 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Group-Specific Approach to NLP for Hate Speech Detection
Paper and Code



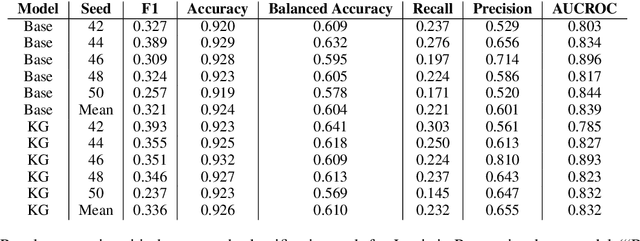
Automatic hate speech detection is an important yet complex task, requiring knowledge of common sense, stereotypes of protected groups, and histories of discrimination, each of which may constantly evolve. In this paper, we propose a group-specific approach to NLP for online hate speech detection. The approach consists of creating and infusing historical and linguistic knowledge about a particular protected group into hate speech detection models, analyzing historical data about discrimination against a protected group to better predict spikes in hate speech against that group, and critically evaluating hate speech detection models through lenses of intersectionality and ethics. We demonstrate this approach through a case study on NLP for detection of antisemitic hate speech. The case study synthesizes the current English-language literature on NLP for antisemitism detection, introduces a novel knowledge graph of antisemitic history and language from the 20th century to the present, infuses information from the knowledge graph into a set of tweets over Logistic Regression and uncased DistilBERT baselines, and suggests that incorporating context from the knowledge graph can help models pick up subtle stereotypes.