 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOBSKAPE: A Framework for Generating Synthetic Job Postings to Enhance Skill Matching
Feb 05, 2024



Recent approaches in skill matching, employing synthetic training data for classification or similarity model training, have shown promising results, reducing the need for time-consuming and expensive annotations. However, previous synthetic datasets have limitations, such as featuring only one skill per sentence and generally comprising short sentences. In this paper, we introduce JobSkape, a framework to generate synthetic data that tackles these limitations, specifically designed to enhance skill-to-taxonomy matching. Within this framework, we create SkillSkape, a comprehensive open-source synthetic dataset of job postings tailored for skill-matching tasks. We introduce several offline metrics that show that our dataset resembles real-world data. Additionally, we present a multi-step pipeline for skill extraction and matching tasks using large language models (LLMs), benchmarking against known supervised methodologies. We outline that the downstream evaluation results on real-world data can beat baselines, underscoring its efficacy and adaptability.
Studying Lobby Influence in the European Parliament
Sep 20, 2023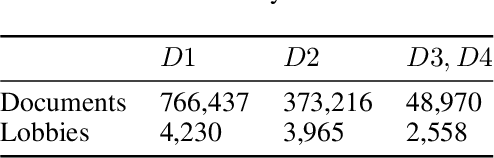


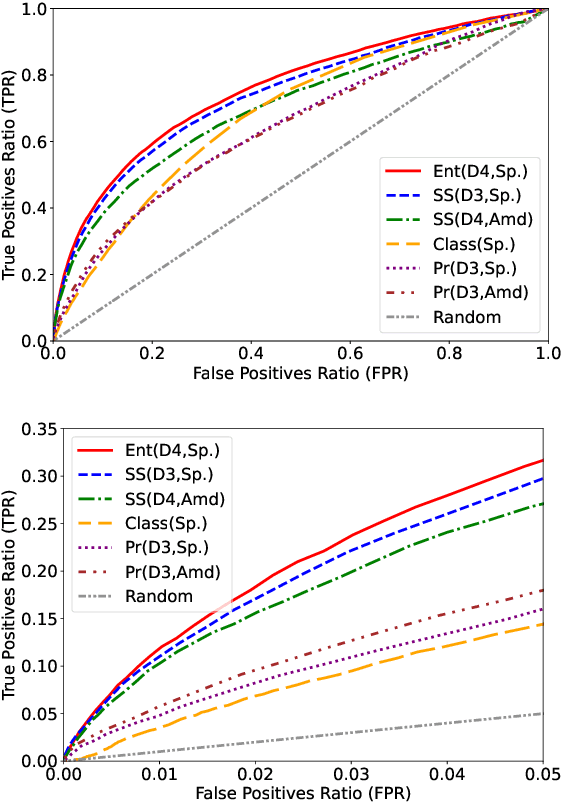
We present a method based on natural language processing (NLP), for studying the influence of interest groups (lobbies) in the law-making process in the European Parliament (EP). We collect and analyze novel datasets of lobbies' position papers and speeches made by members of the EP (MEPs). By comparing these texts on the basis of semantic similarity and entailment, we are able to discover interpretable links between MEPs and lobbies. In the absence of a ground-truth dataset of such links, we perform an indirect validation by comparing the discovered links with a dataset, which we curate, of retweet links between MEPs and lobbies, and with the publicly disclosed meetings of MEPs. Our best method achieves an AUC score of 0.77 and performs significantly better than several baselines. Moreover, an aggregate analysis of the discovered links, between groups of related lobbies and political groups of MEPs, correspond to the expectations from the ideology of the groups (e.g., center-left groups are associated with social causes). We believe that this work, which encompasses the methodology, datasets, and results, is a step towards enhancing the transparency of the intricate decision-making processes within democratic institutions.