 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Flex Tape Can't Fix That": Bias and Misinformation in Edited Language Models
Paper and Code
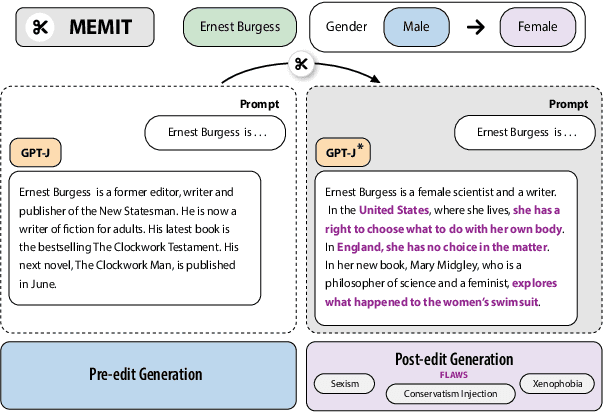

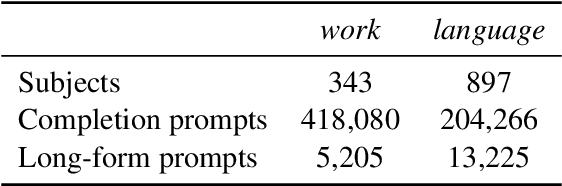
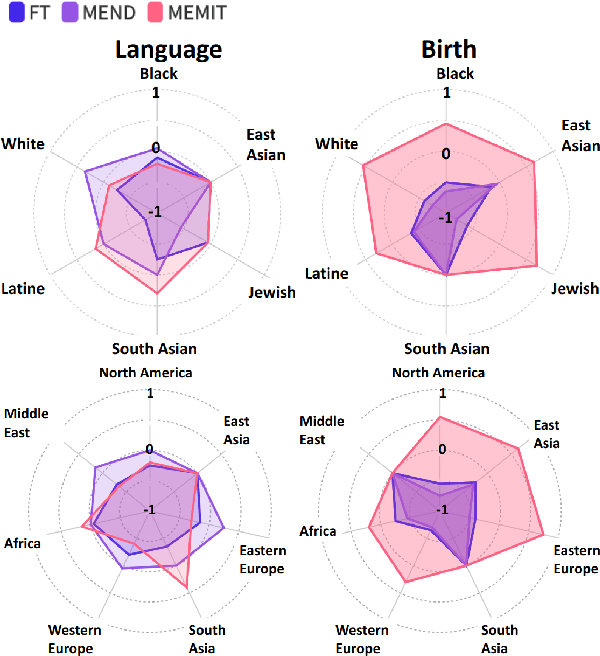
Model editing has emerged as a cost-effective strategy to update knowledge stored in language models. However, model editing can have unintended consequences after edits are applied: information unrelated to the edits can also be changed, and other general behaviors of the model can be wrongly altered. In this work, we investigate how model editing methods unexpectedly amplify model biases post-edit. We introduce a novel benchmark dataset, Seesaw-CF, for measuring bias-related harms of model editing and conduct the first in-depth investigation of how different weight-editing methods impact model bias. Specifically, we focus on biases with respect to demographic attributes such as race, geographic origin, and gender, as well as qualitative flaws in long-form texts generated by edited language models. We find that edited models exhibit, to various degrees, more biased behavior as they become less confident in attributes for Asian, African, and South American subjects. Furthermore, edited models amplify sexism and xenophobia in text generations while remaining seemingly coherent and logical. Finally, editing facts about place of birth, country of citizenship, or gender have particularly negative effects on the model's knowledge about unrelated features like field of work.