 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Unigram Distribution
Jun 04, 2021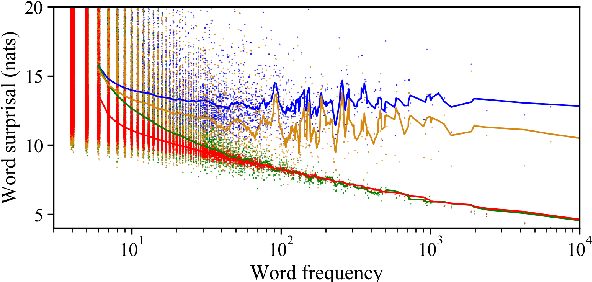
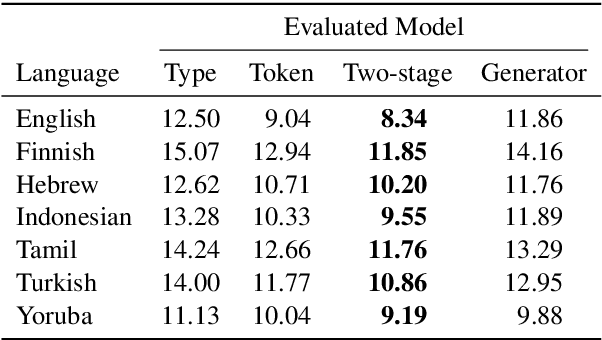

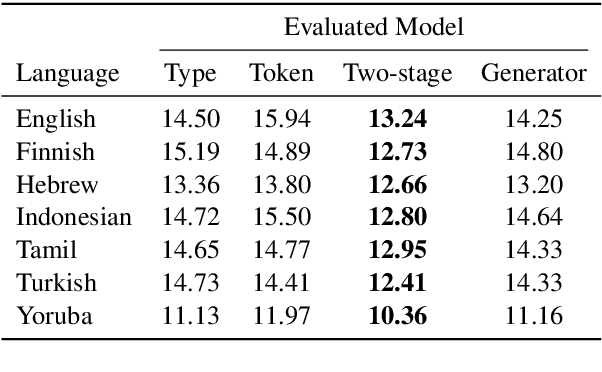
The unigram distribution is the non-contextual probability of finding a specific word form in a corpus. While of central importance to the study of language, it is commonly approximated by each word's sample frequency in the corpus. This approach, being highly dependent on sample size, assigns zero probability to any out-of-vocabulary (oov) word form. As a result, it produces negatively biased probabilities for any oov word form, while positively biased probabilities to in-corpus words. In this work, we argue in favor of properly modeling the unigram distribution -- claiming it should be a central task in natural language processing. With this in mind, we present a novel model for estimating it in a language (a neuralization of Goldwater et al.'s (2011) model) and show it produces much better estimates across a diverse set of 7 languages than the na\"ive use of neural character-level language models.
Evaluating Word Embeddings with Categorical Modularity
Jun 02, 2021
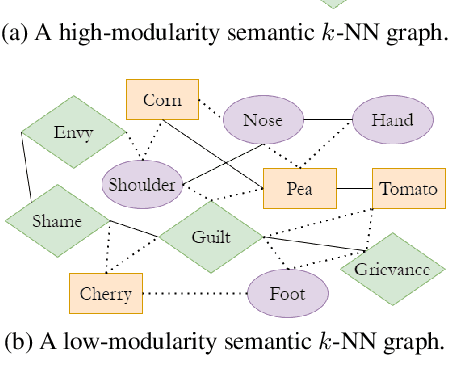
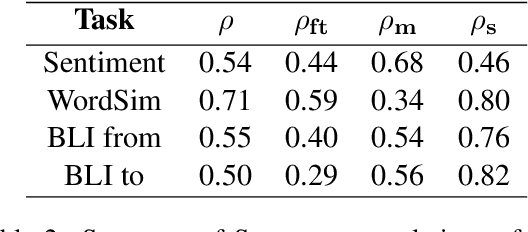
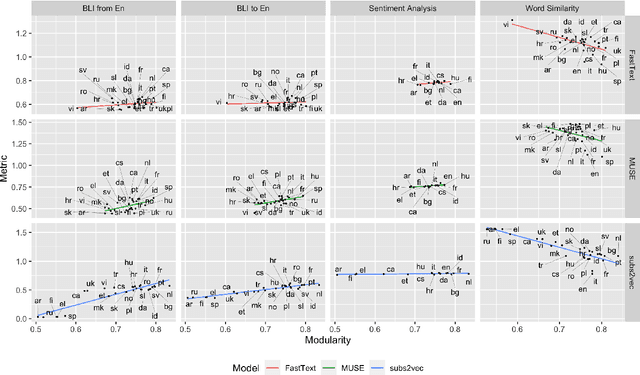
We introduce categorical modularity, a novel low-resource intrinsic metric to evaluate word embedding quality. Categorical modularity is a graph modularity metric based on the $k$-nearest neighbor graph constructed with embedding vectors of words from a fixed set of semantic categories, in which the goal is to measure the proportion of words that have nearest neighbors within the same categories. We use a core set of 500 words belonging to 59 neurobiologically motivated semantic categories in 29 languages and analyze three word embedding models per language (FastText, MUSE, and subs2vec). We find moderate to strong positive correlations between categorical modularity and performance on the monolingual tasks of sentiment analysis and word similarity calculation and on the cross-lingual task of bilingual lexicon induction both to and from English. Overall, we suggest that categorical modularity provides non-trivial predictive information about downstream task performance, with breakdowns of correlations by model suggesting some meta-predictive properties about semantic information loss as well.
Meaning to Form: Measuring Systematicity as Information
Jul 26, 2019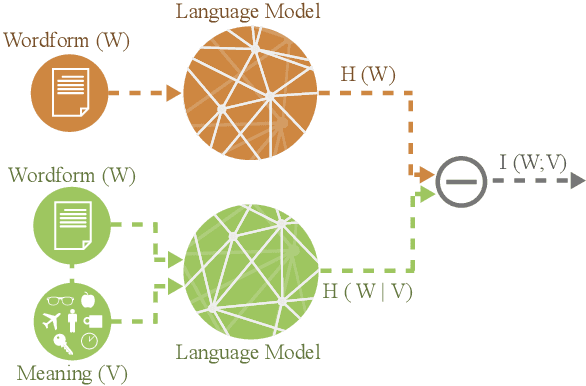
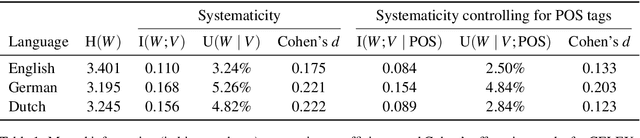
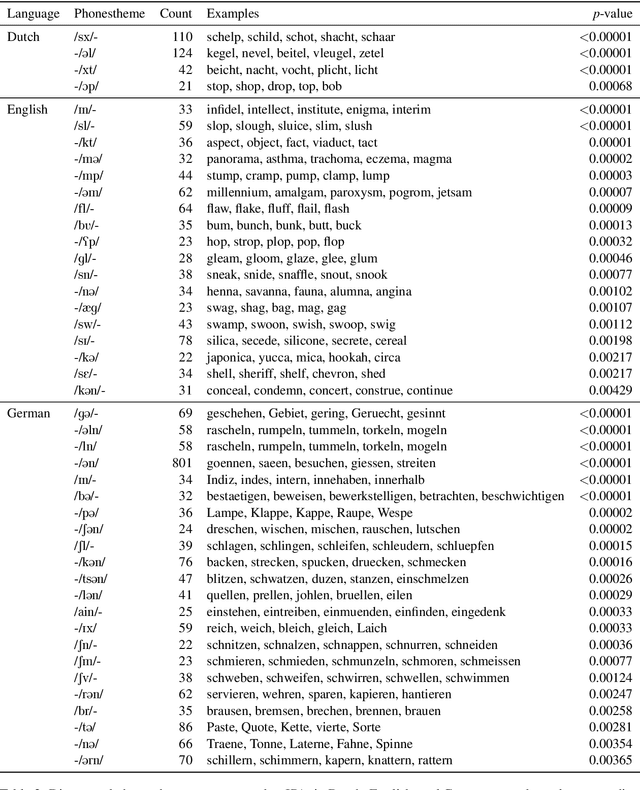
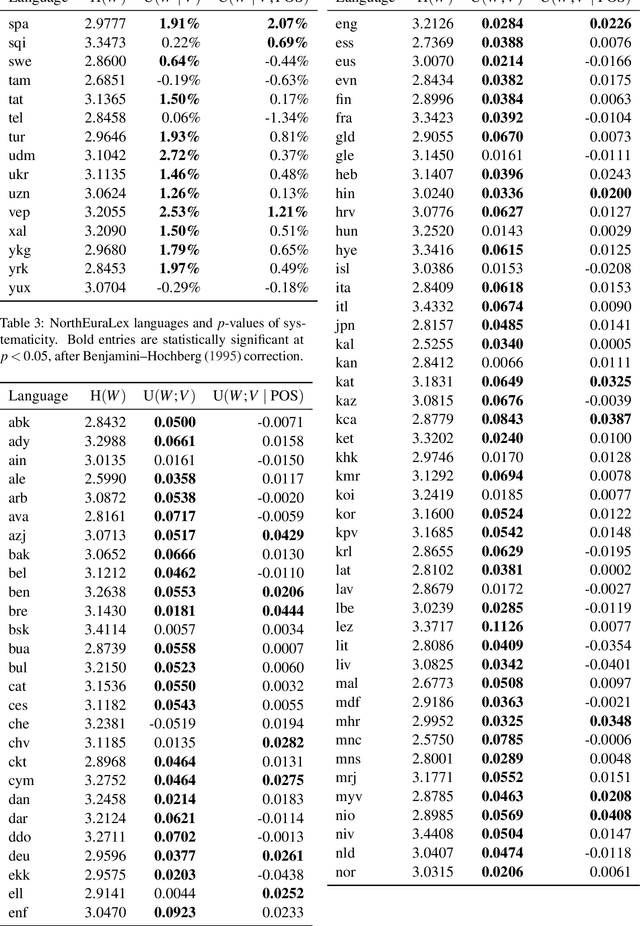
A longstanding debate in semiotics centers on the relationship between linguistic signs and their corresponding semantics: is there an arbitrary relationship between a word form and its meaning, or does some systematic phenomenon pervade? For instance, does the character bigram \textit{gl} have any systematic relationship to the meaning of words like \textit{glisten}, \textit{gleam} and \textit{glow}? In this work, we offer a holistic quantification of the systematicity of the sign using mutual information and recurrent neural networks. We employ these in a data-driven and massively multilingual approach to the question, examining 106 languages. We find a statistically significant reduction in entropy when modeling a word form conditioned on its semantic representation. Encouragingly, we also recover well-attested English examples of systematic affixes. We conclude with the meta-point: Our approximate effect size (measured in bits) is quite small---despite some amount of systematicity between form and meaning, an arbitrary relationship and its resulting benefits dominate human language.