 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-Order Stackelberg Control in Combinatorial Congestion Games
Feb 26, 2026We study Stackelberg (leader--follower) tuning of network parameters (tolls, capacities, incentives) in combinatorial congestion games, where selfish users choose discrete routes (or other combinatorial strategies) and settle at a congestion equilibrium. The leader minimizes a system-level objective (e.g., total travel time) evaluated at equilibrium, but this objective is typically nonsmooth because the set of used strategies can change abruptly. We propose ZO-Stackelberg, which couples a projection-free Frank--Wolfe equilibrium solver with a zeroth-order outer update, avoiding differentiation through equilibria. We prove convergence to generalized Goldstein stationary points of the true equilibrium objective, with explicit dependence on the equilibrium approximation error, and analyze subsampled oracles: if an exact minimizer is sampled with probability $κ_m$, then the Frank--Wolfe error decays as $\mathcal{O}(1/(κ_m T))$. We also propose stratified sampling as a practical way to avoid a vanishing $κ_m$ when the strategies that matter most for the Wardrop equilibrium concentrate in a few dominant combinatorial classes (e.g., short paths). Experiments on real-world networks demonstrate that our method achieves orders-of-magnitude speedups over a differentiation-based baseline while converging to follower equilibria.
Optimal Graph Clustering without Edge Density Signals
Oct 24, 2025This paper establishes the theoretical limits of graph clustering under the Popularity-Adjusted Block Model (PABM), addressing limitations of existing models. In contrast to the Stochastic Block Model (SBM), which assumes uniform vertex degrees, and to the Degree-Corrected Block Model (DCBM), which applies uniform degree corrections across clusters, PABM introduces separate popularity parameters for intra- and inter-cluster connections. Our main contribution is the characterization of the optimal error rate for clustering under PABM, which provides novel insights on clustering hardness: we demonstrate that unlike SBM and DCBM, cluster recovery remains possible in PABM even when traditional edge-density signals vanish, provided intra- and inter-cluster popularity coefficients differ. This highlights a dimension of degree heterogeneity captured by PABM but overlooked by DCBM: local differences in connectivity patterns can enhance cluster separability independently of global edge densities. Finally, because PABM exhibits a richer structure, its expected adjacency matrix has rank between $k$ and $k^2$, where $k$ is the number of clusters. As a result, spectral embeddings based on the top $k$ eigenvectors may fail to capture important structural information. Our numerical experiments on both synthetic and real datasets confirm that spectral clustering algorithms incorporating $k^2$ eigenvectors outperform traditional spectral approaches.
Learn to Vaccinate: Combining Structure Learning and Effective Vaccination for Epidemic and Outbreak Control
Jun 18, 2025



The Susceptible-Infected-Susceptible (SIS) model is a widely used model for the spread of information and infectious diseases, particularly non-immunizing ones, on a graph. Given a highly contagious disease, a natural question is how to best vaccinate individuals to minimize the disease's extinction time. While previous works showed that the problem of optimal vaccination is closely linked to the NP-hard Spectral Radius Minimization (SRM) problem, they assumed that the graph is known, which is often not the case in practice. In this work, we consider the problem of minimizing the extinction time of an outbreak modeled by an SIS model where the graph on which the disease spreads is unknown and only the infection states of the vertices are observed. To this end, we split the problem into two: learning the graph and determining effective vaccination strategies. We propose a novel inclusion-exclusion-based learning algorithm and, unlike previous approaches, establish its sample complexity for graph recovery. We then detail an optimal algorithm for the SRM problem and prove that its running time is polynomial in the number of vertices for graphs with bounded treewidth. This is complemented by an efficient and effective polynomial-time greedy heuristic for any graph. Finally, we present experiments on synthetic and real-world data that numerically validate our learning and vaccination algorithms.
Asymptotic Performance of Time-Varying Bayesian Optimization
May 19, 2025Time-Varying Bayesian Optimization (TVBO) is the go-to framework for optimizing a time-varying black-box objective function that may be noisy and expensive to evaluate. Is it possible for the instantaneous regret of a TVBO algorithm to vanish asymptotically, and if so, when? We answer this question of great theoretical importance by providing algorithm-independent lower regret bounds and upper regret bounds for TVBO algorithms, from which we derive sufficient conditions for a TVBO algorithm to have the no-regret property. Our analysis covers all major classes of stationary kernel functions.
Optimizing Through Change: Bounds and Recommendations for Time-Varying Bayesian Optimization Algorithms
Jan 31, 2025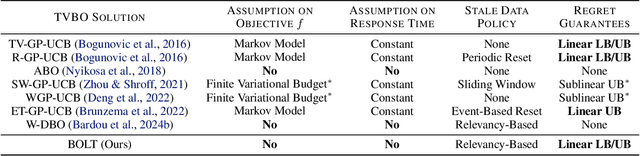
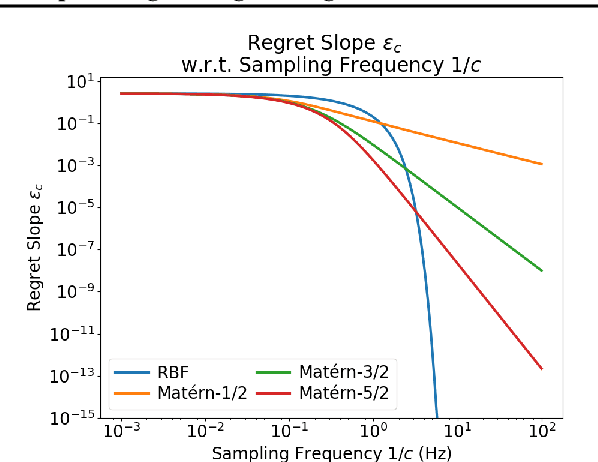
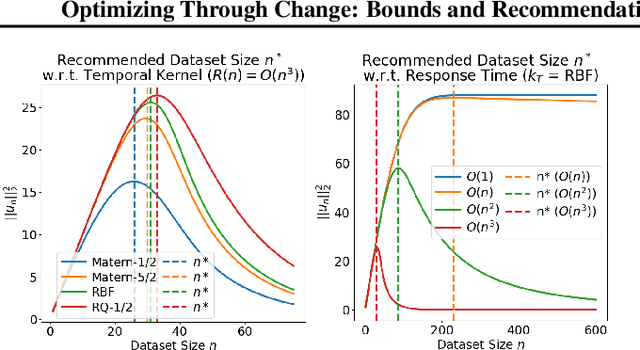
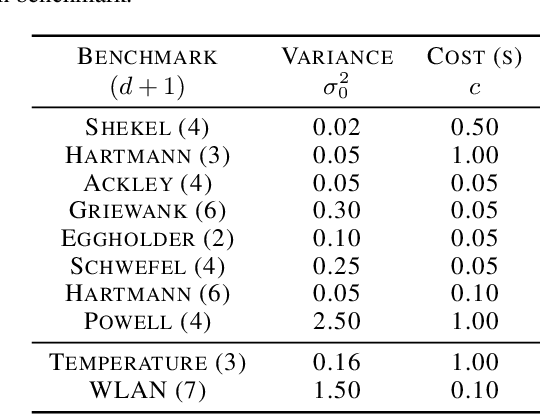
Time-Varying Bayesian Optimization (TVBO) is the go-to framework for optimizing a time-varying, expensive, noisy black-box function. However, most of the solutions proposed so far either rely on unrealistic assumptions on the nature of the objective function or do not offer any theoretical guarantees. We propose the first analysis that asymptotically bounds the cumulative regret of TVBO algorithms under mild and realistic assumptions only. In particular, we provide an algorithm-independent lower regret bound and an upper regret bound that holds for a large class of TVBO algorithms. Based on this analysis, we formulate recommendations for TVBO algorithms and show how an algorithm (BOLT) that follows them performs better than the state-of-the-art of TVBO through experiments on synthetic and real-world problems.
Complexity of Minimizing Projected-Gradient-Dominated Functions with Stochastic First-order Oracles
Aug 03, 2024
This work investigates the performance limits of projected stochastic first-order methods for minimizing functions under the $(\alpha,\tau,\mathcal{X})$-projected-gradient-dominance property, that asserts the sub-optimality gap $F(\mathbf{x})-\min_{\mathbf{x}'\in \mathcal{X}}F(\mathbf{x}')$ is upper-bounded by $\tau\cdot\|\mathcal{G}_{\eta,\mathcal{X}}(\mathbf{x})\|^{\alpha}$ for some $\alpha\in[1,2)$ and $\tau>0$ and $\mathcal{G}_{\eta,\mathcal{X}}(\mathbf{x})$ is the projected-gradient mapping with $\eta>0$ as a parameter. For non-convex functions, we show that the complexity lower bound of querying a batch smooth first-order stochastic oracle to obtain an $\epsilon$-global-optimum point is $\Omega(\epsilon^{-{2}/{\alpha}})$. Furthermore, we show that a projected variance-reduced first-order algorithm can obtain the upper complexity bound of $\mathcal{O}(\epsilon^{-{2}/{\alpha}})$, matching the lower bound. For convex functions, we establish a complexity lower bound of $\Omega(\log(1/\epsilon)\cdot\epsilon^{-{2}/{\alpha}})$ for minimizing functions under a local version of gradient-dominance property, which also matches the upper complexity bound of accelerated stochastic subgradient methods.
Fast Proxy Experiment Design for Causal Effect Identification
Jul 07, 2024Identifying causal effects is a key problem of interest across many disciplines. The two long-standing approaches to estimate causal effects are observational and experimental (randomized) studies. Observational studies can suffer from unmeasured confounding, which may render the causal effects unidentifiable. On the other hand, direct experiments on the target variable may be too costly or even infeasible to conduct. A middle ground between these two approaches is to estimate the causal effect of interest through proxy experiments, which are conducted on variables with a lower cost to intervene on compared to the main target. Akbari et al. [2022] studied this setting and demonstrated that the problem of designing the optimal (minimum-cost) experiment for causal effect identification is NP-complete and provided a naive algorithm that may require solving exponentially many NP-hard problems as a sub-routine in the worst case. In this work, we provide a few reformulations of the problem that allow for designing significantly more efficient algorithms to solve it as witnessed by our extensive simulations. Additionally, we study the closely-related problem of designing experiments that enable us to identify a given effect through valid adjustments sets.
Why the Metric Backbone Preserves Community Structure
Jun 06, 2024



The metric backbone of a weighted graph is the union of all-pairs shortest paths. It is obtained by removing all edges $(u,v)$ that are not the shortest path between $u$ and $v$. In networks with well-separated communities, the metric backbone tends to preserve many inter-community edges, because these edges serve as bridges connecting two communities, but tends to delete many intra-community edges because the communities are dense. This suggests that the metric backbone would dilute or destroy the community structure of the network. However, this is not borne out by prior empirical work, which instead showed that the metric backbone of real networks preserves the community structure of the original network well. In this work, we analyze the metric backbone of a broad class of weighted random graphs with communities, and we formally prove the robustness of the community structure with respect to the deletion of all the edges that are not in the metric backbone. An empirical comparison of several graph sparsification techniques confirms our theoretical finding and shows that the metric backbone is an efficient sparsifier in the presence of communities.
This Too Shall Pass: Removing Stale Observations in Dynamic Bayesian Optimization
May 23, 2024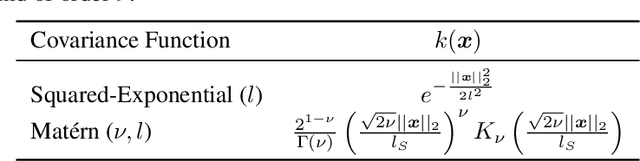
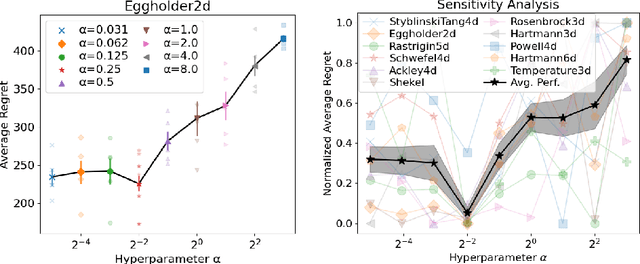
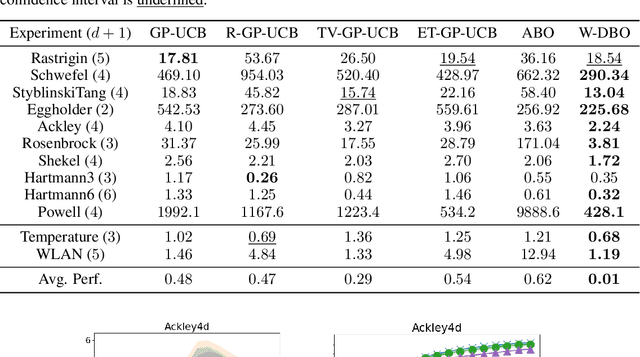
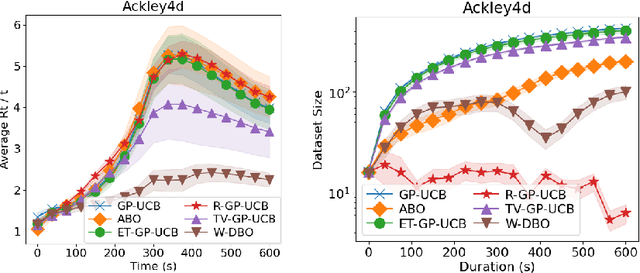
Bayesian Optimization (BO) has proven to be very successful at optimizing a static, noisy, costly-to-evaluate black-box function $f : \mathcal{S} \to \mathbb{R}$. However, optimizing a black-box which is also a function of time (i.e., a dynamic function) $f : \mathcal{S} \times \mathcal{T} \to \mathbb{R}$ remains a challenge, since a dynamic Bayesian Optimization (DBO) algorithm has to keep track of the optimum over time. This changes the nature of the optimization problem in at least three aspects: (i) querying an arbitrary point in $\mathcal{S} \times \mathcal{T}$ is impossible, (ii) past observations become less and less relevant for keeping track of the optimum as time goes by and (iii) the DBO algorithm must have a high sampling frequency so it can collect enough relevant observations to keep track of the optimum through time. In this paper, we design a Wasserstein distance-based criterion able to quantify the relevancy of an observation with respect to future predictions. Then, we leverage this criterion to build W-DBO, a DBO algorithm able to remove irrelevant observations from its dataset on the fly, thus maintaining simultaneously a good predictive performance and a high sampling frequency, even in continuous-time optimization tasks with unknown horizon. Numerical experiments establish the superiority of W-DBO, which outperforms state-of-the-art methods by a comfortable margin.
Universal Lower Bounds and Optimal Rates: Achieving Minimax Clustering Error in Sub-Exponential Mixture Models
Feb 23, 2024Clustering is a pivotal challenge in unsupervised machine learning and is often investigated through the lens of mixture models. The optimal error rate for recovering cluster labels in Gaussian and sub-Gaussian mixture models involves ad hoc signal-to-noise ratios. Simple iterative algorithms, such as Lloyd's algorithm, attain this optimal error rate. In this paper, we first establish a universal lower bound for the error rate in clustering any mixture model, expressed through a Chernoff divergence, a more versatile measure of model information than signal-to-noise ratios. We then demonstrate that iterative algorithms attain this lower bound in mixture models with sub-exponential tails, notably emphasizing location-scale mixtures featuring Laplace-distributed errors. Additionally, for datasets better modelled by Poisson or Negative Binomial mixtures, we study mixture models whose distributions belong to an exponential family. In such mixtures, we establish that Bregman hard clustering, a variant of Lloyd's algorithm employing a Bregman divergence, is rate optimal.