 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Tensor Motion Planning
Nov 28, 2024Batch planning is increasingly crucial for the scalability of robotics tasks and dataset generation diversity. This paper presents Global Tensor Motion Planning (GTMP) -- a sampling-based motion planning algorithm comprising only tensor operations. We introduce a novel discretization structure represented as a random multipartite graph, enabling efficient vectorized sampling, collision checking, and search. We provide an early theoretical investigation showing that GTMP exhibits probabilistic completeness while supporting modern GPU/TPU. Additionally, by incorporating smooth structures into the multipartite graph, GTMP directly plans smooth splines without requiring gradient-based optimization. Experiments on lidar-scanned occupancy maps and the MotionBenchMarker dataset demonstrate GTMP's computation efficiency in batch planning compared to baselines, underscoring GTMP's potential as a robust, scalable planner for diverse applications and large-scale robot learning tasks.
Accelerating Motion Planning via Optimal Transport
Sep 27, 2023



Motion planning is still an open problem for many disciplines, e.g., robotics, autonomous driving, due to issues like high planning times that hinder real-time, efficient decision-making. A class of methods striving to provide smooth solutions is gradient-based trajectory optimization. However, those methods might suffer from bad local minima, while for many settings, they may be inapplicable due to the absence of easy access to objectives-gradients. In response to these issues, we introduce Motion Planning via Optimal Transport (MPOT) - a gradient-free method that optimizes a batch of smooth trajectories over highly nonlinear costs, even for high-dimensional tasks, while imposing smoothness through a Gaussian Process dynamics prior via planning-as-inference perspective. To facilitate batch trajectory optimization, we introduce an original zero-order and highly-parallelizable update rule -- the Sinkhorn Step, which uses the regular polytope family for its search directions; each regular polytope, centered on trajectory waypoints, serves as a local neighborhood, effectively acting as a trust region, where the Sinkhorn Step "transports" local waypoints toward low-cost regions. We theoretically show that Sinkhorn Step guides the optimizing parameters toward local minima regions on non-convex objective functions. We then show the efficiency of MPOT in a range of problems from low-dimensional point-mass navigation to high-dimensional whole-body robot motion planning, evincing its superiority compared with popular motion planners and paving the way for new applications of optimal transport in motion planning.
Curriculum Learning with Hindsight Experience Replay for Sequential Object Manipulation Tasks
Aug 21, 2020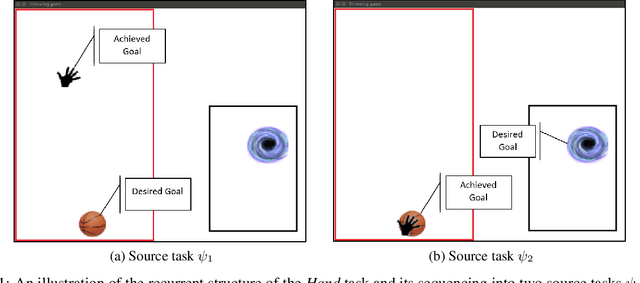
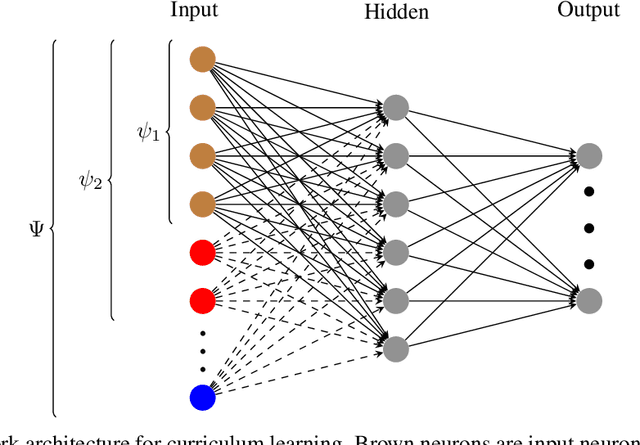
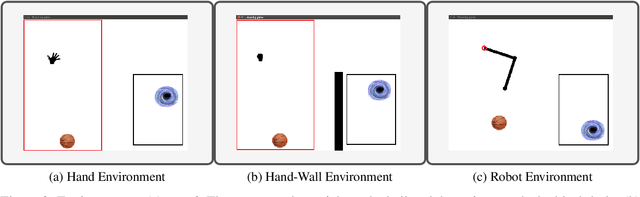
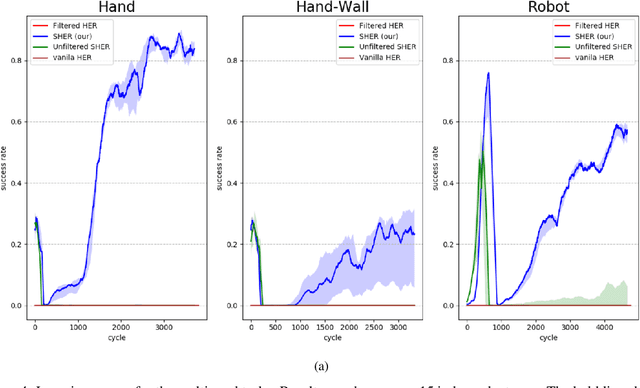
Learning complex tasks from scratch is challenging and often impossible for humans as well as for artificial agents. A curriculum can be used instead, which decomposes a complex task (target task) into a sequence of source tasks (the curriculum). Each source task is a simplified version of the next source task with increasing complexity. Learning then occurs gradually by training on each source task while using knowledge from the curriculum's prior source tasks. In this study, we present a new algorithm that combines curriculum learning with Hindsight Experience Replay (HER), to learn sequential object manipulation tasks for multiple goals and sparse feedback. The algorithm exploits the recurrent structure inherent in many object manipulation tasks and implements the entire learning process in the original simulation without adjusting it to each source task. We have tested our algorithm on three challenging throwing tasks and show vast improvements compared to vanilla-HER.
Deep Reinforcement Learning for Human-Like Driving Policies in Collision Avoidance Tasks of Self-Driving Cars
Jun 19, 2020
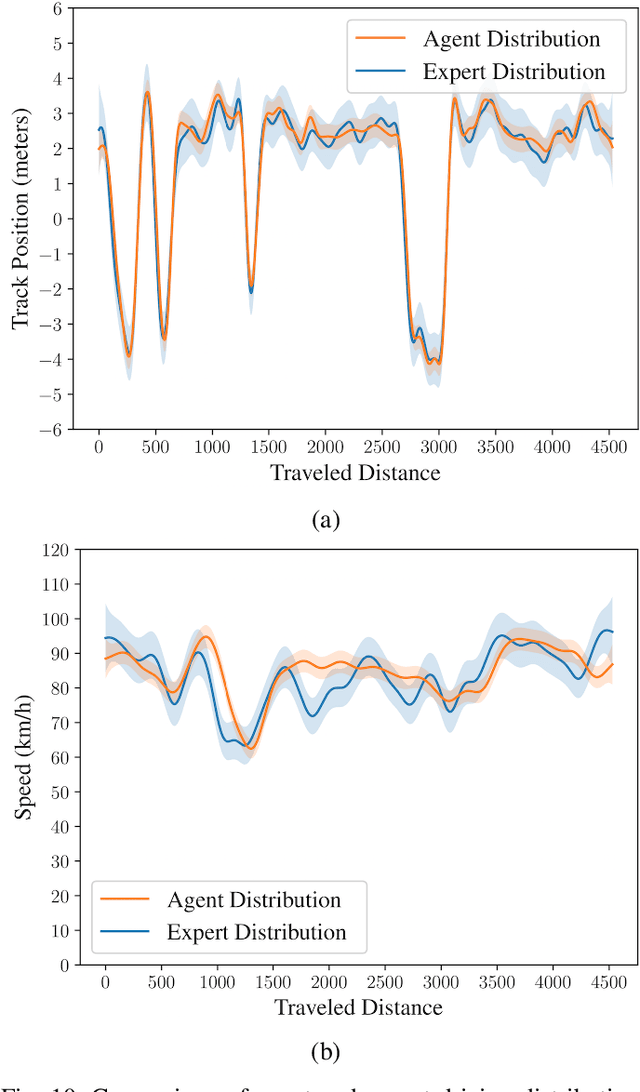
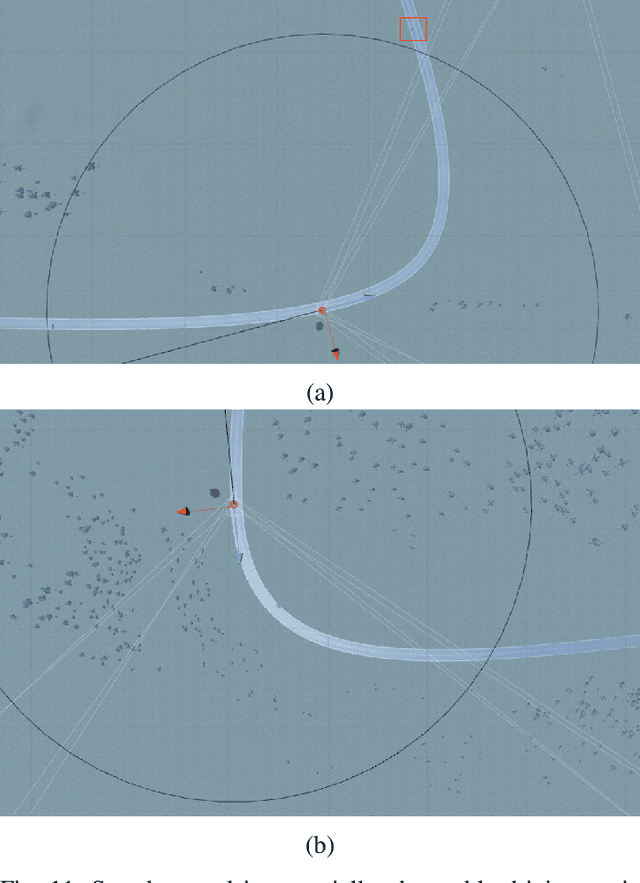
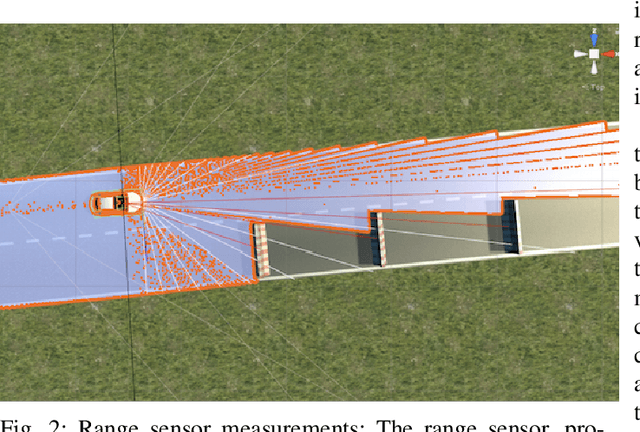
The technological and scientific challenges involved in the development of autonomous vehicles (AVs) are currently of primary interest for many automobile companies and research labs. However, human-controlled vehicles are likely to remain on the roads for several decades to come and may share with AVs the traffic environments of the future. In such mixed environments, AVs should deploy human-like driving policies and negotiation skills to enable smooth traffic flow. To generate automated human-like driving policies, we introduce a model-free, deep reinforcement learning approach to imitate an experienced human driver's behavior. We study a static obstacle avoidance task on a two-lane highway road in simulation (Unity). Our control algorithm receives a stochastic feedback signal from two sources: a model-driven part, encoding simple driving rules, such as lane-keeping and speed control, and a stochastic, data-driven part, incorporating human expert knowledge from driving data. To assess the similarity between machine and human driving, we model distributions of track position and speed as Gaussian processes. We demonstrate that our approach leads to human-like driving policies.
Metric-Based Imitation Learning Between Two Dissimilar Anthropomorphic Robotic Arms
Feb 25, 2020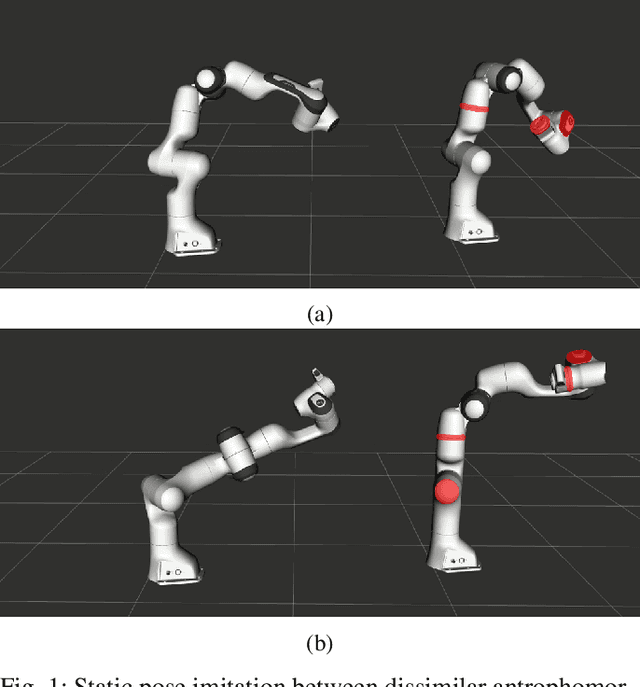
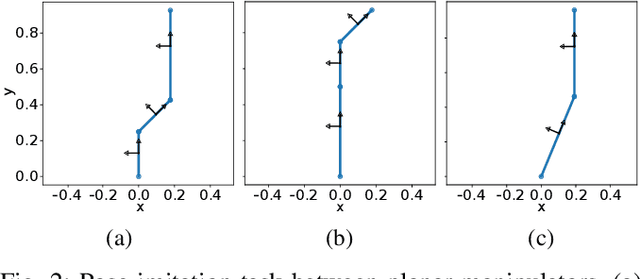
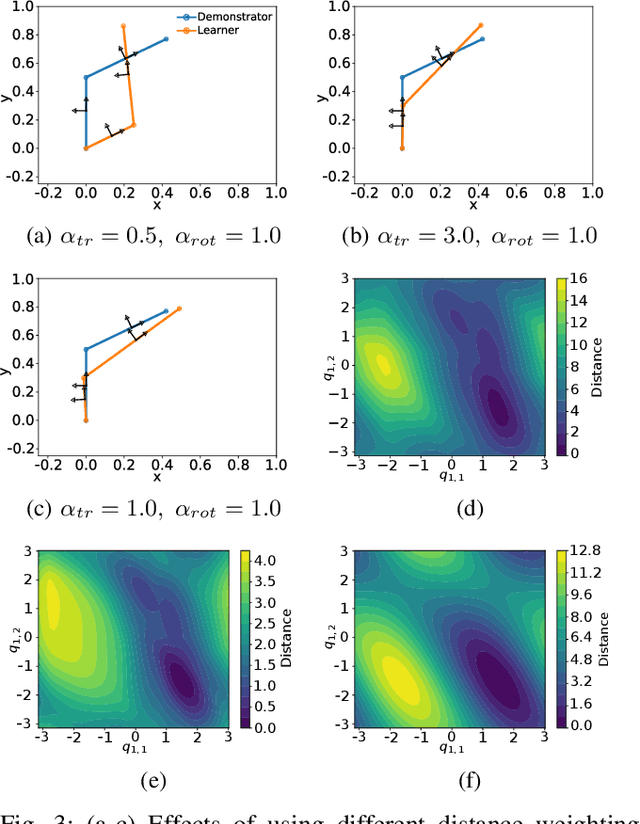
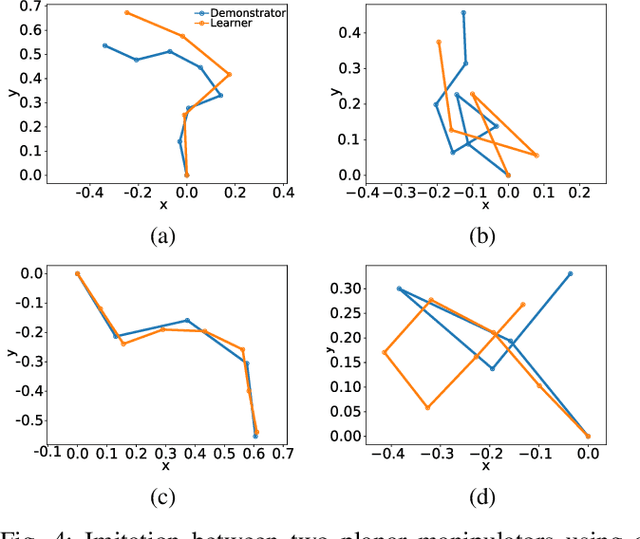
The development of autonomous robotic systems that can learn from human demonstrations to imitate a desired behavior - rather than being manually programmed - has huge technological potential. One major challenge in imitation learning is the correspondence problem: how to establish corresponding states and actions between expert and learner, when the embodiments of the agents are different (morphology, dynamics, degrees of freedom, etc.). Many existing approaches in imitation learning circumvent the correspondence problem, for example, kinesthetic teaching or teleoperation, which are performed on the robot. In this work we explicitly address the correspondence problem by introducing a distance measure between dissimilar embodiments. This measure is then used as a loss function for static pose imitation and as a feedback signal within a model-free deep reinforcement learning framework for dynamic movement imitation between two anthropomorphic robotic arms in simulation. We find that the measure is well suited for describing the similarity between embodiments and for learning imitation policies by distance minimization.
Regression via Kirszbraun Extension with Applications to Imitation Learning
May 28, 2019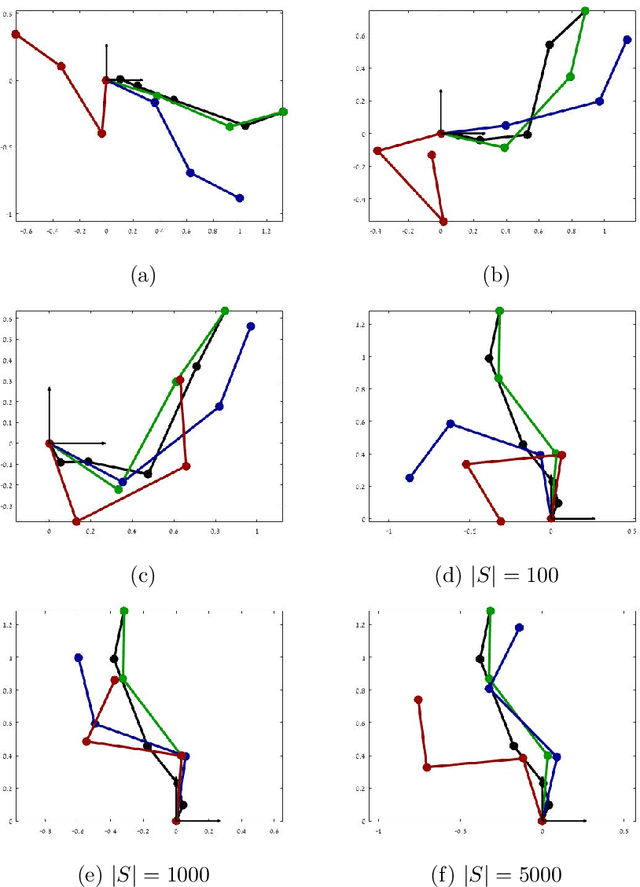
Learning by demonstration is a versatile and rapid mechanism for transferring motor skills from a teacher to a learner. A particular challenge in imitation learning is the so-called correspondence problem, which involves mapping actions between a teacher and a learner having substantially different embodiments (say, human to robot). We present a general, model free and non-parametric imitation learning algorithm based on regression between two Hilbert spaces. We accomplish this via Kirszbraun's extension theorem --- apparently the first application of this technique to supervised learning --- and analyze its statistical and computational aspects. We begin by formulating the correspondence problem in terms of quadratically constrained quadratic program (QCQP) regression. Then we describe a procedure for smoothing the training data, which amounts to regularizing hypothesis complexity via its Lipschitz constant. The Lipschitz constant is tuned via a Structural Risk Minimization (SRM) procedure, based on the covering-number risk bounds we derive. We apply our technique to a static posture imitation task between two robotic manipulators with different embodiments, and report promising results.
Bias-Reduced Hindsight Experience Replay with Virtual Goal Prioritization
May 14, 2019
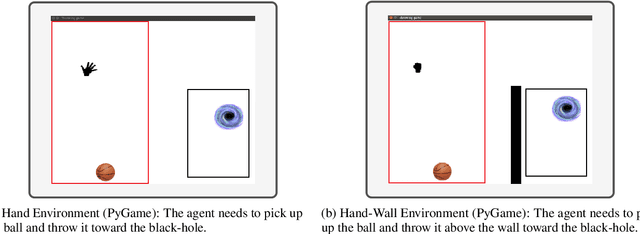

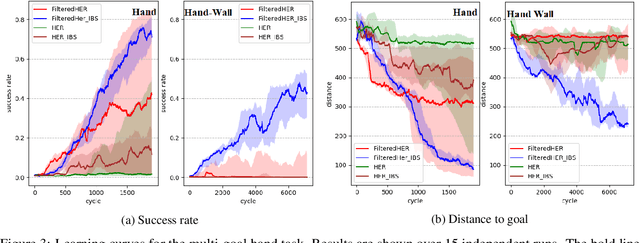
Hindsight Experience Replay (HER) is a multi-goal reinforcement learning algorithm for sparse reward functions. The algorithm treats every failure as a success for an alternative (virtual) goal that has been achieved in the episode. Virtual goals are randomly selected, irrespective of which are most instructive for the agent. In this paper, we present two improvements over the existing HER algorithm. First, we prioritize virtual goals from which the agent will learn more valuable information. We call this property the instructiveness of the virtual goal and define it by a heuristic measure, which expresses how well the agent will be able to generalize from that virtual goal to actual goals. Secondly, we reduce existing bias in HER by the removal of misleading samples. To test our algorithms, we built two challenging environments with sparse reward functions. Our empirical results in both environments show vast improvement in the final success rate and sample efficiency when compared to the original HER algorithm.
Learning Pose Estimation for High-Precision Robotic Assembly Using Simulated Depth Images
Mar 23, 2019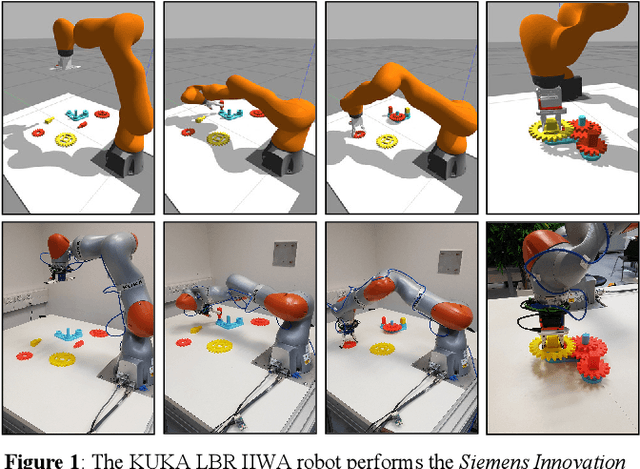
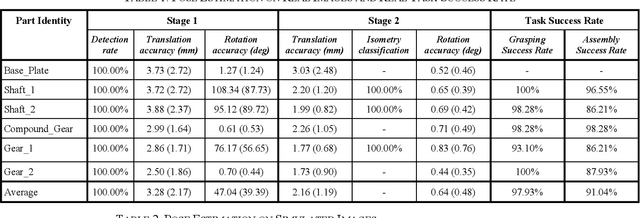

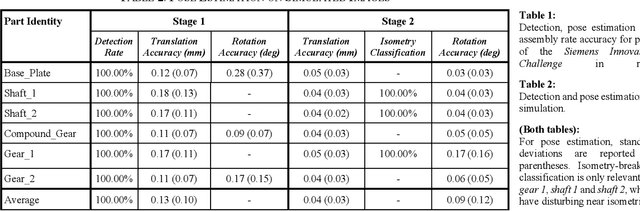
Most of industrial robotic assembly tasks today require fixed initial conditions for successful assembly. These constraints induce high production costs and low adaptability to new tasks. In this work we aim towards flexible and adaptable robotic assembly by using 3D CAD models for all parts to be assembled. We focus on a generic assembly task - the Siemens Innovation Challenge - in which a robot needs to assemble a gear-like mechanism with high precision into an operating system. To obtain the millimeter-accuracy required for this task and industrial settings alike, we use a depth camera mounted near the robot end-effector. We present a high-accuracy two-stage pose estimation procedure based on deep convolutional neural networks, which includes detection, pose estimation, refinement, and handling of near- and full symmetries of parts. The networks are trained on simulated depth images with means to ensure successful transfer to the real robot. We obtain an average pose estimation error of 2.16 millimeters and 0.64 degree leading to 91% success rate for robotic assembly of randomly distributed parts. To the best of our knowledge, this is the first time that the Siemens Innovation Challenge is fully addressed, with all the parts assembled with high success rates.