 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFODMP: Fast One-Step Diffusion of Movement Primitives Generation for Time-Dependent Robot Actions
Mar 25, 2026Diffusion models are increasingly used for robot learning, but current designs face a clear trade-off. Action-chunking diffusion policies like ManiCM are fast to run, yet they only predict short segments of motion. This makes them reactive, but unable to capture time-dependent motion primitives, such as following a spring-damper-like behavior with built-in dynamic profiles of acceleration and deceleration. Recently, Movement Primitive Diffusion (MPD) partially addresses this limitation by parameterizing full trajectories using Probabilistic Dynamic Movement Primitives (ProDMPs), thereby enabling the generation of temporally structured motions. Nevertheless, MPD integrates the motion decoder directly into a multi-step diffusion process, resulting in prohibitively high inference latency that limits its applicability in real-time control settings. We propose FODMP (Fast One-step Diffusion of Movement Primitives), a new framework that distills diffusion models into the ProDMPs trajectory parameter space and generates motion using a single-step decoder. FODMP retains the temporal structure of movement primitives while eliminating the inference bottleneck through single-step consistency distillation. This enables robots to execute time-dependent primitives at high inference speed, suitable for closed-loop vision-based control. On standard manipulation benchmarks (MetaWorld, ManiSkill), FODMP runs up to 10 times faster than MPD and 7 times faster than action-chunking diffusion policies, while matching or exceeding their success rates. Beyond speed, by generating fast acceleration-deceleration motion primitives, FODMP allows the robot to intercept and securely catch a fast-flying ball, whereas action-chunking diffusion policy and MPD respond too slowly for real-time interception.
Why Do Neural Networks Forget: A Study of Collapse in Continual Learning
Mar 04, 2026Catastrophic forgetting is a major problem in continual learning, and lots of approaches arise to reduce it. However, most of them are evaluated through task accuracy, which ignores the internal model structure. Recent research suggests that structural collapse leads to loss of plasticity, as evidenced by changes in effective rank (eRank). This indicates a link to forgetting, since the networks lose the ability to expand their feature space to learn new tasks, which forces the network to overwrite existing representations. Therefore, in this study, we investigate the correlation between forgetting and collapse through the measurement of both weight and activation eRank. To be more specific, we evaluated four architectures, including MLP, ConvGRU, ResNet-18, and Bi-ConvGRU, in the split MNIST and Split CIFAR-100 benchmarks. Those models are trained through the SGD, Learning-without-Forgetting (LwF), and Experience Replay (ER) strategies separately. The results demonstrate that forgetting and collapse are strongly related, and different continual learning strategies help models preserve both capacity and performance in different efficiency.
Principled Fast and Meta Knowledge Learners for Continual Reinforcement Learning
Mar 01, 2026Inspired by the human learning and memory system, particularly the interplay between the hippocampus and cerebral cortex, this study proposes a dual-learner framework comprising a fast learner and a meta learner to address continual Reinforcement Learning~(RL) problems. These two learners are coupled to perform distinct yet complementary roles: the fast learner focuses on knowledge transfer, while the meta learner ensures knowledge integration. In contrast to traditional multi-task RL approaches that share knowledge through average return maximization, our meta learner incrementally integrates new experiences by explicitly minimizing catastrophic forgetting, thereby supporting efficient cumulative knowledge transfer for the fast learner. To facilitate rapid adaptation in new environments, we introduce an adaptive meta warm-up mechanism that selectively harnesses past knowledge. We conduct experiments in various pixel-based and continuous control benchmarks, revealing the superior performance of continual learning for our proposed dual-learner approach relative to baseline methods. The code is released in https://github.com/datake/FAME.
RA-DP: Rapid Adaptive Diffusion Policy for Training-Free High-frequency Robotics Replanning
Mar 06, 2025



Diffusion models exhibit impressive scalability in robotic task learning, yet they struggle to adapt to novel, highly dynamic environments. This limitation primarily stems from their constrained replanning ability: they either operate at a low frequency due to a time-consuming iterative sampling process, or are unable to adapt to unforeseen feedback in case of rapid replanning. To address these challenges, we propose RA-DP, a novel diffusion policy framework with training-free high-frequency replanning ability that solves the above limitations in adapting to unforeseen dynamic environments. Specifically, our method integrates guidance signals which are often easily obtained in the new environment during the diffusion sampling process, and utilizes a novel action queue mechanism to generate replanned actions at every denoising step without retraining, thus forming a complete training-free framework for robot motion adaptation in unseen environments. Extensive evaluations have been conducted in both well-recognized simulation benchmarks and real robot tasks. Results show that RA-DP outperforms the state-of-the-art diffusion-based methods in terms of replanning frequency and success rate. Moreover, we show that our framework is theoretically compatible with any training-free guidance signal.
FRMD: Fast Robot Motion Diffusion with Consistency-Distilled Movement Primitives for Smooth Action Generation
Mar 03, 2025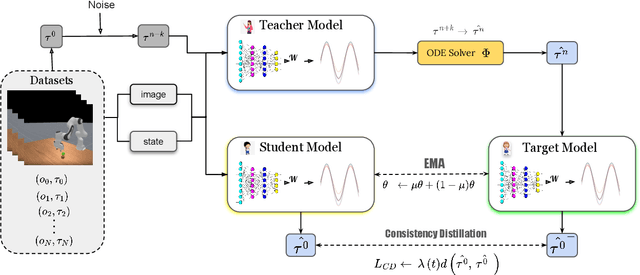
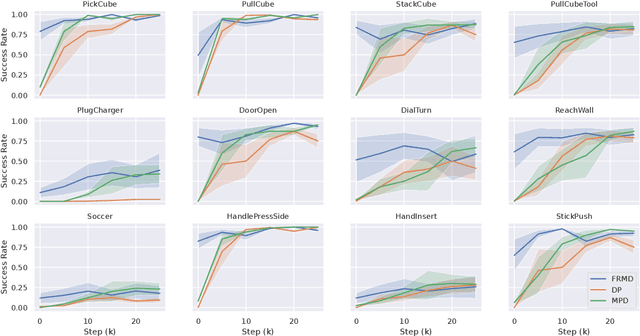
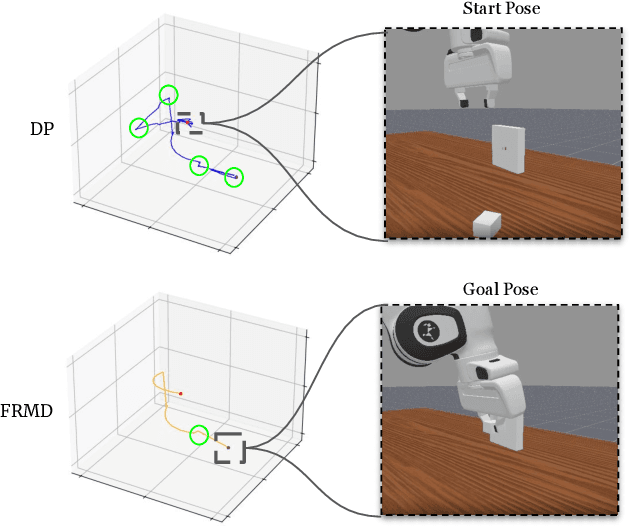
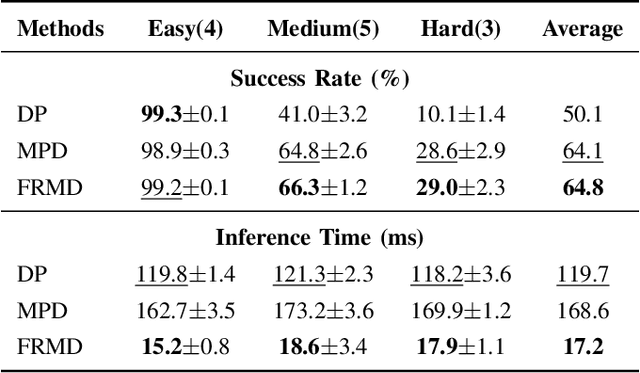
We consider the problem of using diffusion models to generate fast, smooth, and temporally consistent robot motions. Although diffusion models have demonstrated superior performance in robot learning due to their task scalability and multi-modal flexibility, they suffer from two fundamental limitations: (1) they often produce non-smooth, jerky motions due to their inability to capture temporally consistent movement dynamics, and (2) their iterative sampling process incurs prohibitive latency for many robotic tasks. Inspired by classic robot motion generation methods such as DMPs and ProMPs, which capture temporally and spatially consistent dynamic of trajectories using low-dimensional vectors -- and by recent advances in diffusion-based image generation that use consistency models with probability flow ODEs to accelerate the denoising process, we propose Fast Robot Motion Diffusion (FRMD). FRMD uniquely integrates Movement Primitives (MPs) with Consistency Models to enable efficient, single-step trajectory generation. By leveraging probabilistic flow ODEs and consistency distillation, our method models trajectory distributions while learning a compact, time-continuous motion representation within an encoder-decoder architecture. This unified approach eliminates the slow, multi-step denoising process of conventional diffusion models, enabling efficient one-step inference and smooth robot motion generation. We extensively evaluated our FRMD on the well-recognized Meta-World and ManiSkills Benchmarks, ranging from simple to more complex manipulation tasks, comparing its performance against state-of-the-art baselines. Our results show that FRMD generates significantly faster, smoother trajectories while achieving higher success rates.
LaFFi: Leveraging Hybrid Natural Language Feedback for Fine-tuning Language Models
Dec 31, 2023Fine-tuning Large Language Models (LLMs) adapts a trained model to specific downstream tasks, significantly improving task-specific performance. Supervised Fine-Tuning (SFT) is a common approach, where an LLM is trained to produce desired answers. However, LLMs trained with SFT sometimes make simple mistakes and result in hallucinations on reasoning tasks such as question-answering. Without external feedback, it is difficult for SFT to learn a good mapping between the question and the desired answer, especially with a small dataset. This paper introduces an alternative to SFT called Natural Language Feedback for Finetuning LLMs (LaFFi). LaFFi has LLMs directly predict the feedback they will receive from an annotator. We find that requiring such reflection can significantly improve the accuracy in in-domain question-answering tasks, providing a promising direction for the application of natural language feedback in the realm of SFT LLMs. Additional ablation studies show that the portion of human-annotated data in the annotated datasets affects the fine-tuning performance.
EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought
May 24, 2023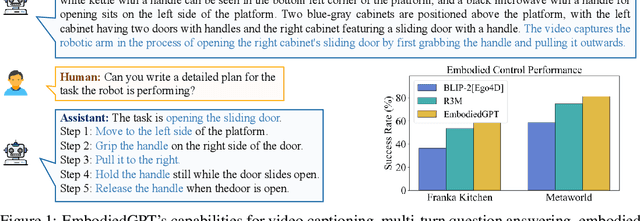

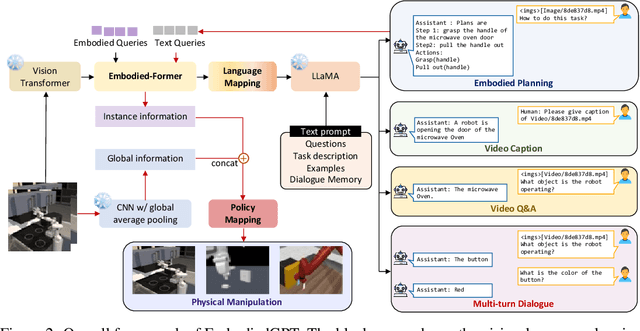

Embodied AI is a crucial frontier in robotics, capable of planning and executing action sequences for robots to accomplish long-horizon tasks in physical environments. In this work, we introduce EmbodiedGPT, an end-to-end multi-modal foundation model for embodied AI, empowering embodied agents with multi-modal understanding and execution capabilities. To achieve this, we have made the following efforts: (i) We craft a large-scale embodied planning dataset, termed EgoCOT. The dataset consists of carefully selected videos from the Ego4D dataset, along with corresponding high-quality language instructions. Specifically, we generate a sequence of sub-goals with the "Chain of Thoughts" mode for effective embodied planning. (ii) We introduce an efficient training approach to EmbodiedGPT for high-quality plan generation, by adapting a 7B large language model (LLM) to the EgoCOT dataset via prefix tuning. (iii) We introduce a paradigm for extracting task-related features from LLM-generated planning queries to form a closed loop between high-level planning and low-level control. Extensive experiments show the effectiveness of EmbodiedGPT on embodied tasks, including embodied planning, embodied control, visual captioning, and visual question answering. Notably, EmbodiedGPT significantly enhances the success rate of the embodied control task by extracting more effective features. It has achieved a remarkable 1.6 times increase in success rate on the Franka Kitchen benchmark and a 1.3 times increase on the Meta-World benchmark, compared to the BLIP-2 baseline fine-tuned with the Ego4D dataset.
A Simple Decentralized Cross-Entropy Method
Dec 16, 2022



Cross-Entropy Method (CEM) is commonly used for planning in model-based reinforcement learning (MBRL) where a centralized approach is typically utilized to update the sampling distribution based on only the top-$k$ operation's results on samples. In this paper, we show that such a centralized approach makes CEM vulnerable to local optima, thus impairing its sample efficiency. To tackle this issue, we propose Decentralized CEM (DecentCEM), a simple but effective improvement over classical CEM, by using an ensemble of CEM instances running independently from one another, and each performing a local improvement of its own sampling distribution. We provide both theoretical and empirical analysis to demonstrate the effectiveness of this simple decentralized approach. We empirically show that, compared to the classical centralized approach using either a single or even a mixture of Gaussian distributions, our DecentCEM finds the global optimum much more consistently thus improves the sample efficiency. Furthermore, we plug in our DecentCEM in the planning problem of MBRL, and evaluate our approach in several continuous control environments, with comparison to the state-of-art CEM based MBRL approaches (PETS and POPLIN). Results show sample efficiency improvement by simply replacing the classical CEM module with our DecentCEM module, while only sacrificing a reasonable amount of computational cost. Lastly, we conduct ablation studies for more in-depth analysis. Code is available at https://github.com/vincentzhang/decentCEM
Variable-Decision Frequency Option Critic
Dec 11, 2022

In classic reinforcement learning algorithms, agents make decisions at discrete and fixed time intervals. The physical duration between one decision and the next becomes a critical hyperparameter. When this duration is too short, the agent needs to make many decisions to achieve its goal, aggravating the problem's difficulty. But when this duration is too long, the agent becomes incapable of controlling the system. Physical systems, however, do not need a constant control frequency. For learning agents, it is desirable to operate with low frequency when possible and high frequency when necessary. We propose a framework called Continuous-Time Continuous-Options (CTCO), where the agent chooses options as sub-policies of variable durations. Such options are time-continuous and can interact with the system at any desired frequency providing a smooth change of actions. The empirical analysis shows that our algorithm is competitive w.r.t. other time-abstraction techniques, such as classic option learning and action repetition, and practically overcomes the difficult choice of the decision frequency.
CWD: A Machine Learning based Approach to Detect Unknown Cloud Workloads
Nov 28, 2022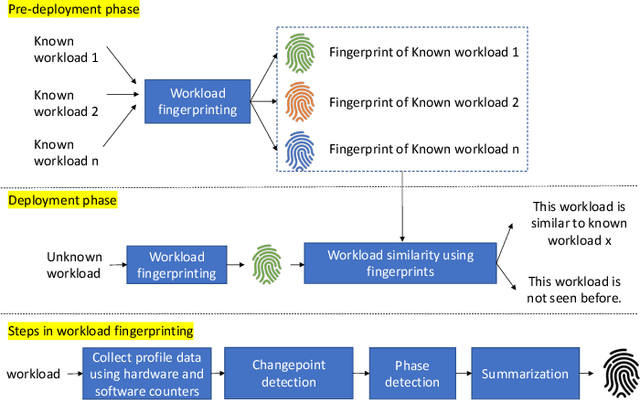
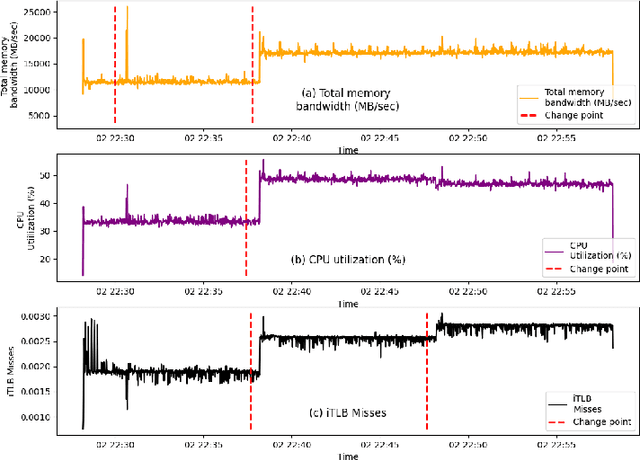
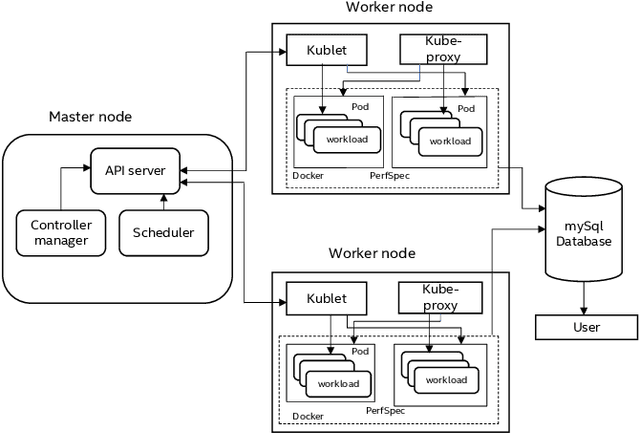
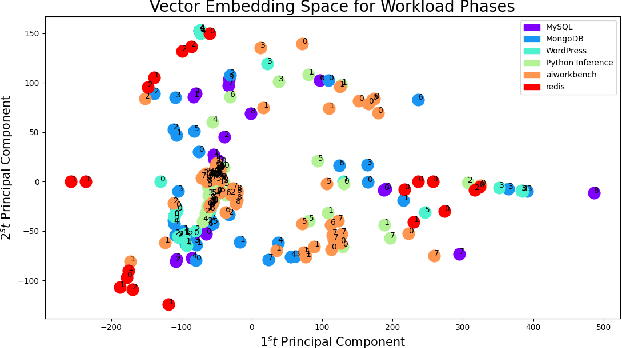
Workloads in modern cloud data centers are becoming increasingly complex. The number of workloads running in cloud data centers has been growing exponentially for the last few years, and cloud service providers (CSP) have been supporting on-demand services in real-time. Realizing the growing complexity of cloud environment and cloud workloads, hardware vendors such as Intel and AMD are increasingly introducing cloud-specific workload acceleration features in their CPU platforms. These features are typically targeted towards popular and commonly-used cloud workloads. Nonetheless, uncommon, customer-specific workloads (unknown workloads), if their characteristics are different from common workloads (known workloads), may not realize the potential of the underlying platform. To address this problem of realizing the full potential of the underlying platform, we develop a machine learning based technique to characterize, profile and predict workloads running in the cloud environment. Experimental evaluation of our technique demonstrates good prediction performance. We also develop techniques to analyze the performance of the model in a standalone manner.