 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benefits of Diversity: Combining Comparisons and Ratings for Efficient Scoring
Feb 08, 2026Should humans be asked to evaluate entities individually or comparatively? This question has been the subject of long debates. In this work, we show that, interestingly, combining both forms of preference elicitation can outperform the focus on a single kind. More specifically, we introduce SCoRa (Scoring from Comparisons and Ratings), a unified probabilistic model that allows to learn from both signals. We prove that the MAP estimator of SCoRa is well-behaved. It verifies monotonicity and robustness guarantees. We then empirically show that SCoRa recovers accurate scores, even under model mismatch. Most interestingly, we identify a realistic setting where combining comparisons and ratings outperforms using either one alone, and when the accurate ordering of top entities is critical. Given the de facto availability of signals of multiple forms, SCoRa additionally offers a versatile foundation for preference learning.
Optimal Graph Clustering without Edge Density Signals
Oct 24, 2025This paper establishes the theoretical limits of graph clustering under the Popularity-Adjusted Block Model (PABM), addressing limitations of existing models. In contrast to the Stochastic Block Model (SBM), which assumes uniform vertex degrees, and to the Degree-Corrected Block Model (DCBM), which applies uniform degree corrections across clusters, PABM introduces separate popularity parameters for intra- and inter-cluster connections. Our main contribution is the characterization of the optimal error rate for clustering under PABM, which provides novel insights on clustering hardness: we demonstrate that unlike SBM and DCBM, cluster recovery remains possible in PABM even when traditional edge-density signals vanish, provided intra- and inter-cluster popularity coefficients differ. This highlights a dimension of degree heterogeneity captured by PABM but overlooked by DCBM: local differences in connectivity patterns can enhance cluster separability independently of global edge densities. Finally, because PABM exhibits a richer structure, its expected adjacency matrix has rank between $k$ and $k^2$, where $k$ is the number of clusters. As a result, spectral embeddings based on the top $k$ eigenvectors may fail to capture important structural information. Our numerical experiments on both synthetic and real datasets confirm that spectral clustering algorithms incorporating $k^2$ eigenvectors outperform traditional spectral approaches.
Ranking Items from Discrete Ratings: The Cost of Unknown User Thresholds
Oct 02, 2025Ranking items is a central task in many information retrieval and recommender systems. User input for the ranking task often comes in the form of ratings on a coarse discrete scale. We ask whether it is possible to recover a fine-grained item ranking from such coarse-grained ratings. We model items as having scores and users as having thresholds; a user rates an item positively if the item's score exceeds the user's threshold. Although all users agree on the total item order, estimating that order is challenging when both the scores and the thresholds are latent. Under our model, any ranking method naturally partitions the $n$ items into bins; the bins are ordered, but the items inside each bin are still unordered. Users arrive sequentially, and every new user can be queried to refine the current ranking. We prove that achieving a near-perfect ranking, measured by Spearman distance, requires $\Theta(n^2)$ users (and therefore $\Omega(n^2)$ queries). This is significantly worse than the $O(n\log n)$ queries needed to rank from comparisons; the gap reflects the additional queries needed to identify the users who have the appropriate thresholds. Our bound also quantifies the impact of a mismatch between score and threshold distributions via a quadratic divergence factor. To show the tightness of our results, we provide a ranking algorithm whose query complexity matches our bound up to a logarithmic factor. Our work reveals a tension in online ranking: diversity in thresholds is necessary to merge coarse ratings from many users into a fine-grained ranking, but this diversity has a cost if the thresholds are a priori unknown.
Recycling History: Efficient Recommendations from Contextual Dueling Bandits
Aug 26, 2025The contextual duelling bandit problem models adaptive recommender systems, where the algorithm presents a set of items to the user, and the user's choice reveals their preference. This setup is well suited for implicit choices users make when navigating a content platform, but does not capture other possible comparison queries. Motivated by the fact that users provide more reliable feedback after consuming items, we propose a new bandit model that can be described as follows. The algorithm recommends one item per time step; after consuming that item, the user is asked to compare it with another item chosen from the user's consumption history. Importantly, in our model, this comparison item can be chosen without incurring any additional regret, potentially leading to better performance. However, the regret analysis is challenging because of the temporal dependency in the user's history. To overcome this challenge, we first show that the algorithm can construct informative queries provided the history is rich, i.e., satisfies a certain diversity condition. We then show that a short initial random exploration phase is sufficient for the algorithm to accumulate a rich history with high probability. This result, proven via matrix concentration bounds, yields $O(\sqrt{T})$ regret guarantees. Additionally, our simulations show that reusing past items for comparisons can lead to significantly lower regret than only comparing between simultaneously recommended items.
Measuring IIA Violations in Similarity Choices with Bayesian Models
Aug 20, 2025Similarity choice data occur when humans make choices among alternatives based on their similarity to a target, e.g., in the context of information retrieval and in embedding learning settings. Classical metric-based models of similarity choice assume independence of irrelevant alternatives (IIA), a property that allows for a simpler formulation. While IIA violations have been detected in many discrete choice settings, the similarity choice setting has received scant attention. This is because the target-dependent nature of the choice complicates IIA testing. We propose two statistical methods to test for IIA: a classical goodness-of-fit test and a Bayesian counterpart based on the framework of Posterior Predictive Checks (PPC). This Bayesian approach, our main technical contribution, quantifies the degree of IIA violation beyond its mere significance. We curate two datasets: one with choice sets designed to elicit IIA violations, and another with randomly generated choice sets from the same item universe. Our tests confirmed significant IIA violations on both datasets, and notably, we find a comparable degree of violation between them. Further, we devise a new PPC test for population homogeneity. Results show that the population is indeed homogenous, suggesting that the IIA violations are driven by context effects -- specifically, interactions within the choice sets. These results highlight the need for new similarity choice models that account for such context effects.
Recommendations from Sparse Comparison Data: Provably Fast Convergence for Nonconvex Matrix Factorization
Feb 27, 2025
This paper provides a theoretical analysis of a new learning problem for recommender systems where users provide feedback by comparing pairs of items instead of rating them individually. We assume that comparisons stem from latent user and item features, which reduces the task of predicting preferences to learning these features from comparison data. Similar to the classical matrix factorization problem, the main challenge in this learning task is that the resulting loss function is nonconvex. Our analysis shows that the loss function exhibits (restricted) strong convexity near the true solution, which ensures gradient-based methods converge exponentially, given an appropriate warm start. Importantly, this result holds in a sparse data regime, where each user compares only a few pairs of items. Our main technical contribution is to extend certain concentration inequalities commonly used in matrix completion to our model. Our work demonstrates that learning personalized recommendations from comparison data is computationally and statistically efficient.
Why the Metric Backbone Preserves Community Structure
Jun 06, 2024



The metric backbone of a weighted graph is the union of all-pairs shortest paths. It is obtained by removing all edges $(u,v)$ that are not the shortest path between $u$ and $v$. In networks with well-separated communities, the metric backbone tends to preserve many inter-community edges, because these edges serve as bridges connecting two communities, but tends to delete many intra-community edges because the communities are dense. This suggests that the metric backbone would dilute or destroy the community structure of the network. However, this is not borne out by prior empirical work, which instead showed that the metric backbone of real networks preserves the community structure of the original network well. In this work, we analyze the metric backbone of a broad class of weighted random graphs with communities, and we formally prove the robustness of the community structure with respect to the deletion of all the edges that are not in the metric backbone. An empirical comparison of several graph sparsification techniques confirms our theoretical finding and shows that the metric backbone is an efficient sparsifier in the presence of communities.
Causal Effect Identification in a Sub-Population with Latent Variables
May 23, 2024



The s-ID problem seeks to compute a causal effect in a specific sub-population from the observational data pertaining to the same sub population (Abouei et al., 2023). This problem has been addressed when all the variables in the system are observable. In this paper, we consider an extension of the s-ID problem that allows for the presence of latent variables. To tackle the challenges induced by the presence of latent variables in a sub-population, we first extend the classical relevant graphical definitions, such as c-components and Hedges, initially defined for the so-called ID problem (Pearl, 1995; Tian & Pearl, 2002), to their new counterparts. Subsequently, we propose a sound algorithm for the s-ID problem with latent variables.
Universal Lower Bounds and Optimal Rates: Achieving Minimax Clustering Error in Sub-Exponential Mixture Models
Feb 23, 2024Clustering is a pivotal challenge in unsupervised machine learning and is often investigated through the lens of mixture models. The optimal error rate for recovering cluster labels in Gaussian and sub-Gaussian mixture models involves ad hoc signal-to-noise ratios. Simple iterative algorithms, such as Lloyd's algorithm, attain this optimal error rate. In this paper, we first establish a universal lower bound for the error rate in clustering any mixture model, expressed through a Chernoff divergence, a more versatile measure of model information than signal-to-noise ratios. We then demonstrate that iterative algorithms attain this lower bound in mixture models with sub-exponential tails, notably emphasizing location-scale mixtures featuring Laplace-distributed errors. Additionally, for datasets better modelled by Poisson or Negative Binomial mixtures, we study mixture models whose distributions belong to an exponential family. In such mixtures, we establish that Bregman hard clustering, a variant of Lloyd's algorithm employing a Bregman divergence, is rate optimal.
Efficiently Escaping Saddle Points for Non-Convex Policy Optimization
Nov 15, 2023
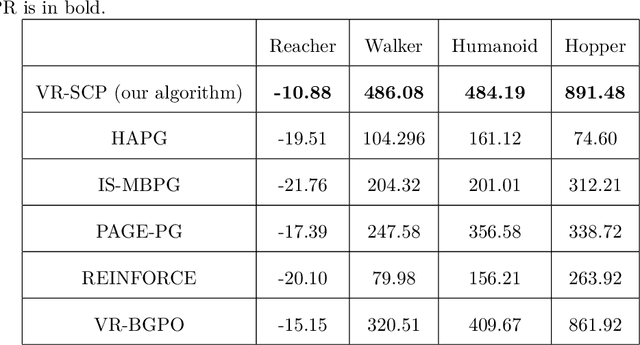
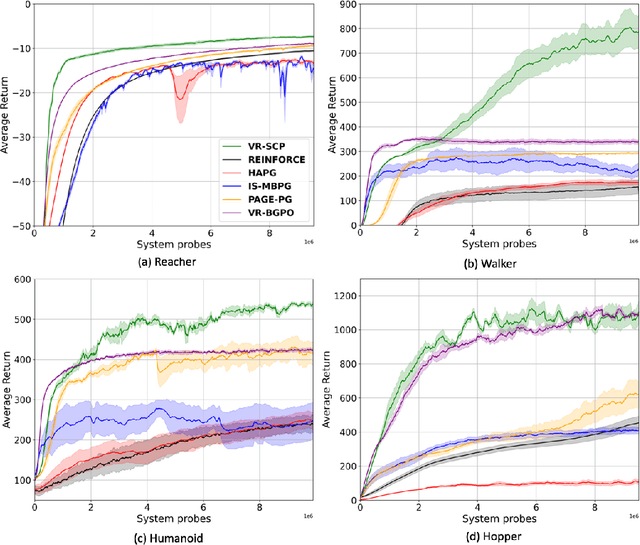
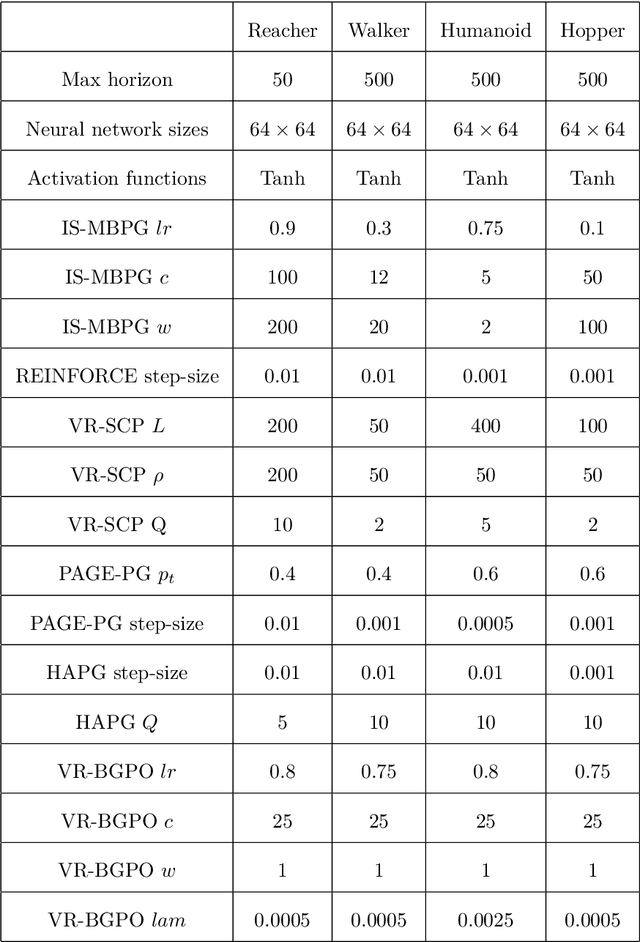
Policy gradient (PG) is widely used in reinforcement learning due to its scalability and good performance. In recent years, several variance-reduced PG methods have been proposed with a theoretical guarantee of converging to an approximate first-order stationary point (FOSP) with the sample complexity of $O(\epsilon^{-3})$. However, FOSPs could be bad local optima or saddle points. Moreover, these algorithms often use importance sampling (IS) weights which could impair the statistical effectiveness of variance reduction. In this paper, we propose a variance-reduced second-order method that uses second-order information in the form of Hessian vector products (HVP) and converges to an approximate second-order stationary point (SOSP) with sample complexity of $\tilde{O}(\epsilon^{-3})$. This rate improves the best-known sample complexity for achieving approximate SOSPs by a factor of $O(\epsilon^{-0.5})$. Moreover, the proposed variance reduction technique bypasses IS weights by using HVP terms. Our experimental results show that the proposed algorithm outperforms the state of the art and is more robust to changes in random seeds.