 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Sequence Classification with Temporal Consistency
May 22, 2025We address the problem of incremental sequence classification, where predictions are updated as new elements in the sequence are revealed. Drawing on temporal-difference learning from reinforcement learning, we identify a temporal-consistency condition that successive predictions should satisfy. We leverage this condition to develop a novel loss function for training incremental sequence classifiers. Through a concrete example, we demonstrate that optimizing this loss can offer substantial gains in data efficiency. We apply our method to text classification tasks and show that it improves predictive accuracy over competing approaches on several benchmark datasets. We further evaluate our approach on the task of verifying large language model generations for correctness in grade-school math problems. Our results show that models trained with our method are better able to distinguish promising generations from unpromising ones after observing only a few tokens.
Impatient Bandits: Optimizing for the Long-Term Without Delay
Jan 14, 2025


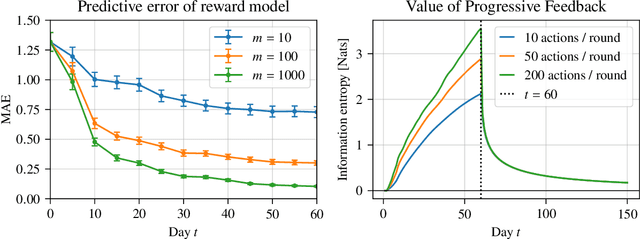
Increasingly, recommender systems are tasked with improving users' long-term satisfaction. In this context, we study a content exploration task, which we formalize as a bandit problem with delayed rewards. There is an apparent trade-off in choosing the learning signal: waiting for the full reward to become available might take several weeks, slowing the rate of learning, whereas using short-term proxy rewards reflects the actual long-term goal only imperfectly. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Rewards as well as shorter-term surrogate outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that quickly learns to identify content aligned with long-term success using this new predictive model. We prove a regret bound for our algorithm that depends on the \textit{Value of Progressive Feedback}, an information theoretic metric that captures the quality of short-term leading indicators that are observed prior to the long-term reward. We apply our approach to a podcast recommendation problem, where we seek to recommend shows that users engage with repeatedly over two months. We empirically validate that our approach significantly outperforms methods that optimize for short-term proxies or rely solely on delayed rewards, as demonstrated by an A/B test in a recommendation system that serves hundreds of millions of users.
On the Importance of Uncertainty in Decision-Making with Large Language Models
Apr 03, 2024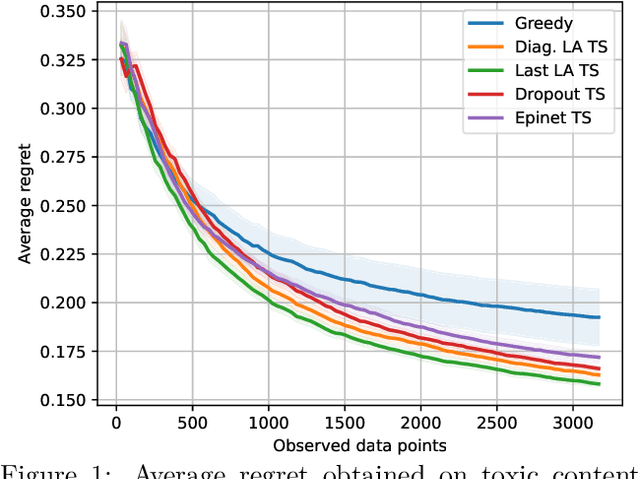
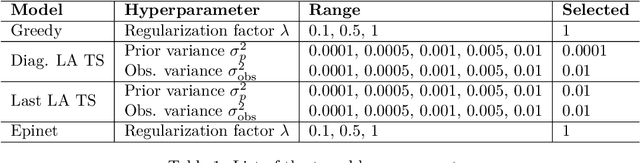
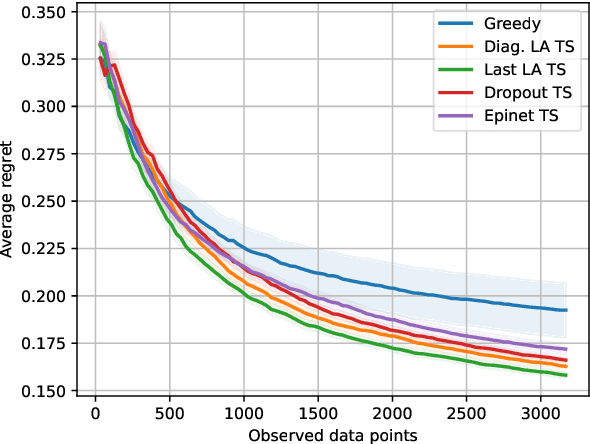
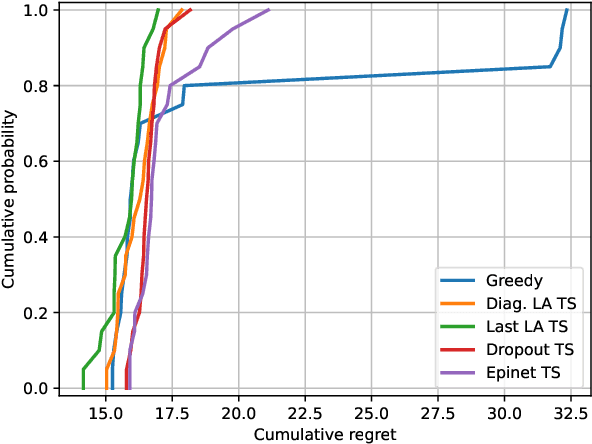
We investigate the role of uncertainty in decision-making problems with natural language as input. For such tasks, using Large Language Models as agents has become the norm. However, none of the recent approaches employ any additional phase for estimating the uncertainty the agent has about the world during the decision-making task. We focus on a fundamental decision-making framework with natural language as input, which is the one of contextual bandits, where the context information consists of text. As a representative of the approaches with no uncertainty estimation, we consider an LLM bandit with a greedy policy, which picks the action corresponding to the largest predicted reward. We compare this baseline to LLM bandits that make active use of uncertainty estimation by integrating the uncertainty in a Thompson Sampling policy. We employ different techniques for uncertainty estimation, such as Laplace Approximation, Dropout, and Epinets. We empirically show on real-world data that the greedy policy performs worse than the Thompson Sampling policies. These findings suggest that, while overlooked in the LLM literature, uncertainty plays a fundamental role in bandit tasks with LLMs.
Impatient Bandits: Optimizing Recommendations for the Long-Term Without Delay
Jul 20, 2023
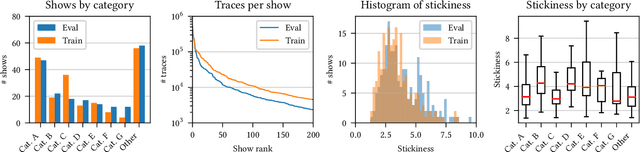


Recommender systems are a ubiquitous feature of online platforms. Increasingly, they are explicitly tasked with increasing users' long-term satisfaction. In this context, we study a content exploration task, which we formalize as a multi-armed bandit problem with delayed rewards. We observe that there is an apparent trade-off in choosing the learning signal: Waiting for the full reward to become available might take several weeks, hurting the rate at which learning happens, whereas measuring short-term proxy rewards reflects the actual long-term goal only imperfectly. We address this challenge in two steps. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Full observations as well as partial (short or medium-term) outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that takes advantage of this new predictive model. The algorithm quickly learns to identify content aligned with long-term success by carefully balancing exploration and exploitation. We apply our approach to a podcast recommendation problem, where we seek to identify shows that users engage with repeatedly over two months. We empirically validate that our approach results in substantially better performance compared to approaches that either optimize for short-term proxies, or wait for the long-term outcome to be fully realized.
Fast Interactive Search with a Scale-Free Comparison Oracle
Jun 02, 2023A comparison-based search algorithm lets a user find a target item $t$ in a database by answering queries of the form, ``Which of items $i$ and $j$ is closer to $t$?'' Instead of formulating an explicit query (such as one or several keywords), the user navigates towards the target via a sequence of such (typically noisy) queries. We propose a scale-free probabilistic oracle model called $\gamma$-CKL for such similarity triplets $(i,j;t)$, which generalizes the CKL triplet model proposed in the literature. The generalization affords independent control over the discriminating power of the oracle and the dimension of the feature space containing the items. We develop a search algorithm with provably exponential rate of convergence under the $\gamma$-CKL oracle, thanks to a backtracking strategy that deals with the unavoidable errors in updating the belief region around the target. We evaluate the performance of the algorithm both over the posited oracle and over several real-world triplet datasets. We also report on a comprehensive user study, where human subjects navigate a database of face portraits.
Optimizing Audio Recommendations for the Long-Term: A Reinforcement Learning Perspective
Feb 28, 2023

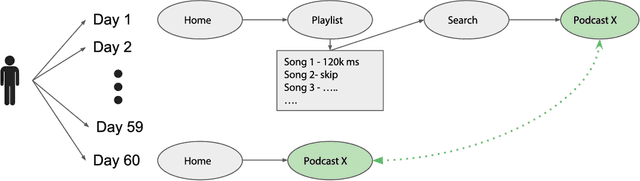

We study the problem of optimizing a recommender system for outcomes that occur over several weeks or months. We begin by drawing on reinforcement learning to formulate a comprehensive model of users' recurring relationships with a recommender system. Measurement, attribution, and coordination challenges complicate algorithm design. We describe careful modeling -- including a new representation of user state and key conditional independence assumptions -- which overcomes these challenges and leads to simple, testable recommender system prototypes. We apply our approach to a podcast recommender system that makes personalized recommendations to hundreds of millions of listeners. A/B tests demonstrate that purposefully optimizing for long-term outcomes leads to large performance gains over conventional approaches that optimize for short-term proxies.
Estimating long-term causal effects from short-term experiments and long-term observational data with unobserved confounding
Feb 21, 2023



Understanding and quantifying cause and effect is an important problem in many domains. The generally-agreed solution to this problem is to perform a randomised controlled trial. However, even when randomised controlled trials can be performed, they usually have relatively short duration's due to cost considerations. This makes learning long-term causal effects a very challenging task in practice, since the long-term outcome is only observed after a long delay. In this paper, we study the identification and estimation of long-term treatment effects when both experimental and observational data are available. Previous work provided an estimation strategy to determine long-term causal effects from such data regimes. However, this strategy only works if one assumes there are no unobserved confounders in the observational data. In this paper, we specifically address the challenging case where unmeasured confounders are present in the observational data. Our long-term causal effect estimator is obtained by combining regression residuals with short-term experimental outcomes in a specific manner to create an instrumental variable, which is then used to quantify the long-term causal effect through instrumental variable regression. We prove this estimator is unbiased, and analytically study its variance. In the context of the front-door causal structure, this provides a new causal estimator, which may be of independent interest. Finally, we empirically test our approach on synthetic-data, as well as real-data from the International Stroke Trial.
A Strong Baseline for Batch Imitation Learning
Feb 06, 2023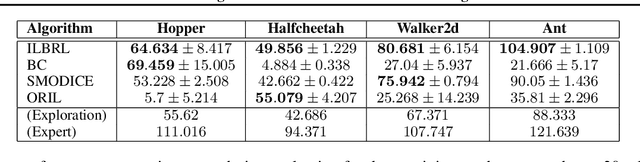
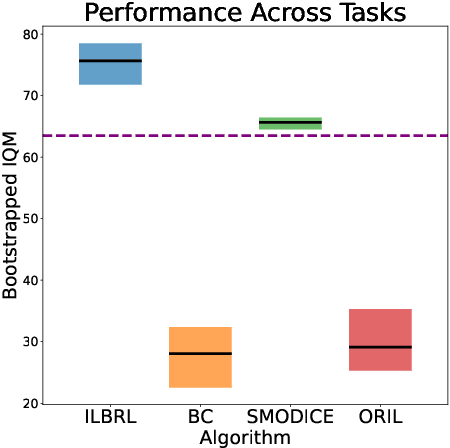
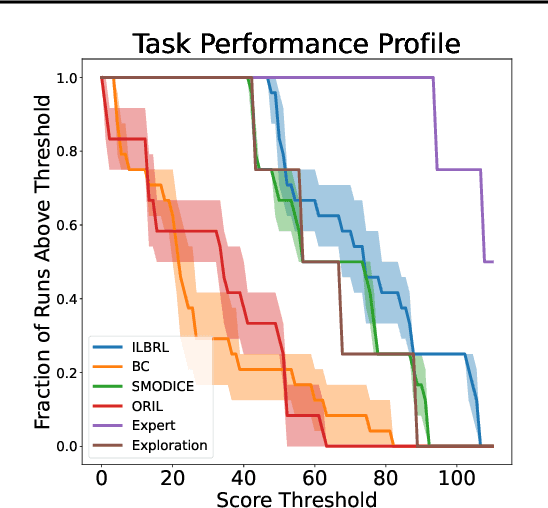

Imitation of expert behaviour is a highly desirable and safe approach to the problem of sequential decision making. We provide an easy-to-implement, novel algorithm for imitation learning under a strict data paradigm, in which the agent must learn solely from data collected a priori. This paradigm allows our algorithm to be used for environments in which safety or cost are of critical concern. Our algorithm requires no additional hyper-parameter tuning beyond any standard batch reinforcement learning (RL) algorithm, making it an ideal baseline for such data-strict regimes. Furthermore, we provide formal sample complexity guarantees for the algorithm in finite Markov Decision Problems. In doing so, we formally demonstrate an unproven claim from Kearns & Singh (1998). On the empirical side, our contribution is twofold. First, we develop a practical, robust and principled evaluation protocol for offline RL methods, making use of only the dataset provided for model selection. This stands in contrast to the vast majority of previous works in offline RL, which tune hyperparameters on the evaluation environment, limiting the practical applicability when deployed in new, cost-critical environments. As such, we establish precedent for the development and fair evaluation of offline RL algorithms. Second, we evaluate our own algorithm on challenging continuous control benchmarks, demonstrating its practical applicability and competitiveness with state-of-the-art performance, despite being a simpler algorithm.
A User Study of Perceived Carbon Footprint
Dec 04, 2019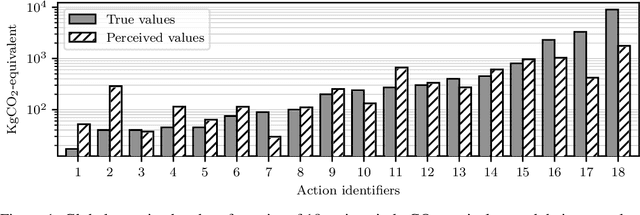
We propose a statistical model to understand people's perception of their carbon footprint. Driven by the observation that few people think of CO2 impact in absolute terms, we design a system to probe people's perception from simple pairwise comparisons of the relative carbon footprint of their actions. The formulation of the model enables us to take an active-learning approach to selecting the pairs of actions that are maximally informative about the model parameters. We define a set of 18 actions and collect a dataset of 2183 comparisons from 176 users on a university campus. The early results reveal promising directions to improve climate communication and enhance climate mitigation.
Learning to Search Efficiently Using Comparisons
May 13, 2019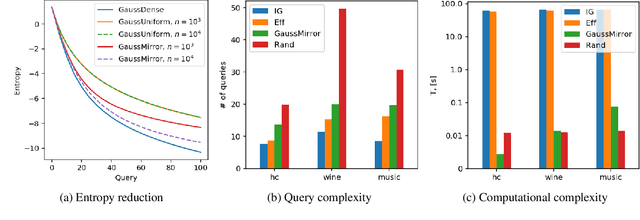
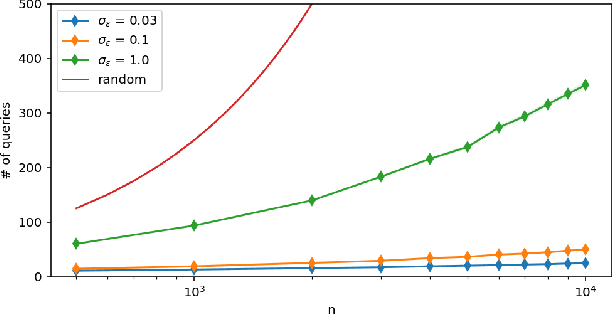
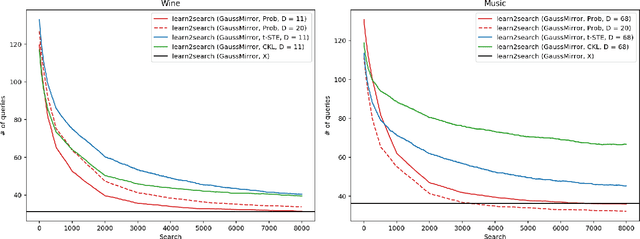
We consider the problem of searching in a set of items by using pairwise comparisons. We aim to locate a target item $t$ by asking an oracle questions of the form "Which item from the pair $(i,j)$ is more similar to t?". We assume a blind setting, where no item features are available to guide the search process; only the oracle sees the features in order to generate an answer. Previous approaches for this problem either assume noiseless answers, or they scale poorly in the number of items, both of which preclude practical applications. In this paper, we present a new scalable learning framework called learn2search that performs efficient comparison-based search on a set of items despite the presence of noise in the answers. Items live in a space of latent features, and we posit a probabilistic model for the oracle comparing two items $i$ and $j$ with respect to a target $t$. Our algorithm maintains its own representation of the space of items, which it learns incrementally based on past searches. We evaluate the performance of learn2search on both synthetic and real-world data, and show that it learns to search more and more efficiently, over time matching the performance of a scheme with access to the item features.