 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Alternate Policy Gradient Estimator for Softmax Policies
Paper and Code

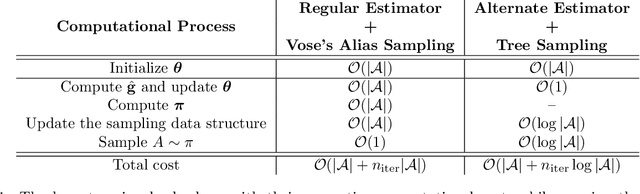
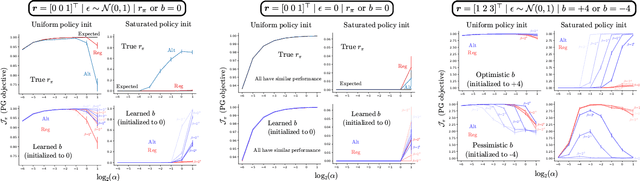
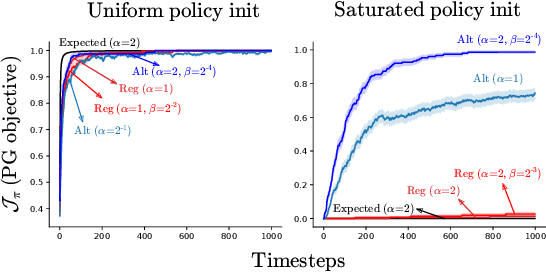
Policy gradient (PG) estimators for softmax policies are ineffective with sub-optimally saturated initialization, which happens when the density concentrates on a sub-optimal action. Sub-optimal policy saturation may arise from bad policy initialization or sudden changes in the environment that occur after the policy has already converged, and softmax PG estimators require a large number of updates to recover an effective policy. This severe issue causes high sample inefficiency and poor adaptability to new situations. To mitigate this problem, we propose a novel policy gradient estimator for softmax policies that utilizes the bias in the critic estimate and the noise present in the reward signal to escape the saturated regions of the policy parameter space. Our analysis and experiments, conducted on bandits and classical MDP benchmarking tasks, show that our estimator is more robust to policy saturation.