 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Tensor Planning
May 02, 2025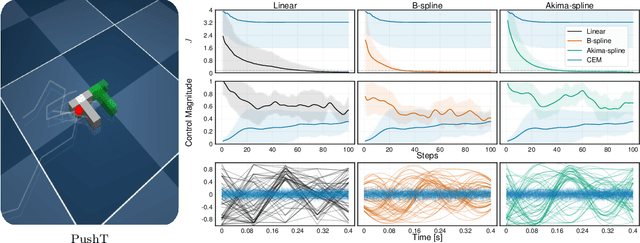
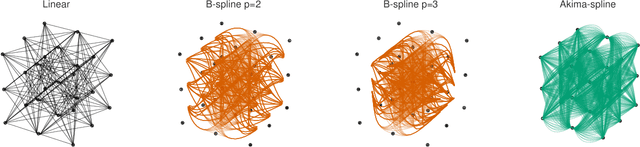

Sampling-based model predictive control (MPC) offers strong performance in nonlinear and contact-rich robotic tasks, yet often suffers from poor exploration due to locally greedy sampling schemes. We propose \emph{Model Tensor Planning} (MTP), a novel sampling-based MPC framework that introduces high-entropy control trajectory generation through structured tensor sampling. By sampling over randomized multipartite graphs and interpolating control trajectories with B-splines and Akima splines, MTP ensures smooth and globally diverse control candidates. We further propose a simple $\beta$-mixing strategy that blends local exploitative and global exploratory samples within the modified Cross-Entropy Method (CEM) update, balancing control refinement and exploration. Theoretically, we show that MTP achieves asymptotic path coverage and maximum entropy in the control trajectory space in the limit of infinite tensor depth and width. Our implementation is fully vectorized using JAX and compatible with MuJoCo XLA, supporting \emph{Just-in-time} (JIT) compilation and batched rollouts for real-time control with online domain randomization. Through experiments on various challenging robotic tasks, ranging from dexterous in-hand manipulation to humanoid locomotion, we demonstrate that MTP outperforms standard MPC and evolutionary strategy baselines in task success and control robustness. Design and sensitivity ablations confirm the effectiveness of MTP tensor sampling structure, spline interpolation choices, and mixing strategy. Altogether, MTP offers a scalable framework for robust exploration in model-based planning and control.
Global Tensor Motion Planning
Nov 28, 2024Batch planning is increasingly crucial for the scalability of robotics tasks and dataset generation diversity. This paper presents Global Tensor Motion Planning (GTMP) -- a sampling-based motion planning algorithm comprising only tensor operations. We introduce a novel discretization structure represented as a random multipartite graph, enabling efficient vectorized sampling, collision checking, and search. We provide an early theoretical investigation showing that GTMP exhibits probabilistic completeness while supporting modern GPU/TPU. Additionally, by incorporating smooth structures into the multipartite graph, GTMP directly plans smooth splines without requiring gradient-based optimization. Experiments on lidar-scanned occupancy maps and the MotionBenchMarker dataset demonstrate GTMP's computation efficiency in batch planning compared to baselines, underscoring GTMP's potential as a robust, scalable planner for diverse applications and large-scale robot learning tasks.
An Empirical Analysis of Measure-Valued Derivatives for Policy Gradients
Jul 20, 2021

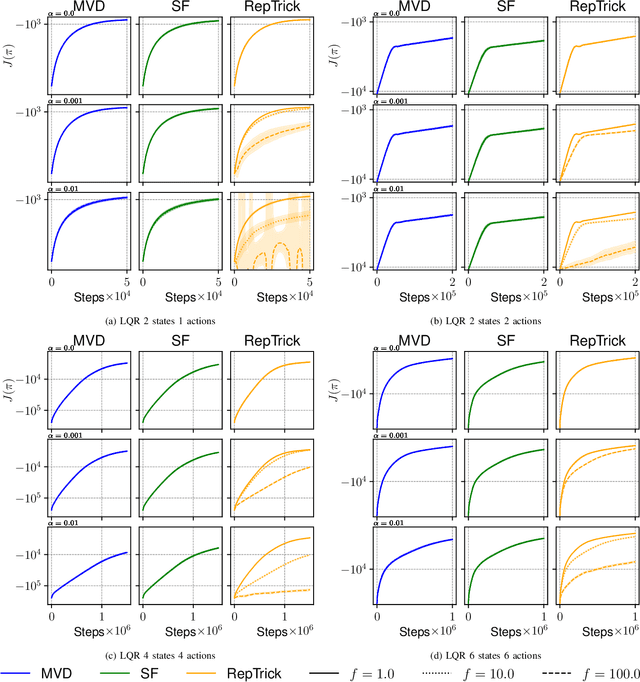
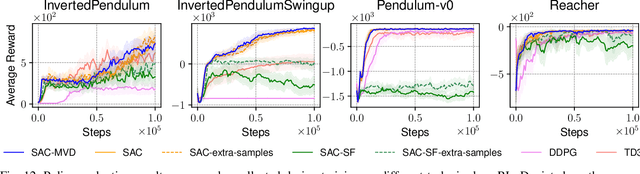
Reinforcement learning methods for robotics are increasingly successful due to the constant development of better policy gradient techniques. A precise (low variance) and accurate (low bias) gradient estimator is crucial to face increasingly complex tasks. Traditional policy gradient algorithms use the likelihood-ratio trick, which is known to produce unbiased but high variance estimates. More modern approaches exploit the reparametrization trick, which gives lower variance gradient estimates but requires differentiable value function approximators. In this work, we study a different type of stochastic gradient estimator: the Measure-Valued Derivative. This estimator is unbiased, has low variance, and can be used with differentiable and non-differentiable function approximators. We empirically evaluate this estimator in the actor-critic policy gradient setting and show that it can reach comparable performance with methods based on the likelihood-ratio or reparametrization tricks, both in low and high-dimensional action spaces.
Batch Reinforcement Learning with a Nonparametric Off-Policy Policy Gradient
Oct 29, 2020
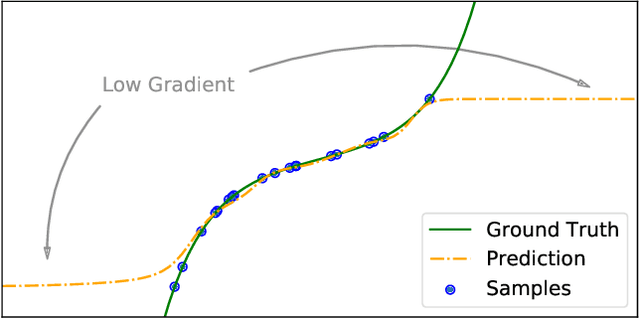
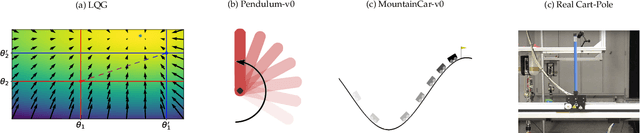
Off-policy Reinforcement Learning (RL) holds the promise of better data efficiency as it allows sample reuse and potentially enables safe interaction with the environment. Current off-policy policy gradient methods either suffer from high bias or high variance, delivering often unreliable estimates. The price of inefficiency becomes evident in real-world scenarios such as interaction-driven robot learning, where the success of RL has been rather limited, and a very high sample cost hinders straightforward application. In this paper, we propose a nonparametric Bellman equation, which can be solved in closed form. The solution is differentiable w.r.t the policy parameters and gives access to an estimation of the policy gradient. In this way, we avoid the high variance of importance sampling approaches, and the high bias of semi-gradient methods. We empirically analyze the quality of our gradient estimate against state-of-the-art methods, and show that it outperforms the baselines in terms of sample efficiency on classical control tasks.
Subspace Segmentation by Successive Approximations: A Method for Low-Rank and High-Rank Data with Missing Entries
Sep 05, 2017

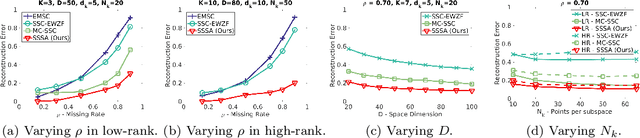
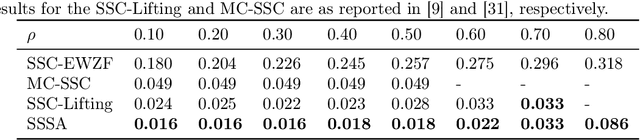
We propose a method to reconstruct and cluster incomplete high-dimensional data lying in a union of low-dimensional subspaces. Exploring the sparse representation model, we jointly estimate the missing data while imposing the intrinsic subspace structure. Since we have a non-convex problem, we propose an iterative method to reconstruct the data and provide a sparse similarity affinity matrix. This method is robust to initialization and achieves greater reconstruction accuracy than current methods, which dramatically improves clustering performance. Extensive experiments with synthetic and real data show that our approach leads to significant improvements in the reconstruction and segmentation, outperforming current state of the art for both low and high-rank data.
Understanding People Flow in Transportation Hubs
Apr 28, 2017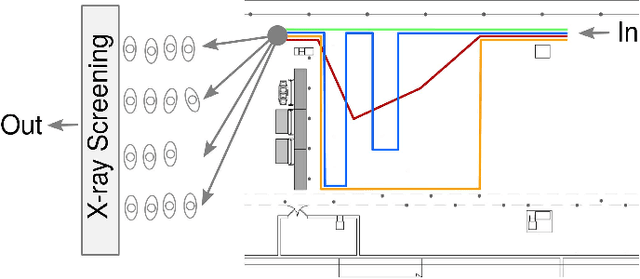
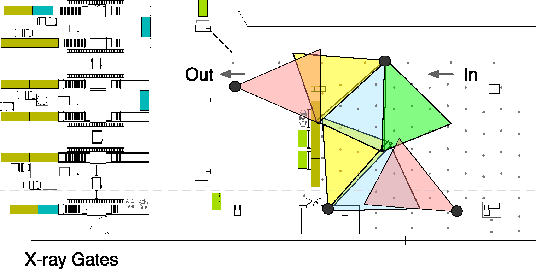
In this paper, we aim to monitor the flow of people in large public infrastructures. We propose an unsupervised methodology to cluster people flow patterns into the most typical and meaningful configurations. By processing 3D images from a network of depth cameras, we built a descriptor for the flow pattern. We define a data-irregularity measure that assesses how well each descriptor fits a data model. This allows us to rank the flow patterns from highly distinctive (outliers) to very common ones and, discarding outliers, obtain more reliable key configurations (classes). We applied this methodology in an operational scenario during 18 days in the X-ray screening area of an international airport. Results show that our methodology is able to summarize the representative patterns, a relevant information for airport management. Beyond regular flows our method identifies a set of rare events corresponding to uncommon activities (cleaning,special security and circulating staff). We demonstrate that for such a long observation period our methodology encapsulates the relevant "states" of the infrastructure in a very compact way.