 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying Lobby Influence in the European Parliament
Sep 20, 2023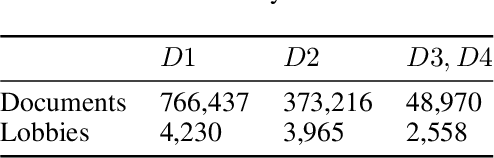


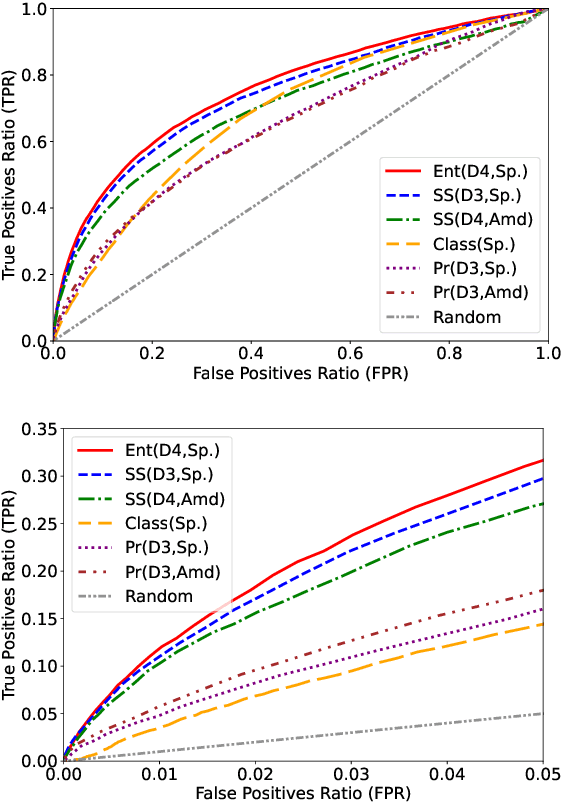
We present a method based on natural language processing (NLP), for studying the influence of interest groups (lobbies) in the law-making process in the European Parliament (EP). We collect and analyze novel datasets of lobbies' position papers and speeches made by members of the EP (MEPs). By comparing these texts on the basis of semantic similarity and entailment, we are able to discover interpretable links between MEPs and lobbies. In the absence of a ground-truth dataset of such links, we perform an indirect validation by comparing the discovered links with a dataset, which we curate, of retweet links between MEPs and lobbies, and with the publicly disclosed meetings of MEPs. Our best method achieves an AUC score of 0.77 and performs significantly better than several baselines. Moreover, an aggregate analysis of the discovered links, between groups of related lobbies and political groups of MEPs, correspond to the expectations from the ideology of the groups (e.g., center-left groups are associated with social causes). We believe that this work, which encompasses the methodology, datasets, and results, is a step towards enhancing the transparency of the intricate decision-making processes within democratic institutions.
A User Study of Perceived Carbon Footprint
Dec 04, 2019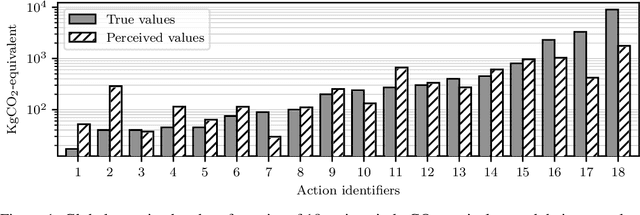
We propose a statistical model to understand people's perception of their carbon footprint. Driven by the observation that few people think of CO2 impact in absolute terms, we design a system to probe people's perception from simple pairwise comparisons of the relative carbon footprint of their actions. The formulation of the model enables us to take an active-learning approach to selecting the pairs of actions that are maximally informative about the model parameters. We define a set of 18 actions and collect a dataset of 2183 comparisons from 176 users on a university campus. The early results reveal promising directions to improve climate communication and enhance climate mitigation.
Linear-Time Inference for Pairwise Comparisons with Gaussian-Process Dynamics
Mar 18, 2019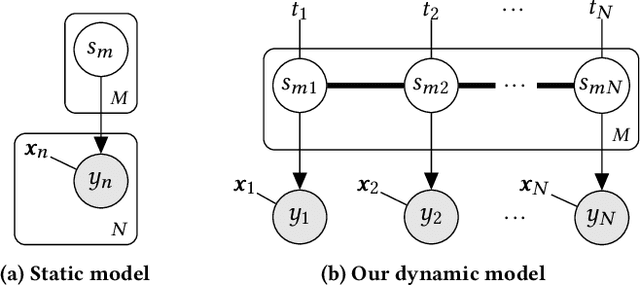
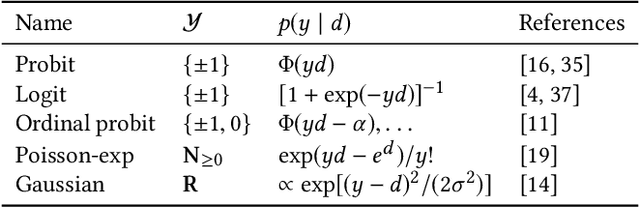

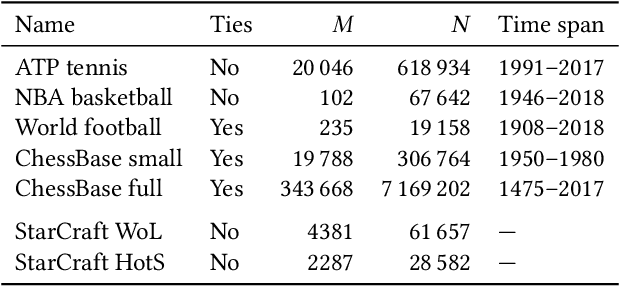
We present a probabilistic model of pairwise-comparison outcomes that can encode variations over time. To this end, we replace the real-valued parameters of a class of generalized linear comparison models by function-valued stochastic processes. In particular, we use Gaussian processes; their kernel function can express time dynamics in a flexible way. We give an algorithm that performs approximate Bayesian inference in linear time. We test our model on several sports datasets, and we find that our approach performs favorably in terms of predictive performance. Additionally, our method can be used to visualize the data effectively.
Can Who-Edits-What Predict Edit Survival?
Jul 05, 2018
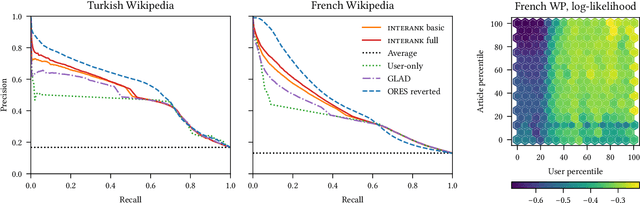


As the number of contributors to online peer-production systems grows, it becomes increasingly important to predict whether the edits that users make will eventually be beneficial to the project. Existing solutions either rely on a user reputation system or consist of a highly specialized predictor that is tailored to a specific peer-production system. In this work, we explore a different point in the solution space that goes beyond user reputation but does not involve any content-based feature of the edits. We view each edit as a game between the editor and the component of the project. We posit that the probability that an edit is accepted is a function of the editor's skill, of the difficulty of editing the component and of a user-component interaction term. Our model is broadly applicable, as it only requires observing data about who makes an edit, what the edit affects and whether the edit survives or not. We apply our model on Wikipedia and the Linux kernel, two examples of large-scale peer-production systems, and we seek to understand whether it can effectively predict edit survival: in both cases, we provide a positive answer. Our approach significantly outperforms those based solely on user reputation and bridges the gap with specialized predictors that use content-based features. It is simple to implement, computationally inexpensive, and in addition it enables us to discover interesting structure in the data.
The Player Kernel: Learning Team Strengths Based on Implicit Player Contributions
Sep 05, 2016

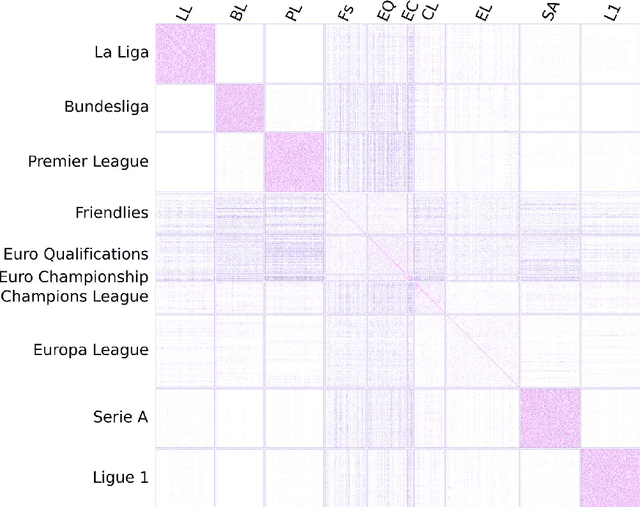
In this work, we draw attention to a connection between skill-based models of game outcomes and Gaussian process classification models. The Gaussian process perspective enables a) a principled way of dealing with uncertainty and b) rich models, specified through kernel functions. Using this connection, we tackle the problem of predicting outcomes of football matches between national teams. We develop a player kernel that relates any two football matches through the players lined up on the field. This makes it possible to share knowledge gained from observing matches between clubs (available in large quantities) and matches between national teams (available only in limited quantities). We evaluate our approach on the Euro 2008, 2012 and 2016 final tournaments.