 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherent Off-Policy Improvement of Large Behavior Models with Learned Rewards
Jun 01, 2026Distilling expert demonstration data into large generative models using behavioral cloning is a scalable approach to learning capable policies for robotic control, particularly for dexterous manipulation. Reinforcement learning (RL) can be used as a means to finetune these policies further using additional experience. An open question is whether RL is more sample-efficient than collecting more human demonstrations. Prior work has finetuned large pretrained policies in a scalable fashion by applying RL to a smaller residual policy that corrects the pretrained model. However, for the typical sparse reward tasks, RL algorithms can struggle to optimize the behavior in a sample-efficient manner. We explore inverse reinforcement learning, where a dense reward function is learned from expert demonstrations, potentially reducing the challenge of RL finetuning. We specifically consider coherent imitation learning, an IRL method that facilitates improvement of the BC policy through using a specific reward formulation with theoretical guarantees. We show that our IRL method maintains or improves the performance of pi-0.5 on all six sparse manipulation tasks and achieves a $\geq 90\%$ success rate on five out of six complex manipulation tasks, outperforming RL-based baselines using sparse rewards. By ensuring our initial pretrained finetuning policy is optimal for our initial reward and critic, our method circumvents the initial drop commonly seen in RL finetuning and enables faster improvement.
XQCfD: Accelerating Fast Actor-Critic Algorithms with Prior Data and Prior Policies
May 11, 2026For reinforcement learning in the real world online exploration is expensive A common practice in robotic reinforcement learning is to incorporate additional data to improve sample efficiency Expert demonstration data is often crucial for solving hard exploration tasks with sparse rewards While prior data is used to augment experience and pretrain models we show that the design of existing algorithms fails to achieve the sample efficiency that is possible in this setting due to a failure to use pretrained policies effectively We propose XQCfD which extends the sample-efficient XQC actor-critic to learn from demonstrations using augmented replay buffers pretrained policies and stationary policy architectures designed to avoid rapidly unlearning the strong initial policy like prior works We show our stationary network architecture enables policy improvement out-of-distribution better than standard network architectures due to its higher entropy predictions XQCfD achieves state of the art performance across a range of complex manipulation tasks with sparse rewards from the popular Adroit Robomimic and MimicGen benchmarks -- notably with a low update-to-data ratio and no ensemble networks
Disentangling Dynamical Systems: Causal Representation Learning Meets Local Sparse Attention
Mar 15, 2026Parametric system identification methods estimate the parameters of explicitly defined physical systems from data. Yet, they remain constrained by the need to provide an explicit function space, typically through a predefined library of candidate functions chosen via available domain knowledge. In contrast, deep learning can demonstrably model systems of broad complexity with high fidelity, but black-box function approximation typically fails to yield explicit descriptive or disentangled representations revealing the structure of a system. We develop a novel identifiability theorem, leveraging causal representation learning, to uncover disentangled representations of system parameters without structural assumptions. We derive a graphical criterion specifying when system parameters can be uniquely disentangled from raw trajectory data, up to permutation and diffeomorphism. Crucially, our analysis demonstrates that global causal structures provide a lower bound on the disentanglement guarantees achievable when considering local state-dependent causal structures. We instantiate system parameter identification as a variational inference problem, leveraging a sparsity-regularised transformer to uncover state-dependent causal structures. We empirically validate our approach across four synthetic domains, demonstrating its ability to recover highly disentangled representations that baselines fail to recover. Corroborating our theoretical analysis, our results confirm that enforcing local causal structure is often necessary for full identifiability.
Posterior Sampling Reinforcement Learning with Gaussian Processes for Continuous Control: Sublinear Regret Bounds for Unbounded State Spaces
Mar 09, 2026We analyze the Bayesian regret of the Gaussian process posterior sampling reinforcement learning (GP-PSRL) algorithm. Posterior sampling is an effective heuristic for decision-making under uncertainty that has been used to develop successful algorithms for a variety of continuous control problems. However, theoretical work on GP-PSRL is limited. All known regret bounds either fail to achieve a tight dependence on a kernel-dependent quantity called the maximum information gain or fail to properly account for the fact that the set of possible system states is unbounded. Through a recursive application of the Borell-Tsirelson-Ibragimov-Sudakov inequality, we show that, with high probability, the states actually visited by the algorithm are contained within a ball of near-constant radius. To obtain tight dependence on the maximum information gain, we use the chaining method to control the regret suffered by GP-PSRL. Our main result is a Bayesian regret bound of the order $\widetilde{\mathcal{O}}(H^{3/2}\sqrt{γ_{T/H} T})$, where $H$ is the horizon, $T$ is the number of time steps and $γ_{T/H}$ is the maximum information gain. With this result, we resolve the limitations with prior theoretical work on PSRL, and provide the theoretical foundation and tools for analyzing PSRL in complex settings.
Building Gradient by Gradient: Decentralised Energy Functions for Bimanual Robot Assembly
Oct 06, 2025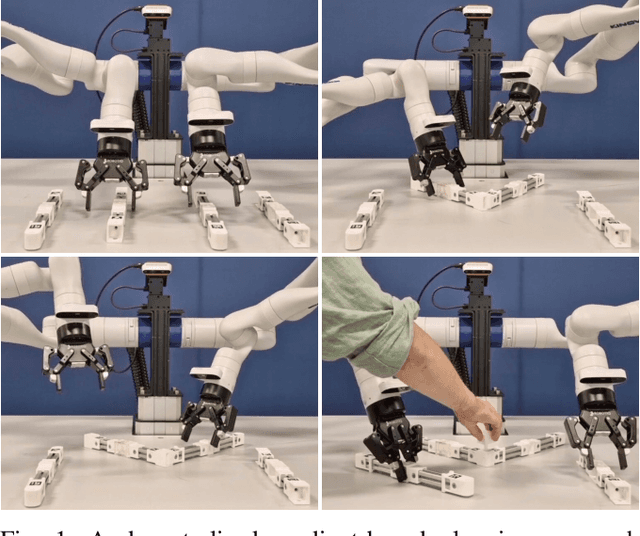



There are many challenges in bimanual assembly, including high-level sequencing, multi-robot coordination, and low-level, contact-rich operations such as component mating. Task and motion planning (TAMP) methods, while effective in this domain, may be prohibitively slow to converge when adapting to disturbances that require new task sequencing and optimisation. These events are common during tight-tolerance assembly, where difficult-to-model dynamics such as friction or deformation require rapid replanning and reattempts. Moreover, defining explicit task sequences for assembly can be cumbersome, limiting flexibility when task replanning is required. To simplify this planning, we introduce a decentralised gradient-based framework that uses a piecewise continuous energy function through the automatic composition of adaptive potential functions. This approach generates sub-goals using only myopic optimisation, rather than long-horizon planning. It demonstrates effectiveness at solving long-horizon tasks due to the structure and adaptivity of the energy function. We show that our approach scales to physical bimanual assembly tasks for constructing tight-tolerance assemblies. In these experiments, we discover that our gradient-based rapid replanning framework generates automatic retries, coordinated motions and autonomous handovers in an emergent fashion.
Towards Safe Robot Foundation Models Using Inductive Biases
May 15, 2025Safety is a critical requirement for the real-world deployment of robotic systems. Unfortunately, while current robot foundation models show promising generalization capabilities across a wide variety of tasks, they fail to address safety, an important aspect for ensuring long-term operation. Current robot foundation models assume that safe behavior should emerge by learning from a sufficiently large dataset of demonstrations. However, this approach has two clear major drawbacks. Firstly, there are no formal safety guarantees for a behavior cloning policy trained using supervised learning. Secondly, without explicit knowledge of any safety constraints, the policy may require an unreasonable number of additional demonstrations to even approximate the desired constrained behavior. To solve these key issues, we show how we can instead combine robot foundation models with geometric inductive biases using ATACOM, a safety layer placed after the foundation policy that ensures safe state transitions by enforcing action constraints. With this approach, we can ensure formal safety guarantees for generalist policies without providing extensive demonstrations of safe behavior, and without requiring any specific fine-tuning for safety. Our experiments show that our approach can be beneficial both for classical manipulation tasks, where we avoid unwanted collisions with irrelevant objects, and for dynamic tasks, such as the robot air hockey environment, where we can generate fast trajectories respecting complex tasks and joint space constraints.
Towards Safe Robot Foundation Models
Mar 10, 2025Robot foundation models hold the potential for deployment across diverse environments, from industrial applications to household tasks. While current research focuses primarily on the policies' generalization capabilities across a variety of tasks, it fails to address safety, a critical requirement for deployment on real-world systems. In this paper, we introduce a safety layer designed to constrain the action space of any generalist policy appropriately. Our approach uses ATACOM, a safe reinforcement learning algorithm that creates a safe action space and, therefore, ensures safe state transitions. By extending ATACOM to generalist policies, our method facilitates their deployment in safety-critical scenarios without requiring any specific safety fine-tuning. We demonstrate the effectiveness of this safety layer in an air hockey environment, where it prevents a puck-hitting agent from colliding with its surroundings, a failure observed in generalist policies.
Global Tensor Motion Planning
Nov 28, 2024Batch planning is increasingly crucial for the scalability of robotics tasks and dataset generation diversity. This paper presents Global Tensor Motion Planning (GTMP) -- a sampling-based motion planning algorithm comprising only tensor operations. We introduce a novel discretization structure represented as a random multipartite graph, enabling efficient vectorized sampling, collision checking, and search. We provide an early theoretical investigation showing that GTMP exhibits probabilistic completeness while supporting modern GPU/TPU. Additionally, by incorporating smooth structures into the multipartite graph, GTMP directly plans smooth splines without requiring gradient-based optimization. Experiments on lidar-scanned occupancy maps and the MotionBenchMarker dataset demonstrate GTMP's computation efficiency in batch planning compared to baselines, underscoring GTMP's potential as a robust, scalable planner for diverse applications and large-scale robot learning tasks.
Machine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024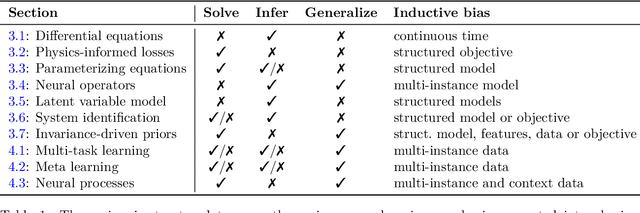
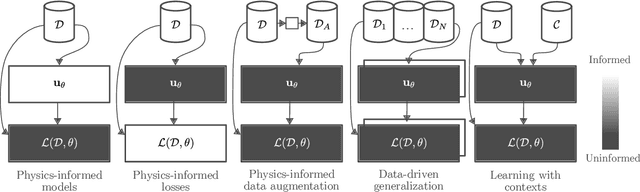
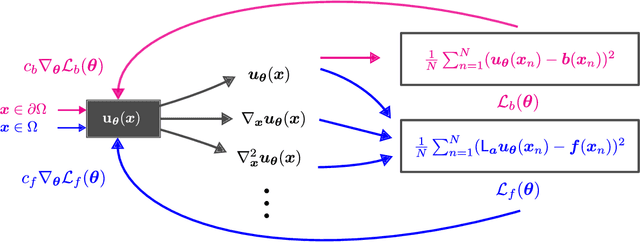
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
Function-Space Regularization for Deep Bayesian Classification
Jul 12, 2023



Bayesian deep learning approaches assume model parameters to be latent random variables and infer posterior distributions to quantify uncertainty, increase safety and trust, and prevent overconfident and unpredictable behavior. However, weight-space priors are model-specific, can be difficult to interpret and are hard to specify. Instead, we apply a Dirichlet prior in predictive space and perform approximate function-space variational inference. To this end, we interpret conventional categorical predictions from stochastic neural network classifiers as samples from an implicit Dirichlet distribution. By adapting the inference, the same function-space prior can be combined with different models without affecting model architecture or size. We illustrate the flexibility and efficacy of such a prior with toy experiments and demonstrate scalability, improved uncertainty quantification and adversarial robustness with large-scale image classification experiments.