 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparsity: Challenging Common Sparsity Assumptions for Learning World Models in Robotic Reinforcement Learning Benchmarks
Nov 14, 2025
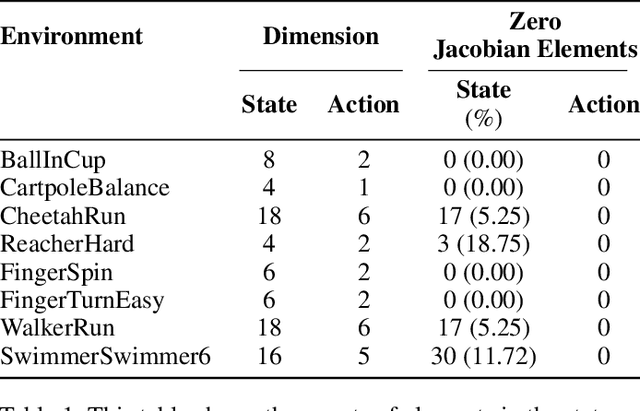
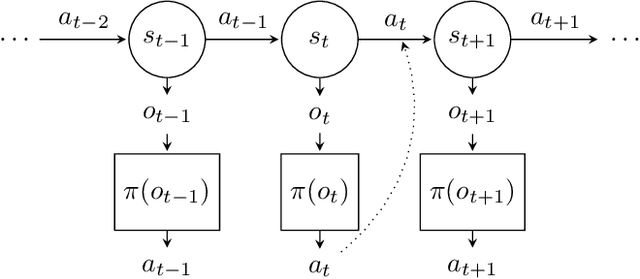

The use of learned dynamics models, also known as world models, can improve the sample efficiency of reinforcement learning. Recent work suggests that the underlying causal graphs of such dynamics models are sparsely connected, with each of the future state variables depending only on a small subset of the current state variables, and that learning may therefore benefit from sparsity priors. Similarly, temporal sparsity, i.e. sparsely and abruptly changing local dynamics, has also been proposed as a useful inductive bias. In this work, we critically examine these assumptions by analyzing ground-truth dynamics from a set of robotic reinforcement learning environments in the MuJoCo Playground benchmark suite, aiming to determine whether the proposed notions of state and temporal sparsity actually tend to hold in typical reinforcement learning tasks. We study (i) whether the causal graphs of environment dynamics are sparse, (ii) whether such sparsity is state-dependent, and (iii) whether local system dynamics change sparsely. Our results indicate that global sparsity is rare, but instead the tasks show local, state-dependent sparsity in their dynamics and this sparsity exhibits distinct structures, appearing in temporally localized clusters (e.g., during contact events) and affecting specific subsets of state dimensions. These findings challenge common sparsity prior assumptions in dynamics learning, emphasizing the need for grounded inductive biases that reflect the state-dependent sparsity structure of real-world dynamics.
Investigating the Benefits of Nonlinear Action Maps in Data-Driven Teleoperation
Oct 28, 2024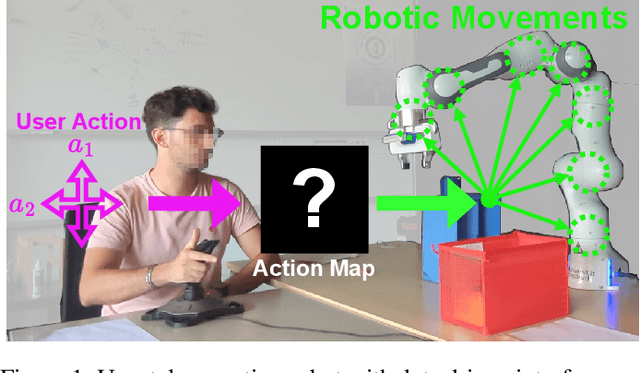

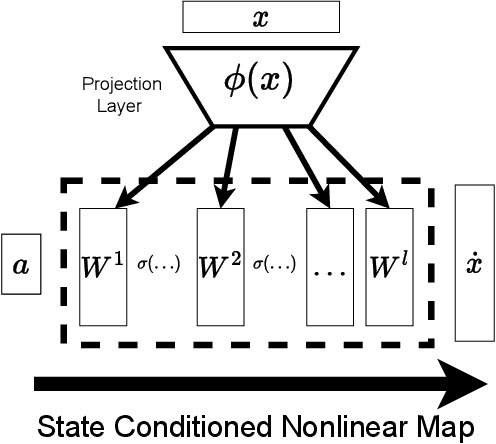

As robots become more common for both able-bodied individuals and those living with a disability, it is increasingly important that lay people be able to drive multi-degree-of-freedom platforms with low-dimensional controllers. One approach is to use state-conditioned action mapping methods to learn mappings between low-dimensional controllers and high DOF manipulators -- prior research suggests these mappings can simplify the teleoperation experience for users. Recent works suggest that neural networks predicting a local linear function are superior to the typical end-to-end multi-layer perceptrons because they allow users to more easily undo actions, providing more control over the system. However, local linear models assume actions exist on a linear subspace and may not capture nuanced actions in training data. We observe that the benefit of these mappings is being an odd function concerning user actions, and propose end-to-end nonlinear action maps which achieve this property. Unfortunately, our experiments show that such modifications offer minimal advantages over previous solutions. We find that nonlinear odd functions behave linearly for most of the control space, suggesting architecture structure improvements are not the primary factor in data-driven teleoperation. Our results suggest other avenues, such as data augmentation techniques and analysis of human behavior, are necessary for action maps to become practical in real-world applications, such as in assistive robotics to improve the quality of life of people living with w disability.
Deep Probabilistic Movement Primitives with a Bayesian Aggregator
Jul 11, 2023



Movement primitives are trainable parametric models that reproduce robotic movements starting from a limited set of demonstrations. Previous works proposed simple linear models that exhibited high sample efficiency and generalization power by allowing temporal modulation of movements (reproducing movements faster or slower), blending (merging two movements into one), via-point conditioning (constraining a movement to meet some particular via-points) and context conditioning (generation of movements based on an observed variable, e.g., position of an object). Previous works have proposed neural network-based motor primitive models, having demonstrated their capacity to perform tasks with some forms of input conditioning or time-modulation representations. However, there has not been a single unified deep motor primitive's model proposed that is capable of all previous operations, limiting neural motor primitive's potential applications. This paper proposes a deep movement primitive architecture that encodes all the operations above and uses a Bayesian context aggregator that allows a more sound context conditioning and blending. Our results demonstrate our approach can scale to reproduce complex motions on a larger variety of input choices compared to baselines while maintaining operations of linear movement primitives provide.
Variable-Decision Frequency Option Critic
Dec 11, 2022

In classic reinforcement learning algorithms, agents make decisions at discrete and fixed time intervals. The physical duration between one decision and the next becomes a critical hyperparameter. When this duration is too short, the agent needs to make many decisions to achieve its goal, aggravating the problem's difficulty. But when this duration is too long, the agent becomes incapable of controlling the system. Physical systems, however, do not need a constant control frequency. For learning agents, it is desirable to operate with low frequency when possible and high frequency when necessary. We propose a framework called Continuous-Time Continuous-Options (CTCO), where the agent chooses options as sub-policies of variable durations. Such options are time-continuous and can interact with the system at any desired frequency providing a smooth change of actions. The empirical analysis shows that our algorithm is competitive w.r.t. other time-abstraction techniques, such as classic option learning and action repetition, and practically overcomes the difficult choice of the decision frequency.
A Temporal-Difference Approach to Policy Gradient Estimation
Feb 04, 2022
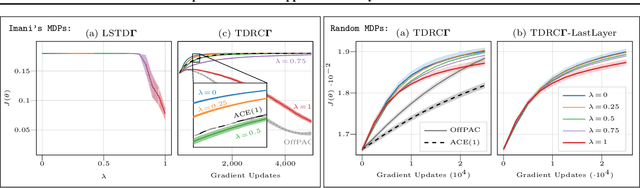
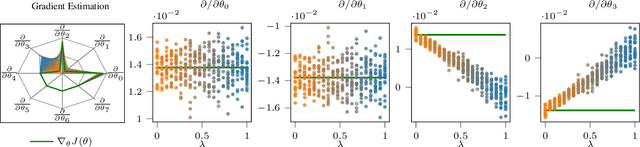
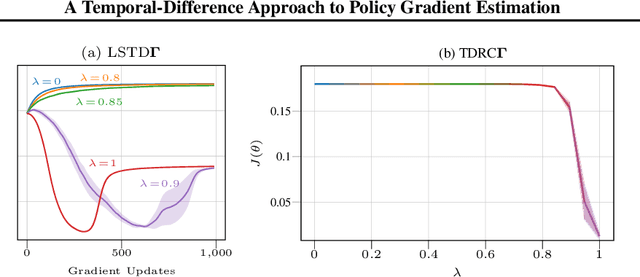
The policy gradient theorem (Sutton et al., 2000) prescribes the usage of a cumulative discounted state distribution under the target policy to approximate the gradient. Most algorithms based on this theorem, in practice, break this assumption, introducing a distribution shift that can cause the convergence to poor solutions. In this paper, we propose a new approach of reconstructing the policy gradient from the start state without requiring a particular sampling strategy. The policy gradient calculation in this form can be simplified in terms of a gradient critic, which can be recursively estimated due to a new Bellman equation of gradients. By using temporal-difference updates of the gradient critic from an off-policy data stream, we develop the first estimator that sidesteps the distribution shift issue in a model-free way. We prove that, under certain realizability conditions, our estimator is unbiased regardless of the sampling strategy. We empirically show that our technique achieves a superior bias-variance trade-off and performance in presence of off-policy samples.
An Alternate Policy Gradient Estimator for Softmax Policies
Dec 22, 2021
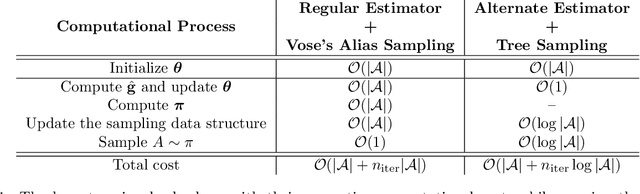
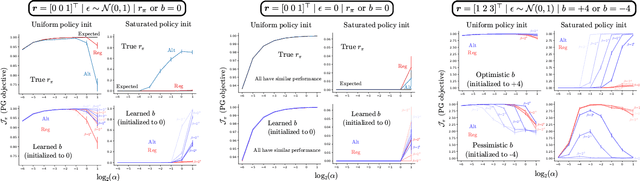
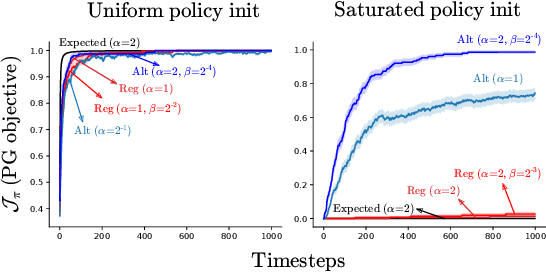
Policy gradient (PG) estimators for softmax policies are ineffective with sub-optimally saturated initialization, which happens when the density concentrates on a sub-optimal action. Sub-optimal policy saturation may arise from bad policy initialization or sudden changes in the environment that occur after the policy has already converged, and softmax PG estimators require a large number of updates to recover an effective policy. This severe issue causes high sample inefficiency and poor adaptability to new situations. To mitigate this problem, we propose a novel policy gradient estimator for softmax policies that utilizes the bias in the critic estimate and the noise present in the reward signal to escape the saturated regions of the policy parameter space. Our analysis and experiments, conducted on bandits and classical MDP benchmarking tasks, show that our estimator is more robust to policy saturation.
Batch Reinforcement Learning with a Nonparametric Off-Policy Policy Gradient
Oct 29, 2020
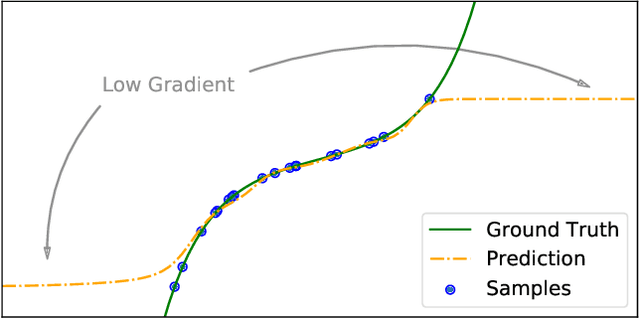
Off-policy Reinforcement Learning (RL) holds the promise of better data efficiency as it allows sample reuse and potentially enables safe interaction with the environment. Current off-policy policy gradient methods either suffer from high bias or high variance, delivering often unreliable estimates. The price of inefficiency becomes evident in real-world scenarios such as interaction-driven robot learning, where the success of RL has been rather limited, and a very high sample cost hinders straightforward application. In this paper, we propose a nonparametric Bellman equation, which can be solved in closed form. The solution is differentiable w.r.t the policy parameters and gives access to an estimation of the policy gradient. In this way, we avoid the high variance of importance sampling approaches, and the high bias of semi-gradient methods. We empirically analyze the quality of our gradient estimate against state-of-the-art methods, and show that it outperforms the baselines in terms of sample efficiency on classical control tasks.
Contextual Latent-Movements Off-Policy Optimization for Robotic Manipulation Skills
Oct 26, 2020



Parameterized movement primitives have been extensively used for imitation learning of robotic tasks. However, the high-dimensionality of the parameter space hinders the improvement of such primitives in the reinforcement learning (RL) setting, especially for learning with physical robots. In this paper we propose a novel view on handling the demonstrated trajectories for acquiring low-dimensional, non-linear latent dynamics, using mixtures of probabilistic principal component analyzers (MPPCA) on the movements' parameter space. Moreover, we introduce a new contextual off-policy RL algorithm, named LAtent-Movements Policy Optimization (LAMPO). LAMPO can provide gradient estimates from previous experience using self-normalized importance sampling, hence, making full use of samples collected in previous learning iterations. These advantages combined provide a complete framework for sample-efficient off-policy optimization of movement primitives for robot learning of high-dimensional manipulation skills. Our experimental results conducted both in simulation and on a real robot show that LAMPO provides sample-efficient policies against common approaches in literature.
Dimensionality Reduction of Movement Primitives in Parameter Space
Feb 26, 2020



Movement primitives are an important policy class for real-world robotics. However, the high dimensionality of their parametrization makes the policy optimization expensive both in terms of samples and computation. Enabling an efficient representation of movement primitives facilitates the application of machine learning techniques such as reinforcement on robotics. Motions, especially in highly redundant kinematic structures, exhibit high correlation in the configuration space. For these reasons, prior work has mainly focused on the application of dimensionality reduction techniques in the configuration space. In this paper, we investigate the application of dimensionality reduction in the parameter space, identifying principal movements. The resulting approach is enriched with a probabilistic treatment of the parameters, inheriting all the properties of the Probabilistic Movement Primitives. We test the proposed technique both on a real robotic task and on a database of complex human movements. The empirical analysis shows that the dimensionality reduction in parameter space is more effective than in configuration space, as it enables the representation of the movements with a significant reduction of parameters.
A Nonparametric Off-Policy Policy Gradient
Feb 11, 2020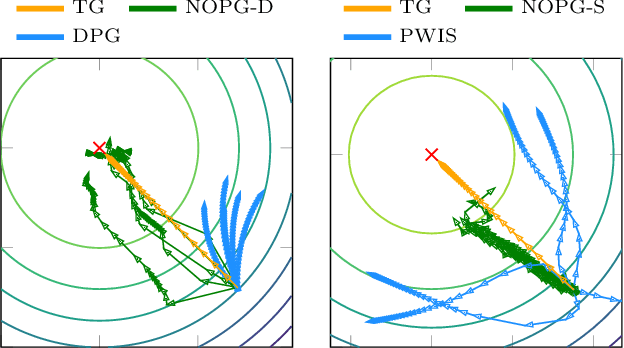



Reinforcement learning (RL) algorithms still suffer from high sample complexity despite outstanding recent successes. The need for intensive interactions with the environment is especially observed in many widely popular policy gradient algorithms that perform updates using on-policy samples. The price of such inefficiency becomes evident in real-world scenarios such as interaction-driven robot learning, where the success of RL has been rather limited. We address this issue by building on the general sample efficiency of off-policy algorithms. With nonparametric regression and density estimation methods we construct a nonparametric Bellman equation in a principled manner, which allows us to obtain closed-form estimates of the value function, and to analytically express the full policy gradient. We provide a theoretical analysis of our estimate to show that it is consistent under mild smoothness assumptions and empirically show that our approach has better sample efficiency than state-of-the-art policy gradient methods.