 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaOptimize: A Framework for Optimizing Step Sizes and Other Meta-parameters
Feb 12, 2024



This paper addresses the challenge of optimizing meta-parameters (i.e., hyperparameters) in machine learning algorithms, a critical factor influencing training efficiency and model performance. Moving away from the computationally expensive traditional meta-parameter search methods, we introduce MetaOptimize framework that dynamically adjusts meta-parameters, particularly step sizes (also known as learning rates), during training. More specifically, MetaOptimize can wrap around any first-order optimization algorithm, tuning step sizes on the fly to minimize a specific form of regret that accounts for long-term effect of step sizes on training, through a discounted sum of future losses. We also introduce low complexity variants of MetaOptimize that, in conjunction with its adaptability to multiple optimization algorithms, demonstrate performance competitive to those of best hand-crafted learning rate schedules across various machine learning applications.
Step-size Optimization for Continual Learning
Jan 30, 2024In continual learning, a learner has to keep learning from the data over its whole life time. A key issue is to decide what knowledge to keep and what knowledge to let go. In a neural network, this can be implemented by using a step-size vector to scale how much gradient samples change network weights. Common algorithms, like RMSProp and Adam, use heuristics, specifically normalization, to adapt this step-size vector. In this paper, we show that those heuristics ignore the effect of their adaptation on the overall objective function, for example by moving the step-size vector away from better step-size vectors. On the other hand, stochastic meta-gradient descent algorithms, like IDBD (Sutton, 1992), explicitly optimize the step-size vector with respect to the overall objective function. On simple problems, we show that IDBD is able to consistently improve step-size vectors, where RMSProp and Adam do not. We explain the differences between the two approaches and their respective limitations. We conclude by suggesting that combining both approaches could be a promising future direction to improve the performance of neural networks in continual learning.
Toward Efficient Gradient-Based Value Estimation
Jan 31, 2023



Gradient-based methods for value estimation in reinforcement learning have favorable stability properties, but they are typically much slower than Temporal Difference (TD) learning methods. We study the root causes of this slowness and show that Mean Square Bellman Error (MSBE) is an ill-conditioned loss function in the sense that its Hessian has large condition-number. To resolve the adverse effect of poor conditioning of MSBE on gradient based methods, we propose a low complexity batch-free proximal method that approximately follows the Gauss-Newton direction and is asymptotically robust to parameterization. Our main algorithm, called RANS, is efficient in the sense that it is significantly faster than the residual gradient methods while having almost the same computational complexity, and is competitive with TD on the classic problems that we tested.
Auxiliary task discovery through generate-and-test
Oct 25, 2022

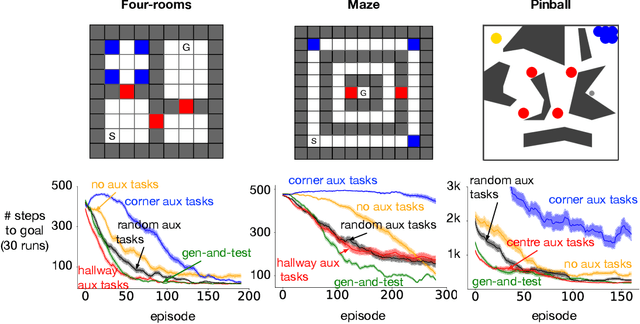
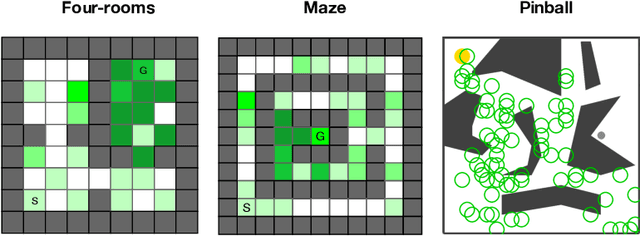
In this paper, we explore an approach to auxiliary task discovery in reinforcement learning based on ideas from representation learning. Auxiliary tasks tend to improve data efficiency by forcing the agent to learn auxiliary prediction and control objectives in addition to the main task of maximizing reward, and thus producing better representations. Typically these tasks are designed by people. Meta-learning offers a promising avenue for automatic task discovery; however, these methods are computationally expensive and challenging to tune in practice. In this paper, we explore a complementary approach to the auxiliary task discovery: continually generating new auxiliary tasks and preserving only those with high utility. We also introduce a new measure of auxiliary tasks usefulness based on how useful the features induced by them are for the main task. Our discovery algorithm significantly outperforms random tasks, hand-designed tasks, and learning without auxiliary tasks across a suite of environments.
Behaviour Suite for Reinforcement Learning
Aug 13, 2019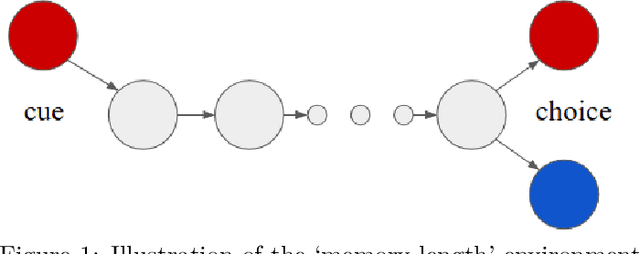
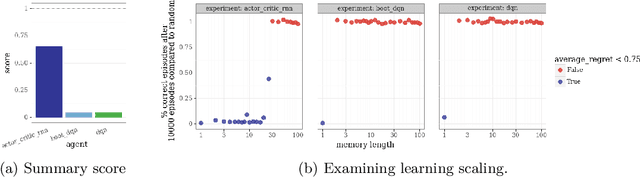
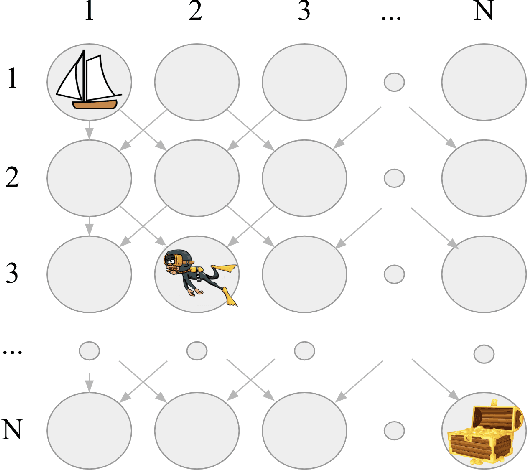
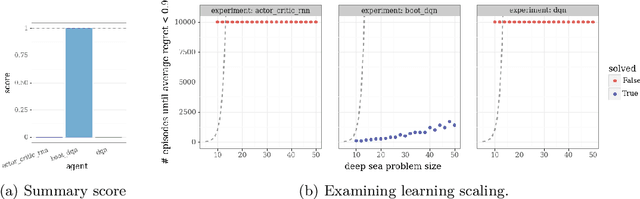
This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks. To complement this effort, we open source github.com/deepmind/bsuite, which automates evaluation and analysis of any agent on bsuite. This library facilitates reproducible and accessible research on the core issues in RL, and ultimately the design of superior learning algorithms. Our code is Python, and easy to use within existing projects. We include examples with OpenAI Baselines, Dopamine as well as new reference implementations. Going forward, we hope to incorporate more excellent experiments from the research community, and commit to a periodic review of bsuite from a committee of prominent researchers.