 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise Reasoning via Reinforcement Learning
Apr 07, 2025Despite significant advancements in large language models (LLMs), a major drawback of reasoning models is their enormous token usage, which increases computational cost, resource requirements, and response time. In this work, we revisit the core principles of reinforcement learning (RL) and, through mathematical analysis, demonstrate that the tendency to generate lengthy responses arises inherently from RL-based optimization during training. This finding questions the prevailing assumption that longer responses inherently improve reasoning accuracy. Instead, we uncover a natural correlation between conciseness and accuracy that has been largely overlooked. Moreover, we show that introducing a secondary phase of RL post-training, using a small set of problems and limited resources, can significantly reduce a model's chain of thought while maintaining or even enhancing accuracy. Finally, we validate our conclusions through extensive experimental results.
Auxiliary task discovery through generate-and-test
Oct 25, 2022In this paper, we explore an approach to auxiliary task discovery in reinforcement learning based on ideas from representation learning. Auxiliary tasks tend to improve data efficiency by forcing the agent to learn auxiliary prediction and control objectives in addition to the main task of maximizing reward, and thus producing better representations. Typically these tasks are designed by people. Meta-learning offers a promising avenue for automatic task discovery; however, these methods are computationally expensive and challenging to tune in practice. In this paper, we explore a complementary approach to the auxiliary task discovery: continually generating new auxiliary tasks and preserving only those with high utility. We also introduce a new measure of auxiliary tasks usefulness based on how useful the features induced by them are for the main task. Our discovery algorithm significantly outperforms random tasks, hand-designed tasks, and learning without auxiliary tasks across a suite of environments.
What makes useful auxiliary tasks in reinforcement learning: investigating the effect of the target policy
Apr 01, 2022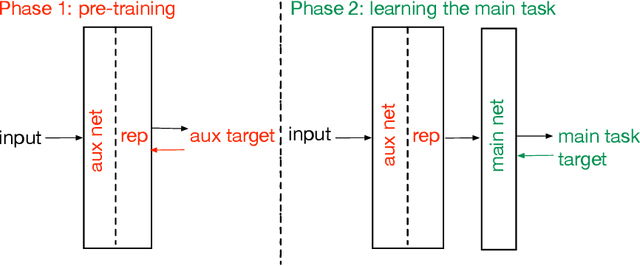


Auxiliary tasks have been argued to be useful for representation learning in reinforcement learning. Although many auxiliary tasks have been empirically shown to be effective for accelerating learning on the main task, it is not yet clear what makes useful auxiliary tasks. Some of the most promising results are on the pixel control, reward prediction, and the next state prediction auxiliary tasks; however, the empirical results are mixed, showing substantial improvements in some cases and marginal improvements in others. Careful investigations of how auxiliary tasks help the learning of the main task is necessary. In this paper, we take a step studying the effect of the target policies on the usefulness of the auxiliary tasks formulated as general value functions. General value functions consist of three core elements: 1) policy 2) cumulant 3) continuation function. Our focus on the role of the target policy of the auxiliary tasks is motivated by the fact that the target policy determines the behavior about which the agent wants to make a prediction and the state-action distribution that the agent is trained on, which further affects the main task learning. Our study provides insights about questions such as: Does a greedy policy result in bigger improvement gains compared to other policies? Is it best to set the auxiliary task policy to be the same as the main task policy? Does the choice of the target policy have a substantial effect on the achieved performance gain or simple strategies for setting the policy, such as using a uniformly random policy, work as well? Our empirical results suggest that: 1) Auxiliary tasks with the greedy policy tend to be useful. 2) Most policies, including a uniformly random policy, tend to improve over the baseline. 3) Surprisingly, the main task policy tends to be less useful compared to other policies.
Testbeds for Reinforcement Learning
Nov 13, 2020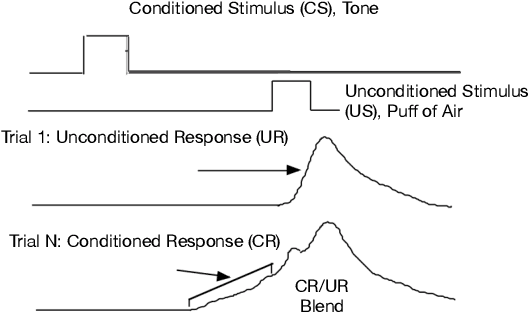
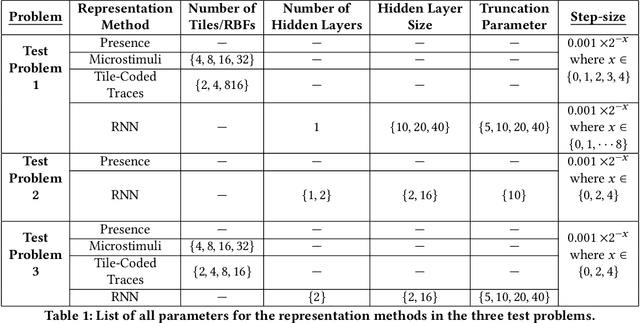
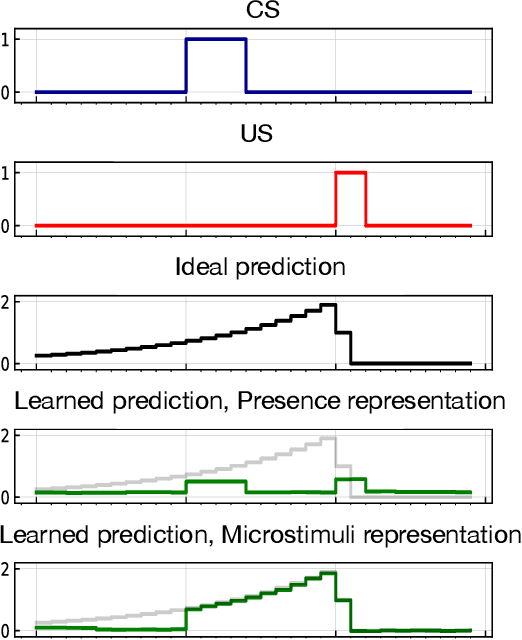

We present three problems modeled after animal learning experiments designed to test online state construction or representation learning algorithms. Our test problems require the learner to construct compact summaries of their past interaction with the world in order to predict the future, updating online and incrementally on each time step without an explicit training-testing split. The majority of recent work in Deep Reinforcement Learning focuses on either fully observable tasks, or games where stacking a handful of recent frames is sufficient for good performance. Current benchmarks used for evaluating memory and recurrent learning make use of 3D visual environments (e.g., DeepMind Lab) which require billions of training samples, complex agent architectures, and cloud-scale compute. These domains are thus not well suited for rapid prototyping, hyper-parameter study, or extensive replication study. In this paper, we contribute a set of test problems and benchmark results to fill this gap. Our test problems are designed to be the simplest instantiation and test of learning capabilities which animals readily exhibit, including (1) trace conditioning (remembering a cue in order to predict another far in the future), (2) positive/negative patterning (a combination of cues predict another), (3) and combinations of both with additional non-relevant distracting signals. We provide baselines for the first problem including heuristics from the early days of neural network learning and simple ideas inspired by computational models of animal learning. Our results highlight the difficulty of our test problems for online recurrent learning systems and how the agent's performance often exhibits substantial sensitivity to the choice of key problem and agent parameters.
Improving Performance in Reinforcement Learning by Breaking Generalization in Neural Networks
Mar 16, 2020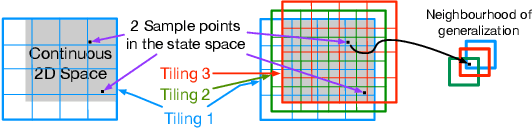
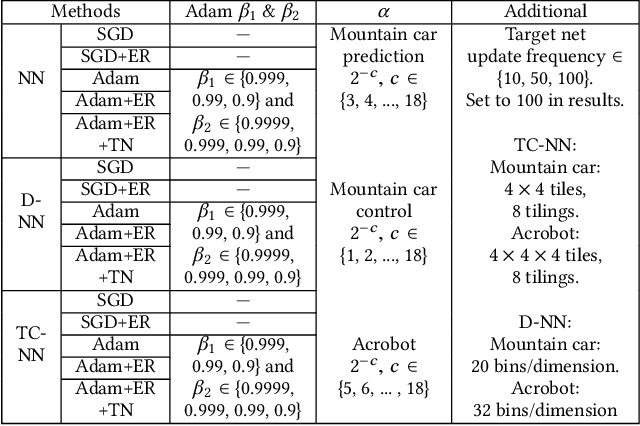
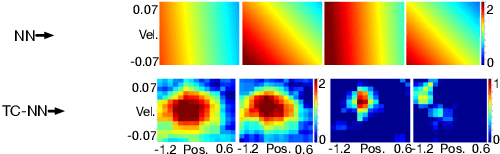

Reinforcement learning systems require good representations to work well. For decades practical success in reinforcement learning was limited to small domains. Deep reinforcement learning systems, on the other hand, are scalable, not dependent on domain specific prior knowledge and have been successfully used to play Atari, in 3D navigation from pixels, and to control high degree of freedom robots. Unfortunately, the performance of deep reinforcement learning systems is sensitive to hyper-parameter settings and architecture choices. Even well tuned systems exhibit significant instability both within a trial and across experiment replications. In practice, significant expertise and trial and error are usually required to achieve good performance. One potential source of the problem is known as catastrophic interference: when later training decreases performance by overriding previous learning. Interestingly, the powerful generalization that makes Neural Networks (NN) so effective in batch supervised learning might explain the challenges when applying them in reinforcement learning tasks. In this paper, we explore how online NN training and interference interact in reinforcement learning. We find that simply re-mapping the input observations to a high-dimensional space improves learning speed and parameter sensitivity. We also show this preprocessing reduces interference in prediction tasks. More practically, we provide a simple approach to NN training that is easy to implement, and requires little additional computation. We demonstrate that our approach improves performance in both prediction and control with an extensive batch of experiments in classic control domains.
Two geometric input transformation methods for fast online reinforcement learning with neural nets
Sep 06, 2018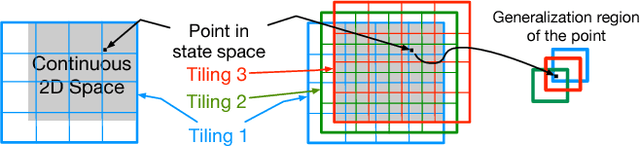
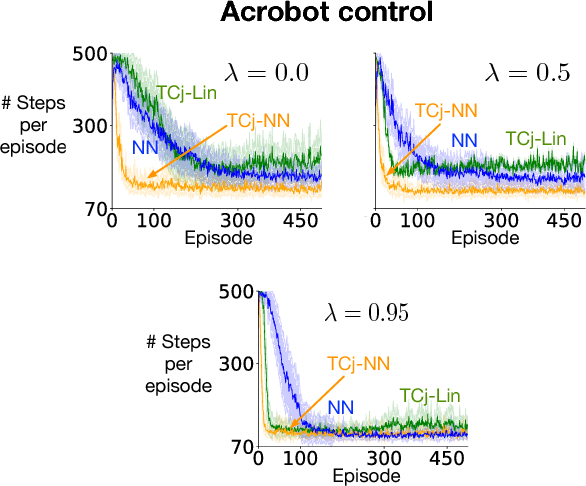
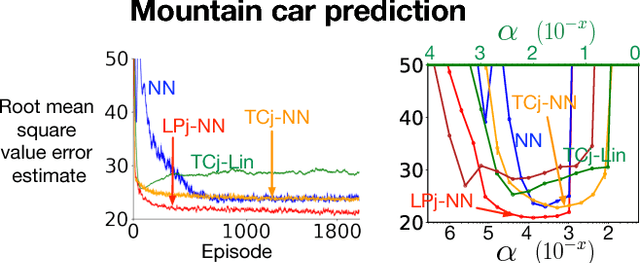
We apply neural nets with ReLU gates in online reinforcement learning. Our goal is to train these networks in an incremental manner, without the computationally expensive experience replay. By studying how individual neural nodes behave in online training, we recognize that the global nature of ReLU gates can cause undesirable learning interference in each node's learning behavior. We propose reducing such interferences with two efficient input transformation methods that are geometric in nature and match well the geometric property of ReLU gates. The first one is tile coding, a classic binary encoding scheme originally designed for local generalization based on the topological structure of the input space. The second one (EmECS) is a new method we introduce; it is based on geometric properties of convex sets and topological embedding of the input space into the boundary of a convex set. We discuss the behavior of the network when it operates on the transformed inputs. We also compare it experimentally with some neural nets that do not use the same input transformations, and with the classic algorithm of tile coding plus a linear function approximator, and on several online reinforcement learning tasks, we show that the neural net with tile coding or EmECS can achieve not only faster learning but also more accurate approximations. Our results strongly suggest that geometric input transformation of this type can be effective for interference reduction and takes us a step closer to fully incremental reinforcement learning with neural nets.
A First Empirical Study of Emphatic Temporal Difference Learning
May 12, 2017

In this paper we present the first empirical study of the emphatic temporal-difference learning algorithm (ETD), comparing it with conventional temporal-difference learning, in particular, with linear TD(0), on on-policy and off-policy variations of the Mountain Car problem. The initial motivation for developing ETD was that it has good convergence properties under off-policy training (Sutton, Mahmood and White 2016), but it is also a new algorithm for the on-policy case. In both our on-policy and off-policy experiments, we found that each method converged to a characteristic asymptotic level of error, with ETD better than TD(0). TD(0) achieved a still lower error level temporarily before falling back to its higher asymptote, whereas ETD never showed this kind of "bounce". In the off-policy case (in which TD(0) is not guaranteed to converge), ETD was significantly slower.