 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho's the (Multi-)Fairest of Them \textsc{All}: Rethinking Interpolation-Based Data Augmentation Through the Lens of Multicalibration
Dec 13, 2024Data augmentation methods, especially SoTA interpolation-based methods such as Fair Mixup, have been widely shown to increase model fairness. However, this fairness is evaluated on metrics that do not capture model uncertainty and on datasets with only one, relatively large, minority group. As a remedy, multicalibration has been introduced to measure fairness while accommodating uncertainty and accounting for multiple minority groups. However, existing methods of improving multicalibration involve reducing initial training data to create a holdout set for post-processing, which is not ideal when minority training data is already sparse. This paper uses multicalibration to more rigorously examine data augmentation for classification fairness. We stress-test four versions of Fair Mixup on two structured data classification problems with up to 81 marginalized groups, evaluating multicalibration violations and balanced accuracy. We find that on nearly every experiment, Fair Mixup \textit{worsens} baseline performance and fairness, but the simple vanilla Mixup \textit{outperforms} both Fair Mixup and the baseline, especially when calibrating on small groups. \textit{Combining} vanilla Mixup with multicalibration post-processing, which enforces multicalibration through post-processing on a holdout set, further increases fairness.
"Flex Tape Can't Fix That": Bias and Misinformation in Edited Language Models
Feb 29, 2024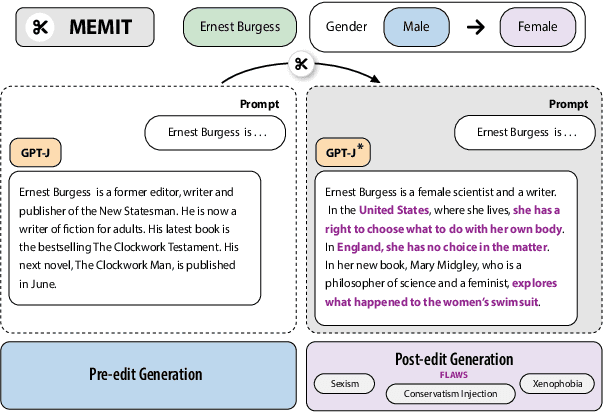

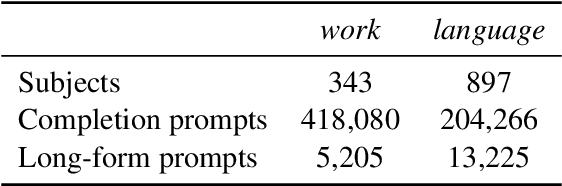
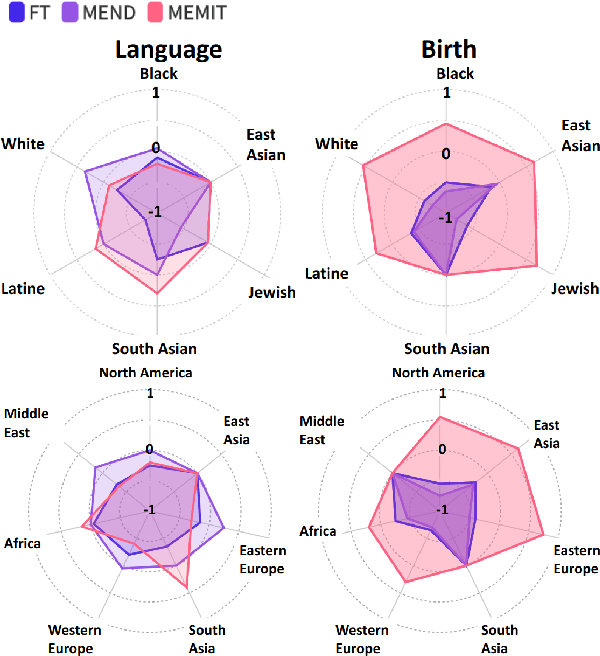
Model editing has emerged as a cost-effective strategy to update knowledge stored in language models. However, model editing can have unintended consequences after edits are applied: information unrelated to the edits can also be changed, and other general behaviors of the model can be wrongly altered. In this work, we investigate how model editing methods unexpectedly amplify model biases post-edit. We introduce a novel benchmark dataset, Seesaw-CF, for measuring bias-related harms of model editing and conduct the first in-depth investigation of how different weight-editing methods impact model bias. Specifically, we focus on biases with respect to demographic attributes such as race, geographic origin, and gender, as well as qualitative flaws in long-form texts generated by edited language models. We find that edited models exhibit, to various degrees, more biased behavior as they become less confident in attributes for Asian, African, and South American subjects. Furthermore, edited models amplify sexism and xenophobia in text generations while remaining seemingly coherent and logical. Finally, editing facts about place of birth, country of citizenship, or gender have particularly negative effects on the model's knowledge about unrelated features like field of work.
A Group-Specific Approach to NLP for Hate Speech Detection
Apr 21, 2023


Automatic hate speech detection is an important yet complex task, requiring knowledge of common sense, stereotypes of protected groups, and histories of discrimination, each of which may constantly evolve. In this paper, we propose a group-specific approach to NLP for online hate speech detection. The approach consists of creating and infusing historical and linguistic knowledge about a particular protected group into hate speech detection models, analyzing historical data about discrimination against a protected group to better predict spikes in hate speech against that group, and critically evaluating hate speech detection models through lenses of intersectionality and ethics. We demonstrate this approach through a case study on NLP for detection of antisemitic hate speech. The case study synthesizes the current English-language literature on NLP for antisemitism detection, introduces a novel knowledge graph of antisemitic history and language from the 20th century to the present, infuses information from the knowledge graph into a set of tweets over Logistic Regression and uncased DistilBERT baselines, and suggests that incorporating context from the knowledge graph can help models pick up subtle stereotypes.
Evaluating Word Embeddings with Categorical Modularity
Jun 02, 2021
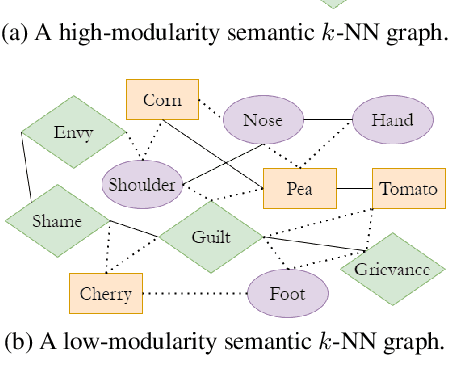
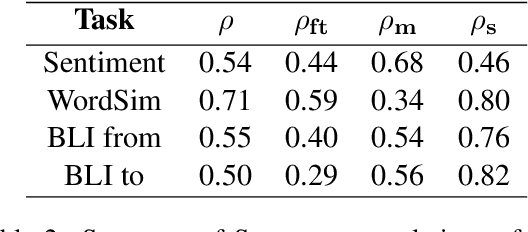
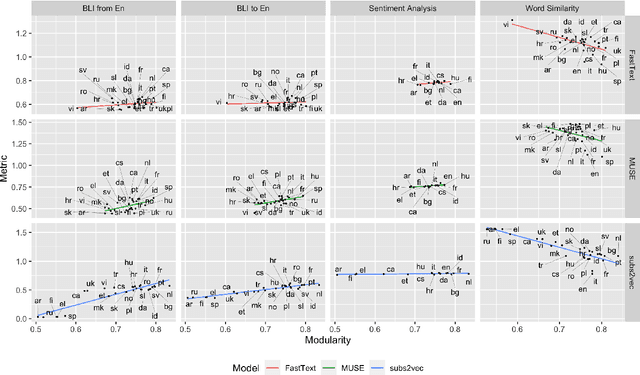
We introduce categorical modularity, a novel low-resource intrinsic metric to evaluate word embedding quality. Categorical modularity is a graph modularity metric based on the $k$-nearest neighbor graph constructed with embedding vectors of words from a fixed set of semantic categories, in which the goal is to measure the proportion of words that have nearest neighbors within the same categories. We use a core set of 500 words belonging to 59 neurobiologically motivated semantic categories in 29 languages and analyze three word embedding models per language (FastText, MUSE, and subs2vec). We find moderate to strong positive correlations between categorical modularity and performance on the monolingual tasks of sentiment analysis and word similarity calculation and on the cross-lingual task of bilingual lexicon induction both to and from English. Overall, we suggest that categorical modularity provides non-trivial predictive information about downstream task performance, with breakdowns of correlations by model suggesting some meta-predictive properties about semantic information loss as well.