 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Uncertainty Calibration
Dec 15, 2025We make two contributions to the problem of estimating the $L_1$ calibration error of a binary classifier from a finite dataset. First, we provide an upper bound for any classifier where the calibration function has bounded variation. Second, we provide a method of modifying any classifier so that its calibration error can be upper bounded efficiently without significantly impacting classifier performance and without any restrictive assumptions. All our results are non-asymptotic and distribution-free. We conclude by providing advice on how to measure calibration error in practice. Our methods yield practical procedures that can be run on real-world datasets with modest overhead.
Hallucination Detection on a Budget: Efficient Bayesian Estimation of Semantic Entropy
Apr 04, 2025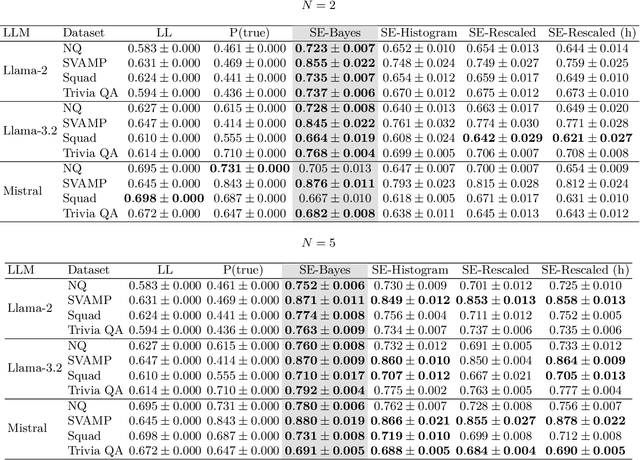
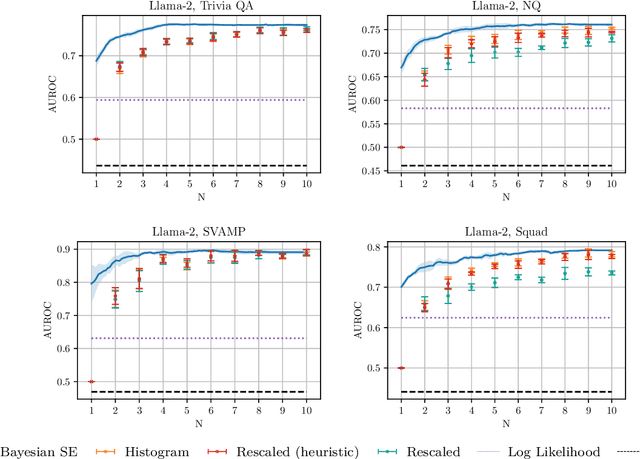
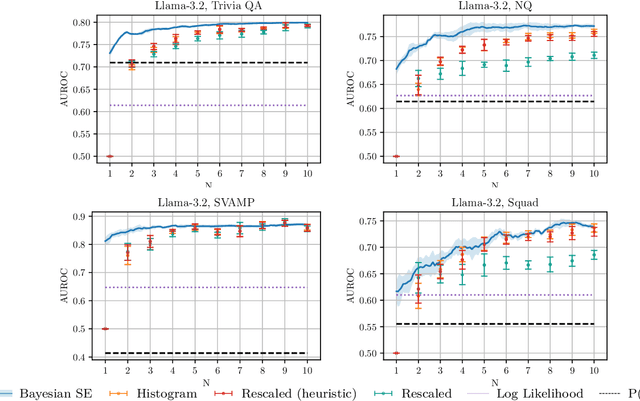
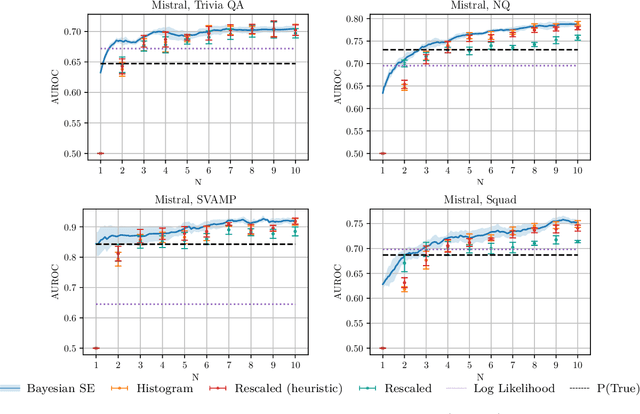
Detecting whether an LLM hallucinates is an important research challenge. One promising way of doing so is to estimate the semantic entropy (Farquhar et al., 2024) of the distribution of generated sequences. We propose a new algorithm for doing that, with two main advantages. First, due to us taking the Bayesian approach, we achieve a much better quality of semantic entropy estimates for a given budget of samples from the LLM. Second, we are able to tune the number of samples adaptively so that `harder' contexts receive more samples. We demonstrate empirically that our approach systematically beats the baselines, requiring only 59% of samples used by Farquhar et al. (2024) to achieve the same quality of hallucination detection as measured by AUROC. Moreover, quite counterintuitively, our estimator is useful even with just one sample from the LLM.
Learning in complex action spaces without policy gradients
Oct 08, 2024
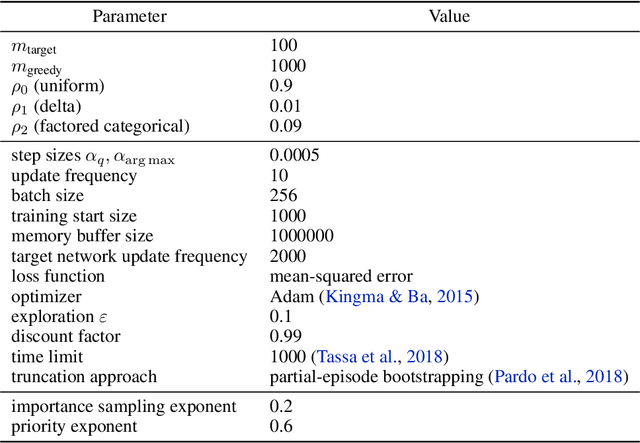
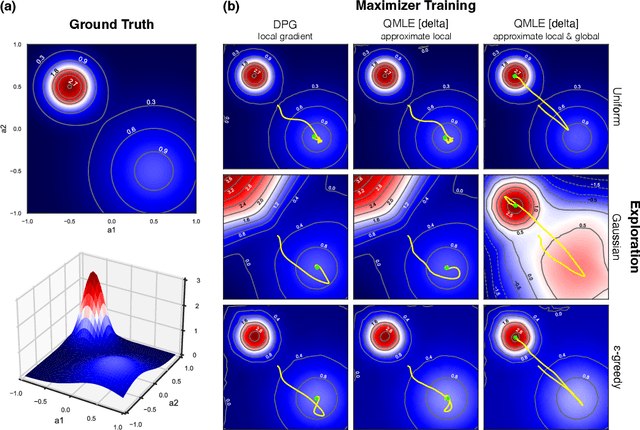
Conventional wisdom suggests that policy gradient methods are better suited to complex action spaces than action-value methods. However, foundational studies have shown equivalences between these paradigms in small and finite action spaces (O'Donoghue et al., 2017; Schulman et al., 2017a). This raises the question of why their computational applicability and performance diverge as the complexity of the action space increases. We hypothesize that the apparent superiority of policy gradients in such settings stems not from intrinsic qualities of the paradigm, but from universal principles that can also be applied to action-value methods to serve similar functionality. We identify three such principles and provide a framework for incorporating them into action-value methods. To support our hypothesis, we instantiate this framework in what we term QMLE, for Q-learning with maximum likelihood estimation. Our results show that QMLE can be applied to complex action spaces with a controllable computational cost that is comparable to that of policy gradient methods, all without using policy gradients. Furthermore, QMLE demonstrates strong performance on the DeepMind Control Suite, even when compared to the state-of-the-art methods such as DMPO and D4PG.
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Apr 30, 2024
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's "softness" adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
On the Importance of Uncertainty in Decision-Making with Large Language Models
Apr 03, 2024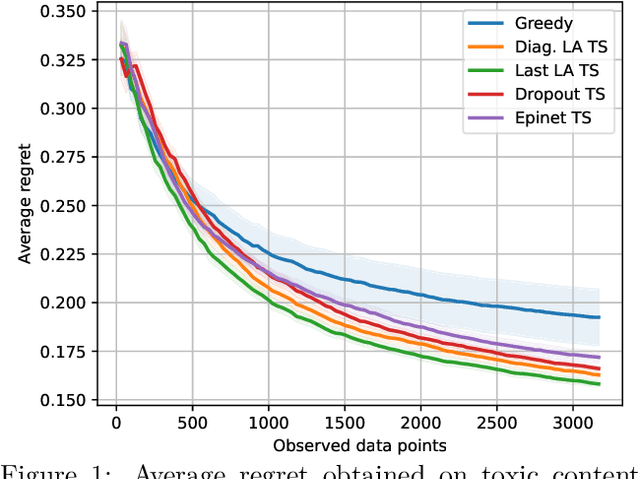
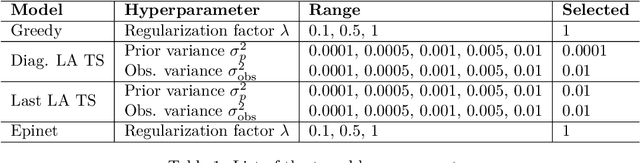
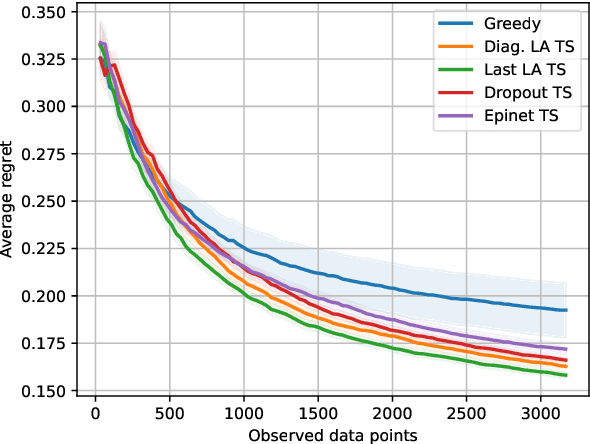
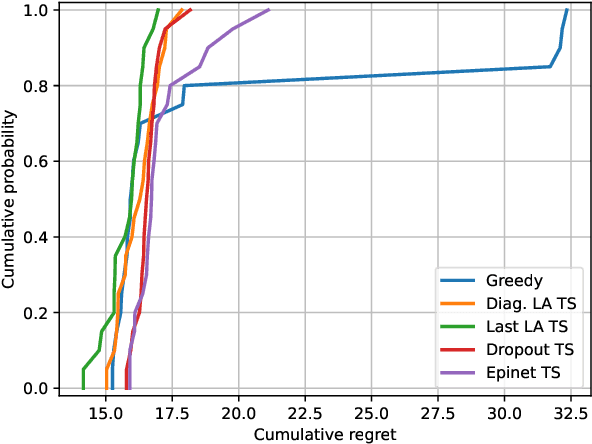
We investigate the role of uncertainty in decision-making problems with natural language as input. For such tasks, using Large Language Models as agents has become the norm. However, none of the recent approaches employ any additional phase for estimating the uncertainty the agent has about the world during the decision-making task. We focus on a fundamental decision-making framework with natural language as input, which is the one of contextual bandits, where the context information consists of text. As a representative of the approaches with no uncertainty estimation, we consider an LLM bandit with a greedy policy, which picks the action corresponding to the largest predicted reward. We compare this baseline to LLM bandits that make active use of uncertainty estimation by integrating the uncertainty in a Thompson Sampling policy. We employ different techniques for uncertainty estimation, such as Laplace Approximation, Dropout, and Epinets. We empirically show on real-world data that the greedy policy performs worse than the Thompson Sampling policies. These findings suggest that, while overlooked in the LLM literature, uncertainty plays a fundamental role in bandit tasks with LLMs.
In-context Exploration-Exploitation for Reinforcement Learning
Mar 11, 2024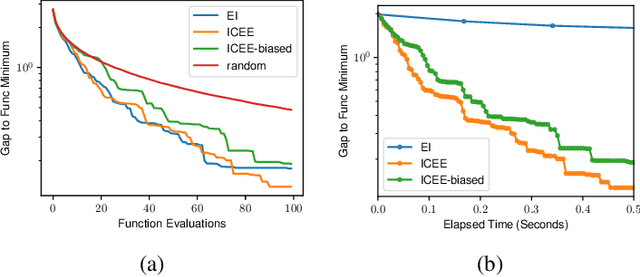
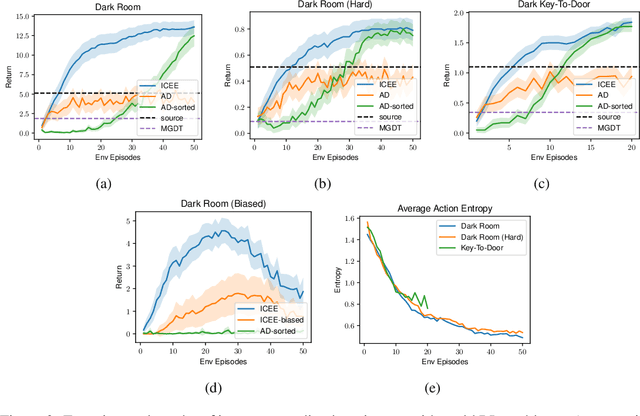
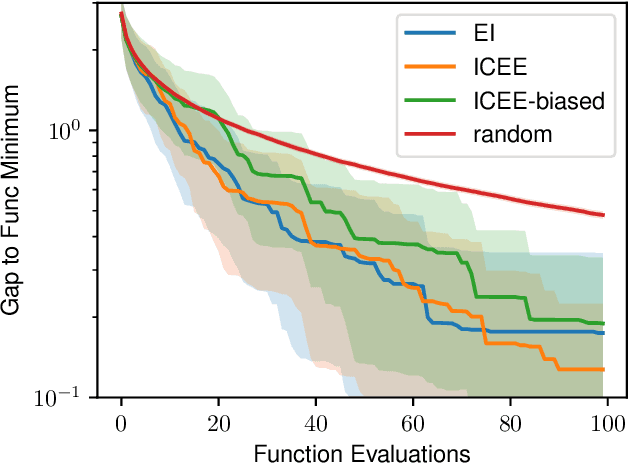
In-context learning is a promising approach for online policy learning of offline reinforcement learning (RL) methods, which can be achieved at inference time without gradient optimization. However, this method is hindered by significant computational costs resulting from the gathering of large training trajectory sets and the need to train large Transformer models. We address this challenge by introducing an In-context Exploration-Exploitation (ICEE) algorithm, designed to optimize the efficiency of in-context policy learning. Unlike existing models, ICEE performs an exploration-exploitation trade-off at inference time within a Transformer model, without the need for explicit Bayesian inference. Consequently, ICEE can solve Bayesian optimization problems as efficiently as Gaussian process biased methods do, but in significantly less time. Through experiments in grid world environments, we demonstrate that ICEE can learn to solve new RL tasks using only tens of episodes, marking a substantial improvement over the hundreds of episodes needed by the previous in-context learning method.
Auxiliary task discovery through generate-and-test
Oct 25, 2022

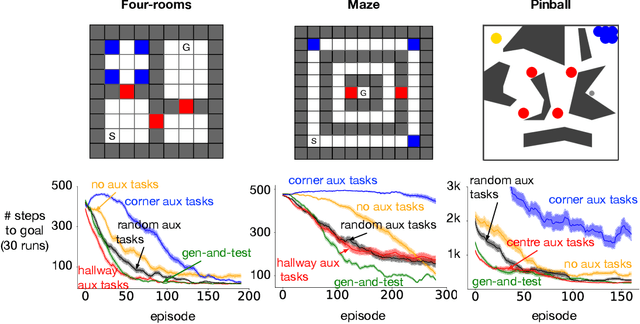
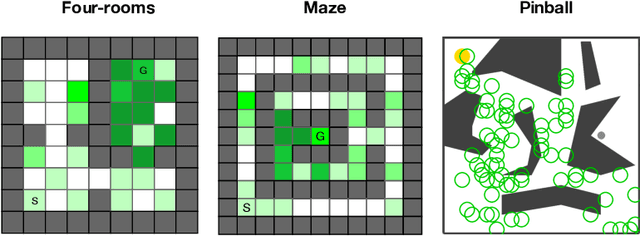
In this paper, we explore an approach to auxiliary task discovery in reinforcement learning based on ideas from representation learning. Auxiliary tasks tend to improve data efficiency by forcing the agent to learn auxiliary prediction and control objectives in addition to the main task of maximizing reward, and thus producing better representations. Typically these tasks are designed by people. Meta-learning offers a promising avenue for automatic task discovery; however, these methods are computationally expensive and challenging to tune in practice. In this paper, we explore a complementary approach to the auxiliary task discovery: continually generating new auxiliary tasks and preserving only those with high utility. We also introduce a new measure of auxiliary tasks usefulness based on how useful the features induced by them are for the main task. Our discovery algorithm significantly outperforms random tasks, hand-designed tasks, and learning without auxiliary tasks across a suite of environments.
Importance Sampling Placement in Off-Policy Temporal-Difference Methods
Mar 18, 2022
A central challenge to applying many off-policy reinforcement learning algorithms to real world problems is the variance introduced by importance sampling. In off-policy learning, the agent learns about a different policy than the one being executed. To account for the difference importance sampling ratios are often used, but can increase variance in the algorithms and reduce the rate of learning. Several variations of importance sampling have been proposed to reduce variance, with per-decision importance sampling being the most popular. However, the update rules for most off-policy algorithms in the literature depart from per-decision importance sampling in a subtle way; they correct the entire TD error instead of just the TD target. In this work, we show how this slight change can be interpreted as a control variate for the TD target, reducing variance and improving performance. Experiments over a wide range of algorithms show this subtle modification results in improved performance.
An Empirical Comparison of Off-policy Prediction Learning Algorithms in the Four Rooms Environment
Sep 10, 2021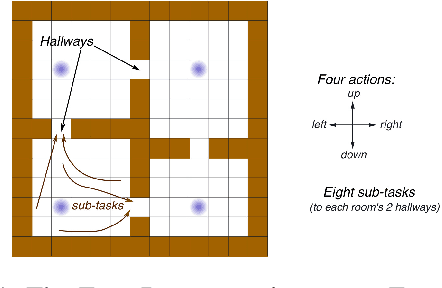
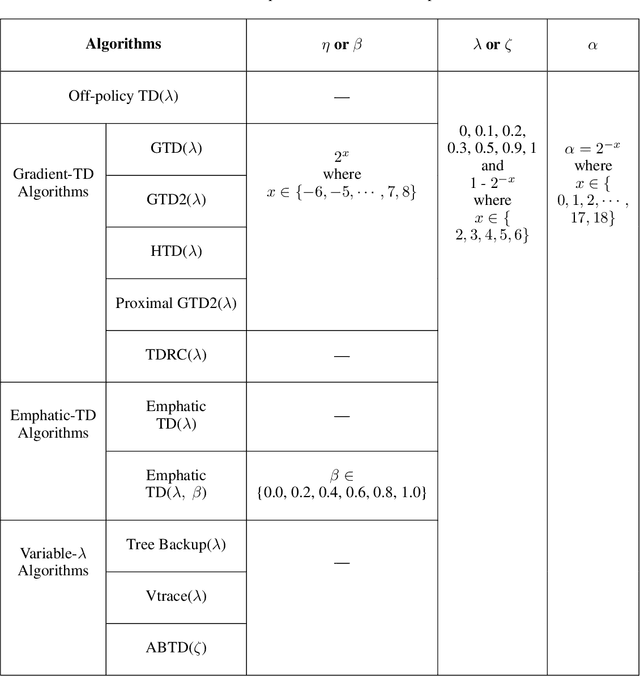
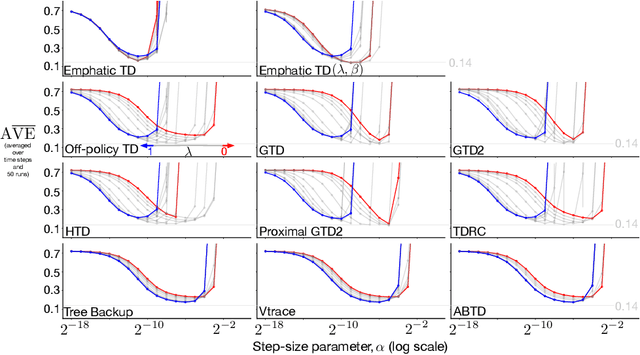
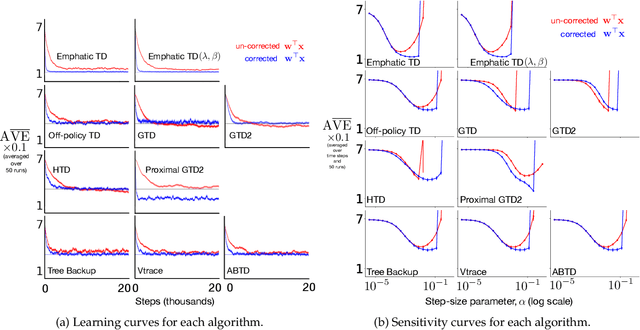
Many off-policy prediction learning algorithms have been proposed in the past decade, but it remains unclear which algorithms learn faster than others. We empirically compare 11 off-policy prediction learning algorithms with linear function approximation on two small tasks: the Rooms task, and the High Variance Rooms task. The tasks are designed such that learning fast in them is challenging. In the Rooms task, the product of importance sampling ratios can be as large as $2^{14}$ and can sometimes be two. To control the high variance caused by the product of the importance sampling ratios, step size should be set small, which in turn slows down learning. The High Variance Rooms task is more extreme in that the product of the ratios can become as large as $2^{14}\times 25$. This paper builds upon the empirical study of off-policy prediction learning algorithms by Ghiassian and Sutton (2021). We consider the same set of algorithms as theirs and employ the same experimental methodology. The algorithms considered are: Off-policy TD($\lambda$), five Gradient-TD algorithms, two Emphatic-TD algorithms, Tree Backup($\lambda$), Vtrace($\lambda$), and ABTD($\zeta$). We found that the algorithms' performance is highly affected by the variance induced by the importance sampling ratios. The data shows that Tree Backup($\lambda$), Vtrace($\lambda$), and ABTD($\zeta$) are not affected by the high variance as much as other algorithms but they restrict the effective bootstrapping parameter in a way that is too limiting for tasks where high variance is not present. We observed that Emphatic TD($\lambda$) tends to have lower asymptotic error than other algorithms, but might learn more slowly in some cases. We suggest algorithms for practitioners based on their problem of interest, and suggest approaches that can be applied to specific algorithms that might result in substantially improved algorithms.
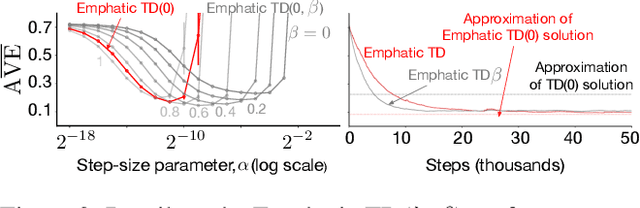
An Empirical Comparison of Off-policy Prediction Learning Algorithms on the Collision Task
Jun 11, 2021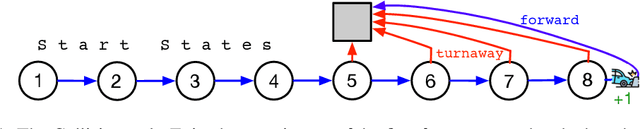

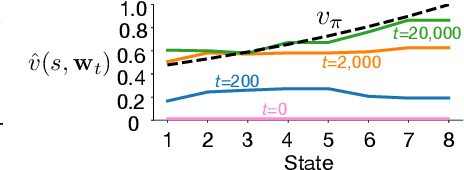
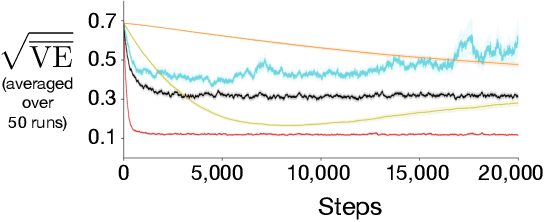
Off-policy prediction -- learning the value function for one policy from data generated while following another policy -- is one of the most challenging subproblems in reinforcement learning. This paper presents empirical results with eleven prominent off-policy learning algorithms that use linear function approximation: five Gradient-TD methods, two Emphatic-TD methods, Off-policy TD($\lambda$), Vtrace, and versions of Tree Backup and ABQ modified to apply to a prediction setting. Our experiments used the Collision task, a small idealized off-policy problem analogous to that of an autonomous car trying to predict whether it will collide with an obstacle. We assessed the performance of the algorithms according to their learning rate, asymptotic error level, and sensitivity to step-size and bootstrapping parameters. By these measures, the eleven algorithms can be partially ordered on the Collision task. In the top tier, the two Emphatic-TD algorithms learned the fastest, reached the lowest errors, and were robust to parameter settings. In the middle tier, the five Gradient-TD algorithms and Off-policy TD($\lambda$) were more sensitive to the bootstrapping parameter. The bottom tier comprised Vtrace, Tree Backup, and ABQ; these algorithms were no faster and had higher asymptotic error than the others. Our results are definitive for this task, though of course experiments with more tasks are needed before an overall assessment of the algorithms' merits can be made.