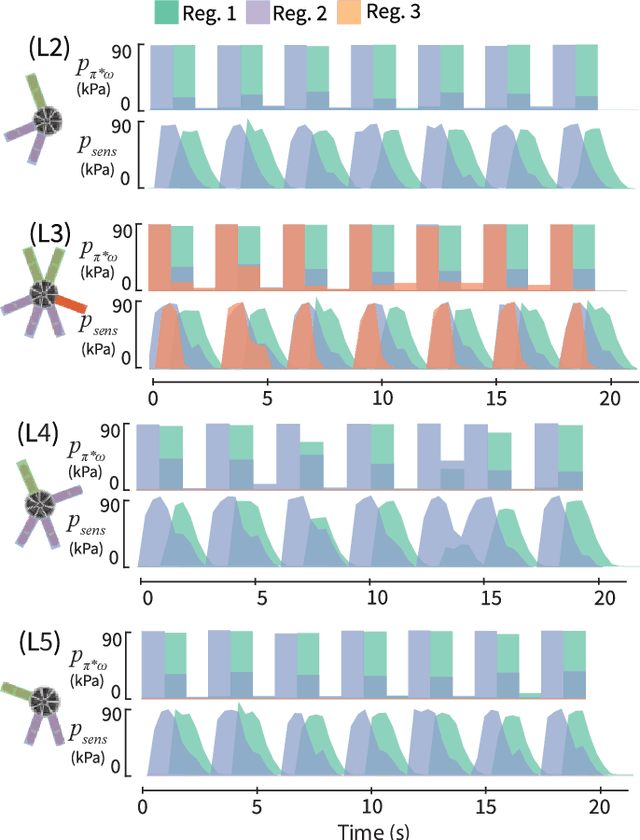
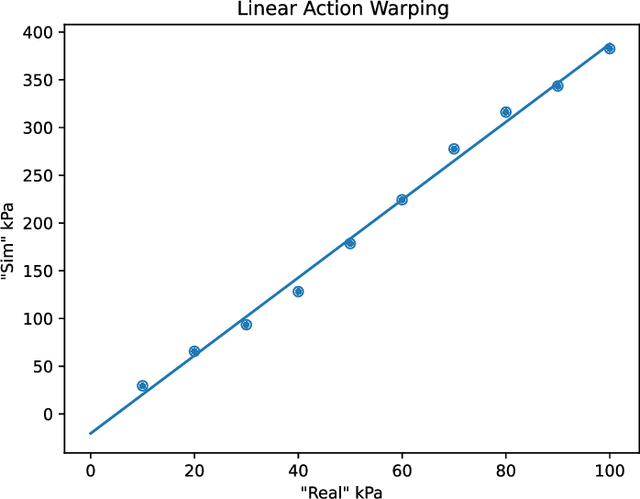
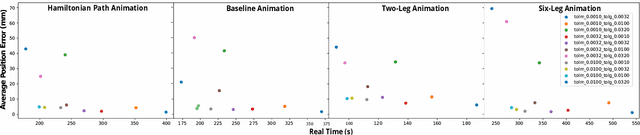
This work provides a complete framework for the simulation, co-optimization, and sim-to-real transfer of the design and control of soft legged robots. The compliance of soft robots provides a form of "mechanical intelligence" -- the ability to passively exhibit behaviors that would otherwise be difficult to program. Exploiting this capacity requires careful consideration of the coupling between mechanical design and control. Co-optimization provides a promising means to generate sophisticated soft robots by reasoning over this coupling. However, the complex nature of soft robot dynamics makes it difficult to provide a simulation environment that is both sufficiently accurate to allow for sim-to-real transfer, while also being fast enough for contemporary co-optimization algorithms. In this work, we show that finite element simulation combined with recent model order reduction techniques provide both the efficiency and the accuracy required to successfully learn effective soft robot design-control pairs that transfer to reality. We propose a reinforcement learning-based framework for co-optimization and demonstrate successful optimization, construction, and zero-shot sim-to-real transfer of several soft crawling robots. Our learned robot outperforms an expert-designed crawling robot, showing that our approach can generate novel, high-performing designs even in well-understood domains.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
Benchmarking Structured Policies and Policy Optimization for Real-World Dexterous Object Manipulation
May 05, 2021

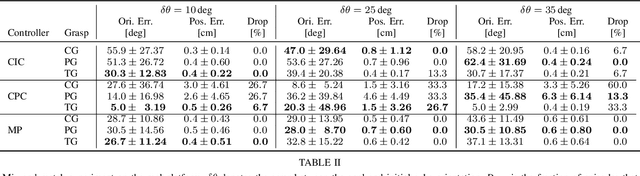
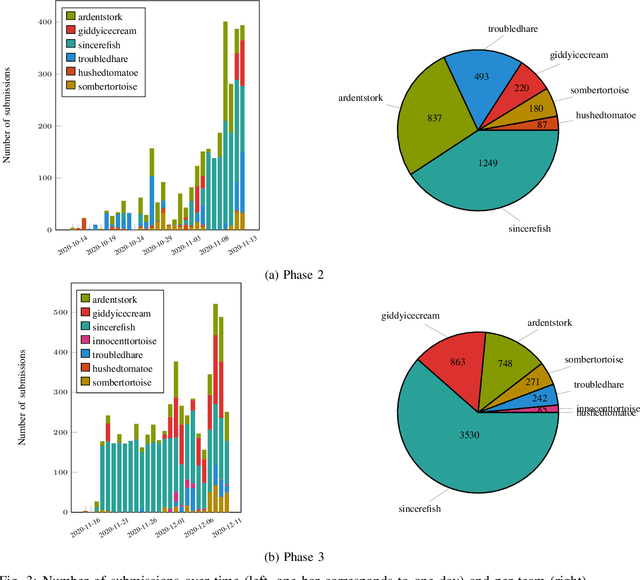
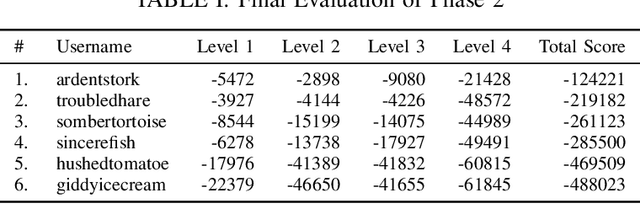
Dexterous manipulation is a challenging and important problem in robotics. While data-driven methods are a promising approach, current benchmarks require simulation or extensive engineering support due to the sample inefficiency of popular methods. We present benchmarks for the TriFinger system, an open-source robotic platform for dexterous manipulation and the focus of the 2020 Real Robot Challenge. The benchmarked methods, which were successful in the challenge, can be generally described as structured policies, as they combine elements of classical robotics and modern policy optimization. This inclusion of inductive biases facilitates sample efficiency, interpretability, reliability and high performance. The key aspects of this benchmarking is validation of the baselines across both simulation and the real system, thorough ablation study over the core features of each solution, and a retrospective analysis of the challenge as a manipulation benchmark. The code and demo videos for this work can be found on our website (https://sites.google.com/view/benchmark-rrc).
Grasp and Motion Planning for Dexterous Manipulation for the Real Robot Challenge
Jan 08, 2021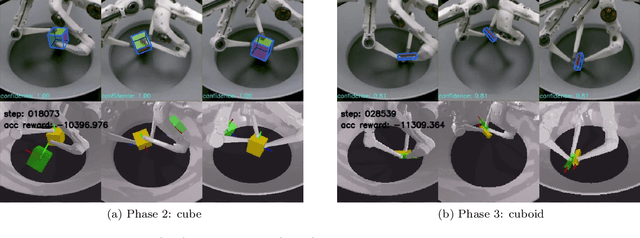

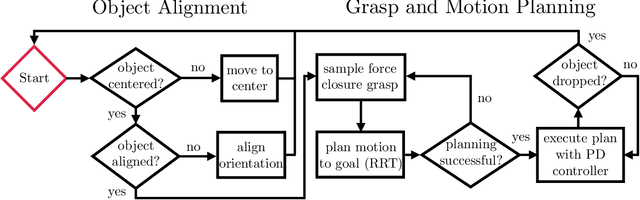
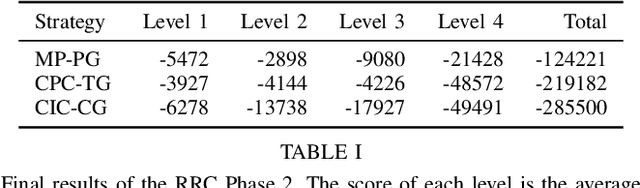
This report describes our winning submission to the Real Robot Challenge (https://real-robot-challenge.com/). The Real Robot Challenge is a three-phase dexterous manipulation competition that involves manipulating various rectangular objects with the TriFinger Platform. Our approach combines motion planning with several motion primitives to manipulate the object. For Phases 1 and 2, we additionally learn a residual policy in simulation that applies corrective actions on top of our controller. Our approach won first place in Phase 2 and Phase 3 of the competition. We were anonymously known as `ardentstork' on the competition leaderboard (https://real-robot-challenge.com/leader-board). Videos and our code can be found at https://github.com/ripl-ttic/real-robot-challenge.
Residual Policy Learning for Shared Autonomy
Apr 10, 2020
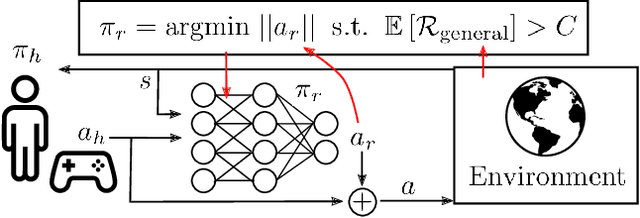

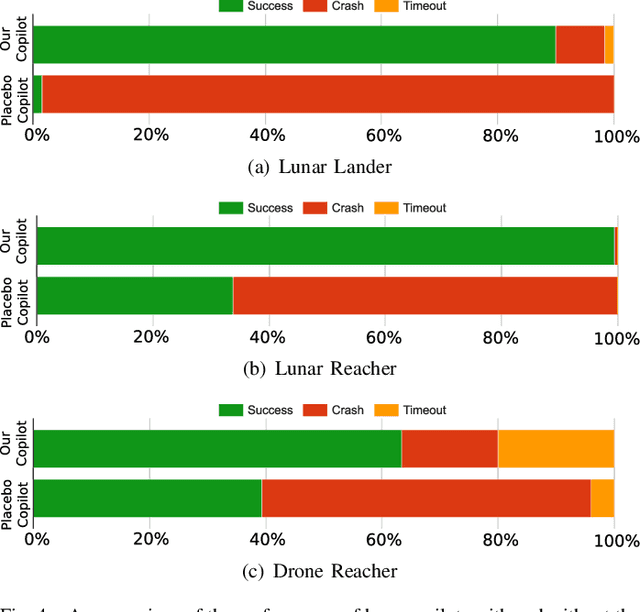
Shared autonomy provides an effective framework for human-robot collaboration that takes advantage of the complementary strengths of humans and robots to achieve common goals. Many existing approaches to shared autonomy make restrictive assumptions that the goal space, environment dynamics, or human policy are known a priori, or are limited to discrete action spaces, preventing those methods from scaling to complicated real world environments. We propose a model-free, residual policy learning algorithm for shared autonomy that alleviates the need for these assumptions. Our agents are trained to minimally adjust the human's actions such that a set of goal-agnostic constraints are satisfied. We test our method in two continuous control environments: LunarLander, a 2D flight control domain, and a 6-DOF quadrotor reaching task. In experiments with human and surrogate pilots, our method significantly improves task performance even though the agent has no explicit or implicit knowledge of the human's goal. These results highlight the ability of model-free deep reinforcement learning to realize assistive agents suited to complicated continuous control settings with minimal knowledge of user intent.
Jointly Learning to Construct and Control Agents using Deep Reinforcement Learning
Sep 14, 2018
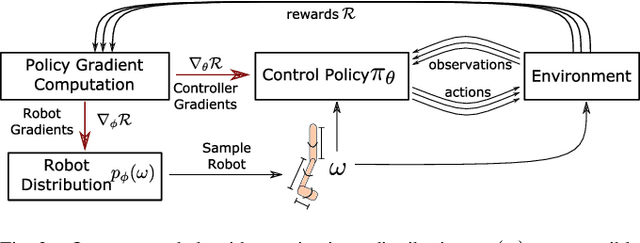
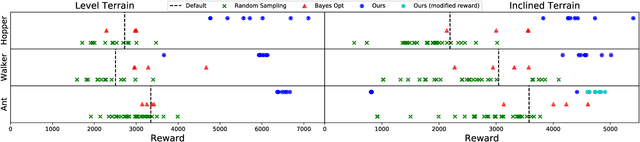
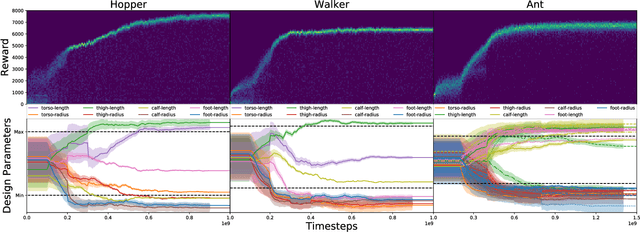
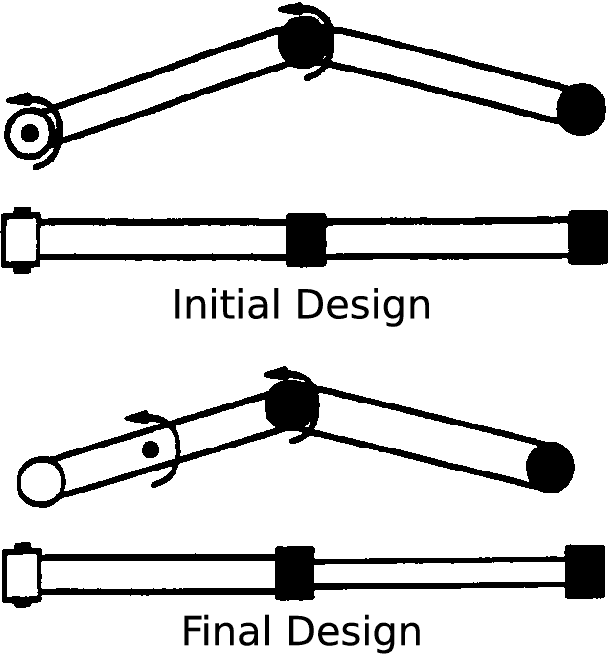
The physical design of a robot and the policy that controls its motion are inherently coupled, and should be determined according to the task and environment. In an increasing number of applications, data-driven and learning-based approaches, such as deep reinforcement learning, have proven effective at designing control policies. For most tasks, the only way to evaluate a physical design with respect to such control policies is empirical--i.e., by picking a design and training a control policy for it. Since training these policies is time-consuming, it is computationally infeasible to train separate policies for all possible designs as a means to identify the best one. In this work, we address this limitation by introducing a method that performs simultaneous joint optimization of the physical design and control network. Our approach maintains a distribution over designs and uses reinforcement learning to optimize a control policy to maximize expected reward over the design distribution. We give the controller access to design parameters to allow it to tailor its policy to each design in the distribution. Throughout training, we shift the distribution towards higher-performing designs, eventually converging to a design and control policy that are jointly optimal. We evaluate our approach in the context of legged locomotion, and demonstrate that it discovers novel designs and walking gaits, outperforming baselines in both performance and efficiency.
Jointly Optimizing Placement and Inference for Beacon-based Localization
Sep 20, 2017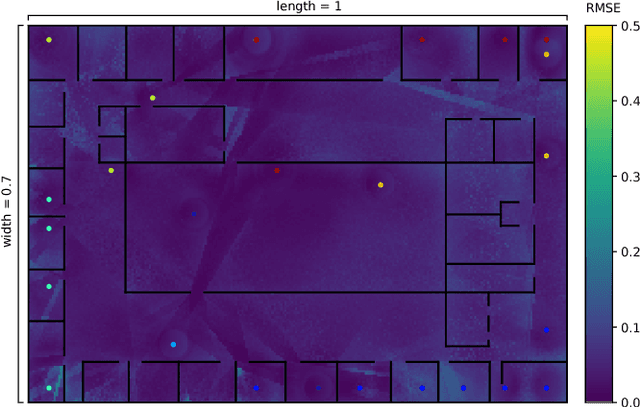
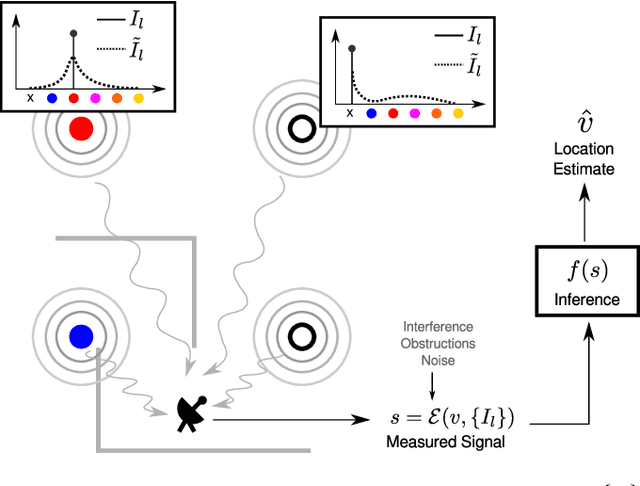
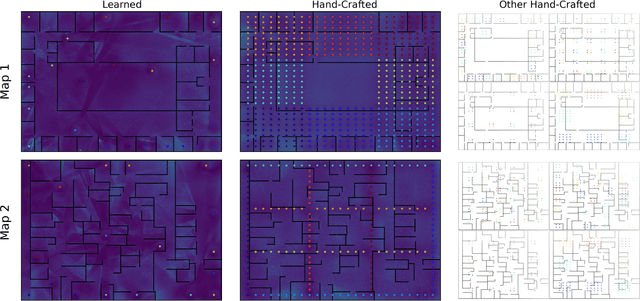
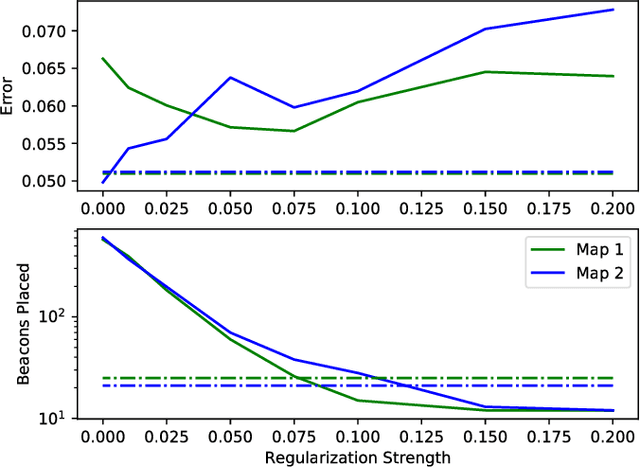
The ability of robots to estimate their location is crucial for a wide variety of autonomous operations. In settings where GPS is unavailable, measurements of transmissions from fixed beacons provide an effective means of estimating a robot's location as it navigates. The accuracy of such a beacon-based localization system depends both on how beacons are distributed in the environment, and how the robot's location is inferred based on noisy and potentially ambiguous measurements. We propose an approach for making these design decisions automatically and without expert supervision, by explicitly searching for the placement and inference strategies that, together, are optimal for a given environment. Since this search is computationally expensive, our approach encodes beacon placement as a differential neural layer that interfaces with a neural network for inference. This formulation allows us to employ standard techniques for training neural networks to carry out the joint optimization. We evaluate this approach on a variety of environments and settings, and find that it is able to discover designs that enable high localization accuracy.