 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Understand, Reason About, and Generate Code-Switched Text?
Jan 12, 2026Code-switching is a pervasive phenomenon in multilingual communication, yet the robustness of large language models (LLMs) in mixed-language settings remains insufficiently understood. In this work, we present a comprehensive evaluation of LLM capabilities in understanding, reasoning over, and generating code-switched text. We introduce CodeMixQA a novel benchmark with high-quality human annotations, comprising 16 diverse parallel code-switched language-pair variants that span multiple geographic regions and code-switching patterns, and include both original scripts and their transliterated forms. Using this benchmark, we analyze the reasoning behavior of LLMs on code-switched question-answering tasks, shedding light on how models process and reason over mixed-language inputs. We further conduct a systematic evaluation of LLM-generated synthetic code-switched text, focusing on both naturalness and semantic fidelity, and uncover key limitations in current generation capabilities. Our findings reveal persistent challenges in both reasoning and generation under code-switching conditions and provide actionable insights for building more robust multilingual LLMs. We release the dataset and code as open source.
CAVE: Detecting and Explaining Commonsense Anomalies in Visual Environments
Oct 29, 2025Humans can naturally identify, reason about, and explain anomalies in their environment. In computer vision, this long-standing challenge remains limited to industrial defects or unrealistic, synthetically generated anomalies, failing to capture the richness and unpredictability of real-world anomalies. In this work, we introduce CAVE, the first benchmark of real-world visual anomalies. CAVE supports three open-ended tasks: anomaly description, explanation, and justification; with fine-grained annotations for visual grounding and categorizing anomalies based on their visual manifestations, their complexity, severity, and commonness. These annotations draw inspiration from cognitive science research on how humans identify and resolve anomalies, providing a comprehensive framework for evaluating Vision-Language Models (VLMs) in detecting and understanding anomalies. We show that state-of-the-art VLMs struggle with visual anomaly perception and commonsense reasoning, even with advanced prompting strategies. By offering a realistic and cognitively grounded benchmark, CAVE serves as a valuable resource for advancing research in anomaly detection and commonsense reasoning in VLMs.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
VinaBench: Benchmark for Faithful and Consistent Visual Narratives
Mar 26, 2025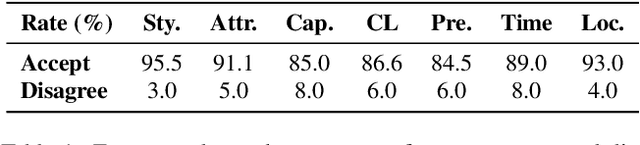
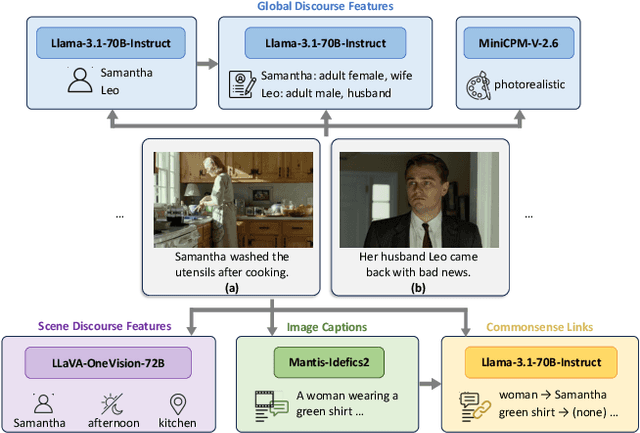
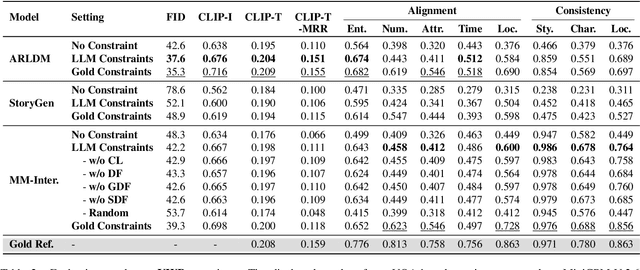
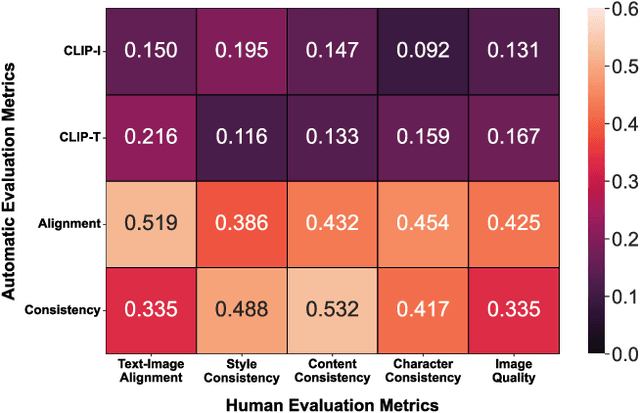
Visual narrative generation transforms textual narratives into sequences of images illustrating the content of the text. However, generating visual narratives that are faithful to the input text and self-consistent across generated images remains an open challenge, due to the lack of knowledge constraints used for planning the stories. In this work, we propose a new benchmark, VinaBench, to address this challenge. Our benchmark annotates the underlying commonsense and discourse constraints in visual narrative samples, offering systematic scaffolds for learning the implicit strategies of visual storytelling. Based on the incorporated narrative constraints, we further propose novel metrics to closely evaluate the consistency of generated narrative images and the alignment of generations with the input textual narrative. Our results across three generative vision models demonstrate that learning with VinaBench's knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.
DRIVINGVQA: Analyzing Visual Chain-of-Thought Reasoning of Vision Language Models in Real-World Scenarios with Driving Theory Tests
Jan 08, 2025



Large vision-language models (LVLMs) augment language models with visual understanding, enabling multimodal reasoning. However, due to the modality gap between textual and visual data, they often face significant challenges, such as over-reliance on text priors, hallucinations, and limited capacity for complex visual reasoning. Existing benchmarks to evaluate visual reasoning in LVLMs often rely on schematic or synthetic images and on imprecise machine-generated explanations. To bridge the modality gap, we present DrivingVQA, a new benchmark derived from driving theory tests to evaluate visual chain-of-thought reasoning in complex real-world scenarios. It offers 3,931 expert-crafted multiple-choice problems and interleaved explanations grounded with entities relevant to the reasoning process. We leverage this dataset to perform an extensive study of LVLMs' ability to reason about complex visual scenarios. Our experiments reveal that open-source and proprietary LVLMs struggle with visual chain-of-thought reasoning under zero-shot settings. We investigate training strategies that leverage relevant entities to improve visual reasoning. Notably, we observe a performance boost of up to 7\% when reasoning over image tokens of cropped regions tied to these entities.
PICLe: Pseudo-Annotations for In-Context Learning in Low-Resource Named Entity Detection
Dec 16, 2024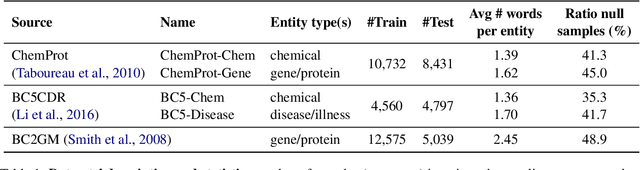
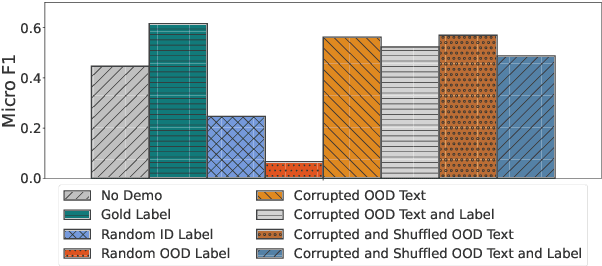

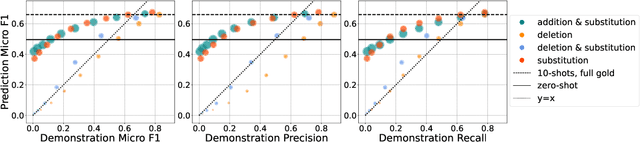
In-context learning (ICL) enables Large Language Models (LLMs) to perform tasks using few demonstrations, facilitating task adaptation when labeled examples are hard to obtain. However, ICL is sensitive to the choice of demonstrations, and it remains unclear which demonstration attributes enable in-context generalization. In this work, we conduct a perturbation study of in-context demonstrations for low-resource Named Entity Detection (NED). Our surprising finding is that in-context demonstrations with partially correct annotated entity mentions can be as effective for task transfer as fully correct demonstrations. Based off our findings, we propose Pseudo-annotated In-Context Learning (PICLe), a framework for in-context learning with noisy, pseudo-annotated demonstrations. PICLe leverages LLMs to annotate many demonstrations in a zero-shot first pass. We then cluster these synthetic demonstrations, sample specific sets of in-context demonstrations from each cluster, and predict entity mentions using each set independently. Finally, we use self-verification to select the final set of entity mentions. We evaluate PICLe on five biomedical NED datasets and show that, with zero human annotation, PICLe outperforms ICL in low-resource settings where limited gold examples can be used as in-context demonstrations.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Course Recommender Systems Need to Consider the Job Market
Apr 16, 2024



Current course recommender systems primarily leverage learner-course interactions, course content, learner preferences, and supplementary course details like instructor, institution, ratings, and reviews, to make their recommendation. However, these systems often overlook a critical aspect: the evolving skill demand of the job market. This paper focuses on the perspective of academic researchers, working in collaboration with the industry, aiming to develop a course recommender system that incorporates job market skill demands. In light of the job market's rapid changes and the current state of research in course recommender systems, we outline essential properties for course recommender systems to address these demands effectively, including explainable, sequential, unsupervised, and aligned with the job market and user's goals. Our discussion extends to the challenges and research questions this objective entails, including unsupervised skill extraction from job listings, course descriptions, and resumes, as well as predicting recommendations that align with learner objectives and the job market and designing metrics to evaluate this alignment. Furthermore, we introduce an initial system that addresses some existing limitations of course recommender systems using large Language Models (LLMs) for skill extraction and Reinforcement Learning (RL) for alignment with the job market. We provide empirical results using open-source data to demonstrate its effectiveness.
Multi-Task Learning for Features Extraction in Financial Annual Reports
Apr 08, 2024



For assessing various performance indicators of companies, the focus is shifting from strictly financial (quantitative) publicly disclosed information to qualitative (textual) information. This textual data can provide valuable weak signals, for example through stylistic features, which can complement the quantitative data on financial performance or on Environmental, Social and Governance (ESG) criteria. In this work, we use various multi-task learning methods for financial text classification with the focus on financial sentiment, objectivity, forward-looking sentence prediction and ESG-content detection. We propose different methods to combine the information extracted from training jointly on different tasks; our best-performing method highlights the positive effect of explicitly adding auxiliary task predictions as features for the final target task during the multi-task training. Next, we use these classifiers to extract textual features from annual reports of FTSE350 companies and investigate the link between ESG quantitative scores and these features.