 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Uncertainty Calibration
Dec 15, 2025We make two contributions to the problem of estimating the $L_1$ calibration error of a binary classifier from a finite dataset. First, we provide an upper bound for any classifier where the calibration function has bounded variation. Second, we provide a method of modifying any classifier so that its calibration error can be upper bounded efficiently without significantly impacting classifier performance and without any restrictive assumptions. All our results are non-asymptotic and distribution-free. We conclude by providing advice on how to measure calibration error in practice. Our methods yield practical procedures that can be run on real-world datasets with modest overhead.
Linear Gradient Prediction with Control Variates
Nov 07, 2025We propose a new way of training neural networks, with the goal of reducing training cost. Our method uses approximate predicted gradients instead of the full gradients that require an expensive backward pass. We derive a control-variate-based technique that ensures our updates are unbiased estimates of the true gradient. Moreover, we propose a novel way to derive a predictor for the gradient inspired by the theory of the Neural Tangent Kernel. We empirically show the efficacy of the technique on a vision transformer classification task.
Hallucination Detection on a Budget: Efficient Bayesian Estimation of Semantic Entropy
Apr 04, 2025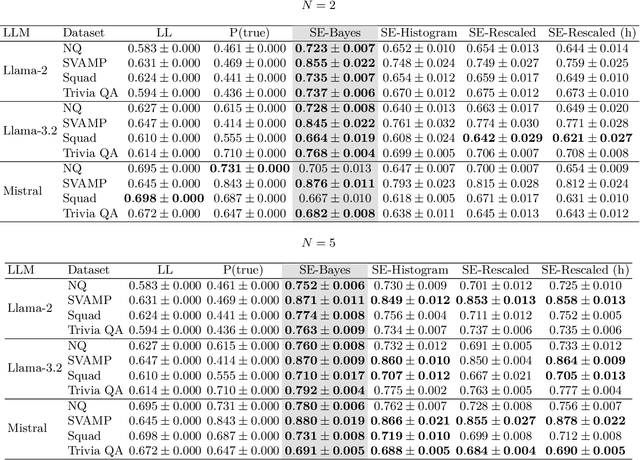
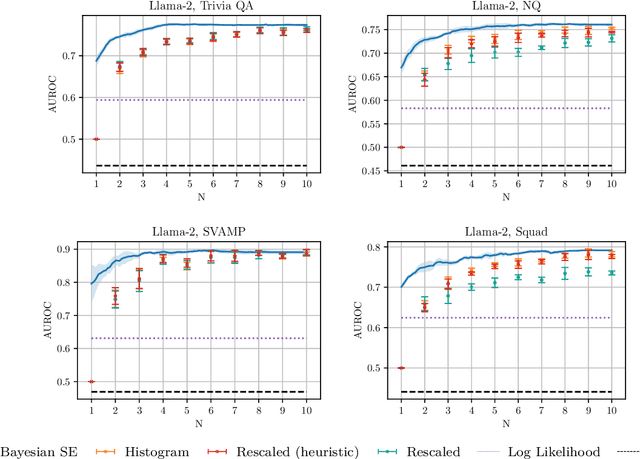
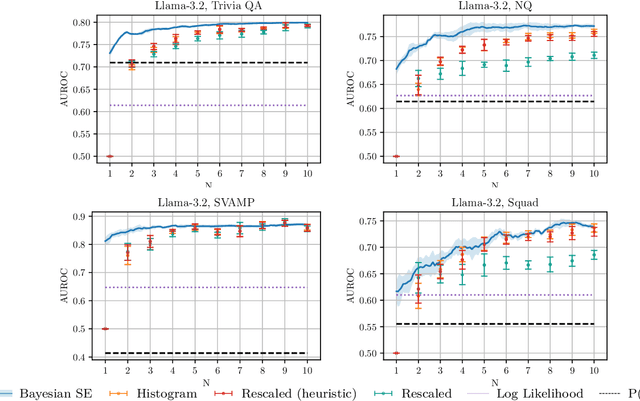
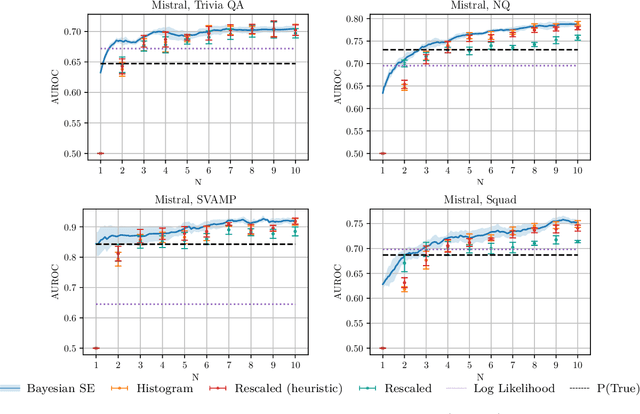
Detecting whether an LLM hallucinates is an important research challenge. One promising way of doing so is to estimate the semantic entropy (Farquhar et al., 2024) of the distribution of generated sequences. We propose a new algorithm for doing that, with two main advantages. First, due to us taking the Bayesian approach, we achieve a much better quality of semantic entropy estimates for a given budget of samples from the LLM. Second, we are able to tune the number of samples adaptively so that `harder' contexts receive more samples. We demonstrate empirically that our approach systematically beats the baselines, requiring only 59% of samples used by Farquhar et al. (2024) to achieve the same quality of hallucination detection as measured by AUROC. Moreover, quite counterintuitively, our estimator is useful even with just one sample from the LLM.
AutoOPE: Automated Off-Policy Estimator Selection
Jun 26, 2024



The Off-Policy Evaluation (OPE) problem consists of evaluating the performance of counterfactual policies with data collected by another one. This problem is of utmost importance for various application domains, e.g., recommendation systems, medical treatments, and many others. To solve the OPE problem, we resort to estimators, which aim to estimate in the most accurate way possible the performance that the counterfactual policies would have had if they were deployed in place of the logging policy. In the literature, several estimators have been developed, all with different characteristics and theoretical guarantees. Therefore, there is no dominant estimator, and each estimator may be the best one for different OPE problems, depending on the characteristics of the dataset at hand. While the selection of the estimator is a crucial choice for an accurate OPE, this problem has been widely overlooked in the literature. We propose an automated data-driven OPE estimator selection method based on machine learning. In particular, the core idea we propose in this paper is to create several synthetic OPE tasks and use a machine learning model trained to predict the best estimator for those synthetic tasks. We empirically show how our method is able to generalize to unseen tasks and make a better estimator selection compared to a baseline method on several real-world datasets, with a computational cost significantly lower than the one of the baseline.
On the Importance of Uncertainty in Decision-Making with Large Language Models
Apr 03, 2024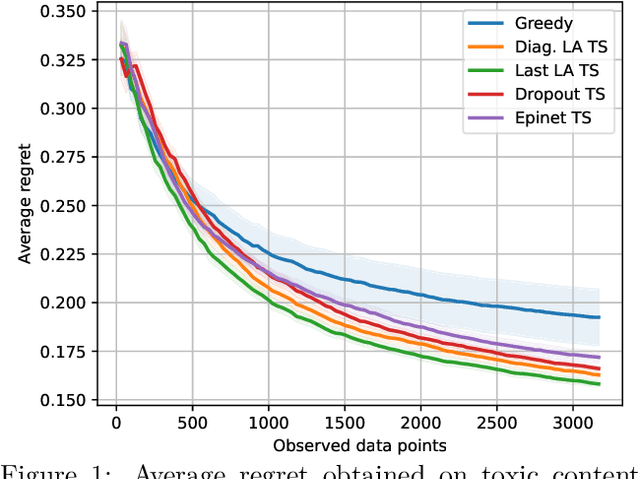
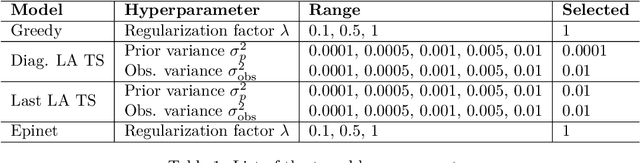
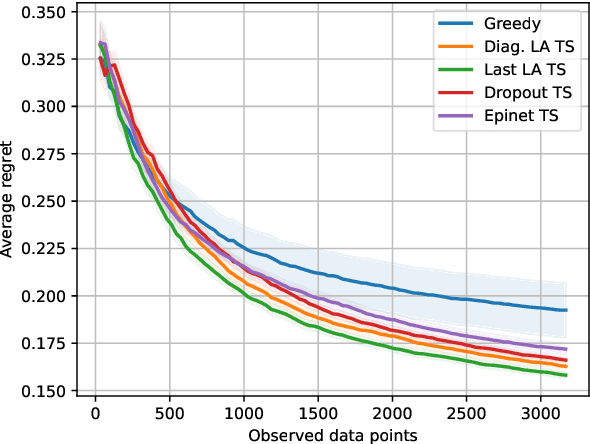
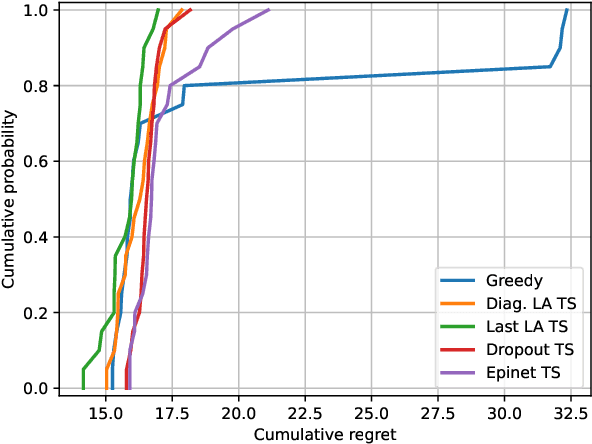
We investigate the role of uncertainty in decision-making problems with natural language as input. For such tasks, using Large Language Models as agents has become the norm. However, none of the recent approaches employ any additional phase for estimating the uncertainty the agent has about the world during the decision-making task. We focus on a fundamental decision-making framework with natural language as input, which is the one of contextual bandits, where the context information consists of text. As a representative of the approaches with no uncertainty estimation, we consider an LLM bandit with a greedy policy, which picks the action corresponding to the largest predicted reward. We compare this baseline to LLM bandits that make active use of uncertainty estimation by integrating the uncertainty in a Thompson Sampling policy. We employ different techniques for uncertainty estimation, such as Laplace Approximation, Dropout, and Epinets. We empirically show on real-world data that the greedy policy performs worse than the Thompson Sampling policies. These findings suggest that, while overlooked in the LLM literature, uncertainty plays a fundamental role in bandit tasks with LLMs.
Measuring the User Satisfaction in a Recommendation Interface with Multiple Carousels
May 14, 2021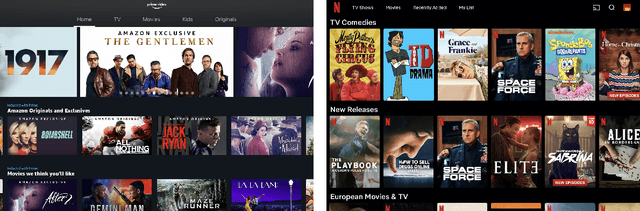



It is common for video-on-demand and music streaming services to adopt a user interface composed of several recommendation lists, i.e. widgets or swipeable carousels, each generated according to a specific criterion or algorithm (e.g. most recent, top popular, recommended for you, editors' choice, etc.). Selecting the appropriate combination of carousel has significant impact on user satisfaction. A crucial aspect of this user interface is that to measure the relevance a new carousel for the user it is not sufficient to account solely for its individual quality. Instead, it should be considered that other carousels will already be present in the interface. This is not considered by traditional evaluation protocols for recommenders systems, in which each carousel is evaluated in isolation, regardless of (i) which other carousels are displayed to the user and (ii) the relative position of the carousel with respect to other carousels. Hence, we propose a two-dimensional evaluation protocol for a carousel setting that will measure the quality of a recommendation carousel based on how much it improves upon the quality of an already available set of carousels. Our evaluation protocol takes into account also the position bias, i.e. users do not explore the carousels sequentially, but rather concentrate on the top-left corner of the screen. We report experiments on the movie domain and notice that under a carousel setting the definition of which criteria has to be preferred to generate a list of recommended items changes with respect to what is commonly understood.
A Methodology for the Offline Evaluation of Recommender Systems in a User Interface with Multiple Carousels
May 13, 2021


Many video-on-demand and music streaming services provide the user with a page consisting of several recommendation lists, i.e. widgets or swipeable carousels, each built with a specific criterion (e.g. most recent, TV series, etc.). Finding efficient strategies to select which carousels to display is an active research topic of great industrial interest. In this setting, the overall quality of the recommendations of a new algorithm cannot be assessed by measuring solely its individual recommendation quality. Rather, it should be evaluated in a context where other recommendation lists are already available, to account for how they complement each other. This is not considered by traditional offline evaluation protocols. Hence, we propose an offline evaluation protocol for a carousel setting in which the recommendation quality of a model is measured by how much it improves upon that of an already available set of carousels. We report experiments on publicly available datasets on the movie domain and notice that under a carousel setting the ranking of the algorithms change. In particular, when a SLIM carousel is available, matrix factorization models tend to be preferred, while item-based models are penalized. We also propose to extend ranking metrics to the two-dimensional carousel layout in order to account for a known position bias, i.e. users will not explore the lists sequentially, but rather concentrate on the top-left corner of the screen.