 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Informally Romanized Language Identification
Apr 30, 2025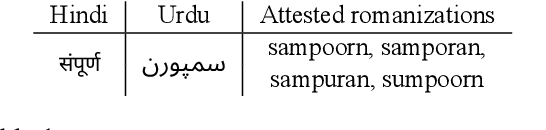
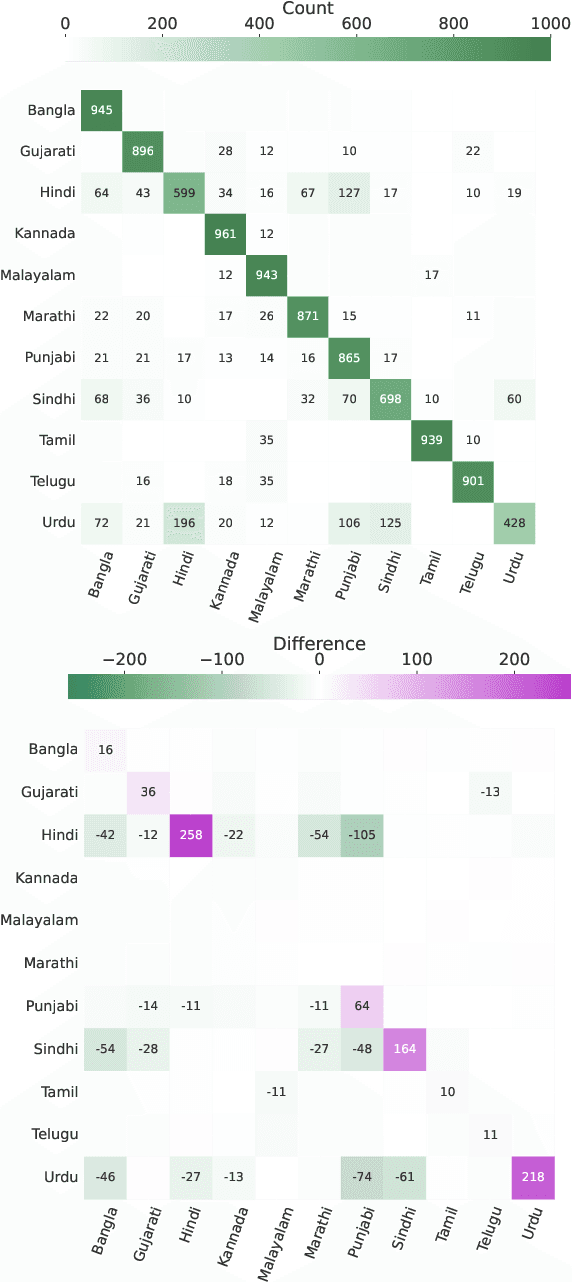

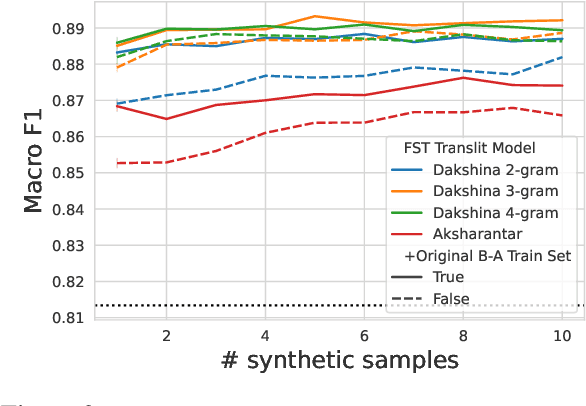
The Latin script is often used to informally write languages with non-Latin native scripts. In many cases (e.g., most languages in India), there is no conventional spelling of words in the Latin script, hence there will be high spelling variability in written text. Such romanization renders languages that are normally easily distinguished based on script highly confusable, such as Hindi and Urdu. In this work, we increase language identification (LID) accuracy for romanized text by improving the methods used to synthesize training sets. We find that training on synthetic samples which incorporate natural spelling variation yields higher LID system accuracy than including available naturally occurring examples in the training set, or even training higher capacity models. We demonstrate new state-of-the-art LID performance on romanized text from 20 Indic languages in the Bhasha-Abhijnaanam evaluation set (Madhani et al., 2023a), improving test F1 from the reported 74.7% (using a pretrained neural model) to 85.4% using a linear classifier trained solely on synthetic data and 88.2% when also training on available harvested text.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
Spelling convention sensitivity in neural language models
Mar 06, 2023



We examine whether large neural language models, trained on very large collections of varied English text, learn the potentially long-distance dependency of British versus American spelling conventions, i.e., whether spelling is consistently one or the other within model-generated strings. In contrast to long-distance dependencies in non-surface underlying structure (e.g., syntax), spelling consistency is easier to measure both in LMs and the text corpora used to train them, which can provide additional insight into certain observed model behaviors. Using a set of probe words unique to either British or American English, we first establish that training corpora exhibit substantial (though not total) consistency. A large T5 language model does appear to internalize this consistency, though only with respect to observed lexical items (not nonce words with British/American spelling patterns). We further experiment with correcting for biases in the training data by fine-tuning T5 on synthetic data that has been debiased, and find that finetuned T5 remains only somewhat sensitive to spelling consistency. Further experiments show GPT2 to be similarly limited.
Beyond Arabic: Software for Perso-Arabic Script Manipulation
Jan 26, 2023



This paper presents an open-source software library that provides a set of finite-state transducer (FST) components and corresponding utilities for manipulating the writing systems of languages that use the Perso-Arabic script. The operations include various levels of script normalization, including visual invariance-preserving operations that subsume and go beyond the standard Unicode normalization forms, as well as transformations that modify the visual appearance of characters in accordance with the regional orthographies for eleven contemporary languages from diverse language families. The library also provides simple FST-based romanization and transliteration. We additionally attempt to formalize the typology of Perso-Arabic characters by providing one-to-many mappings from Unicode code points to the languages that use them. While our work focuses on the Arabic script diaspora rather than Arabic itself, this approach could be adopted for any language that uses the Arabic script, thus providing a unified framework for treating a script family used by close to a billion people.
Structured abbreviation expansion in context
Oct 04, 2021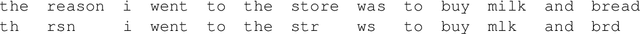
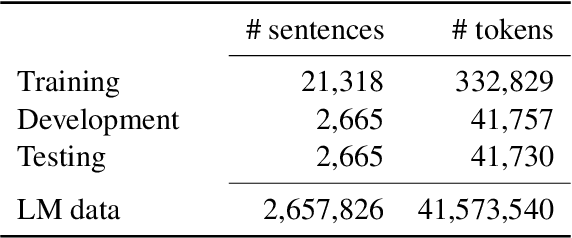
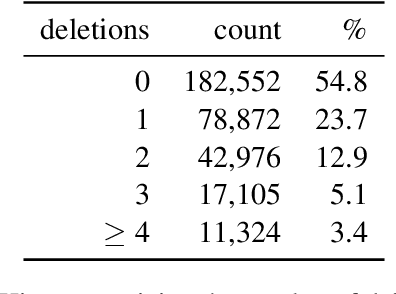
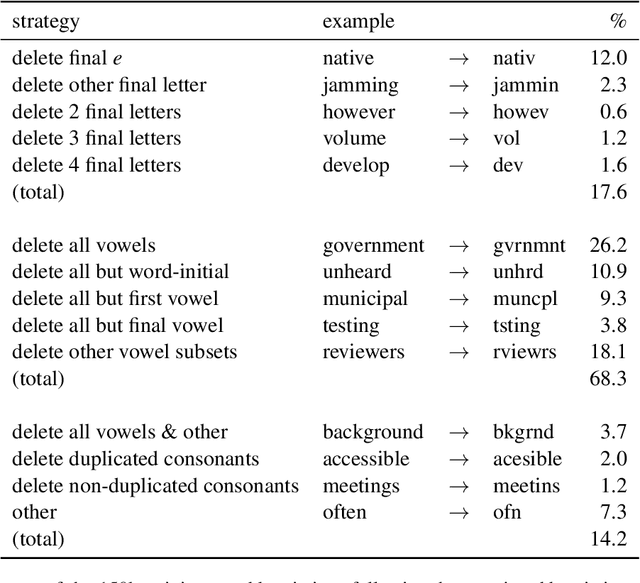
Ad hoc abbreviations are commonly found in informal communication channels that favor shorter messages. We consider the task of reversing these abbreviations in context to recover normalized, expanded versions of abbreviated messages. The problem is related to, but distinct from, spelling correction, in that ad hoc abbreviations are intentional and may involve substantial differences from the original words. Ad hoc abbreviations are productively generated on-the-fly, so they cannot be resolved solely by dictionary lookup. We generate a large, open-source data set of ad hoc abbreviations. This data is used to study abbreviation strategies and to develop two strong baselines for abbreviation expansion
Finding Concept-specific Biases in Form--Meaning Associations
Apr 29, 2021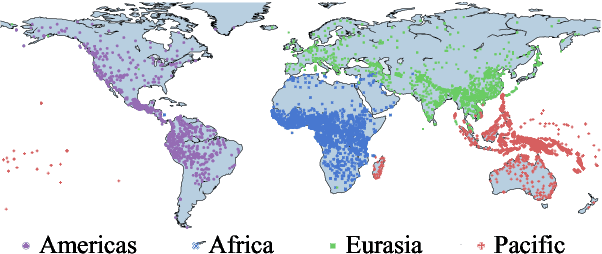
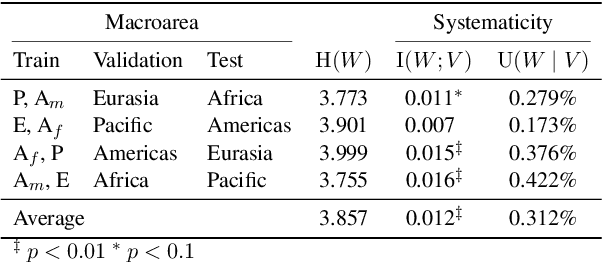
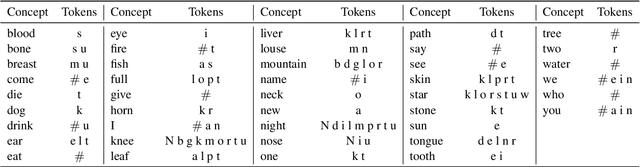
This work presents an information-theoretic operationalisation of cross-linguistic non-arbitrariness. It is not a new idea that there are small, cross-linguistic associations between the forms and meanings of words. For instance, it has been claimed (Blasi et al., 2016) that the word for "tongue" is more likely than chance to contain the phone [l]. By controlling for the influence of language family and geographic proximity within a very large concept-aligned, cross-lingual lexicon, we extend methods previously used to detect within language non-arbitrariness (Pimentel et al., 2019) to measure cross-linguistic associations. We find that there is a significant effect of non-arbitrariness, but it is unsurprisingly small (less than 0.5% on average according to our information-theoretic estimate). We also provide a concept-level analysis which shows that a quarter of the concepts considered in our work exhibit a significant level of cross-linguistic non-arbitrariness. In sum, the paper provides new methods to detect cross-linguistic associations at scale, and confirms their effects are minor.
Disambiguatory Signals are Stronger in Word-initial Positions
Feb 03, 2021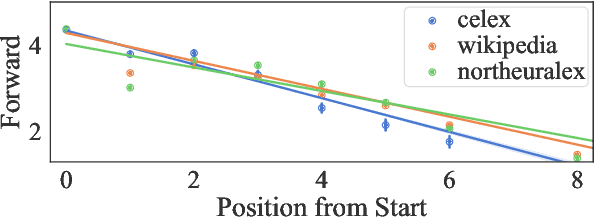
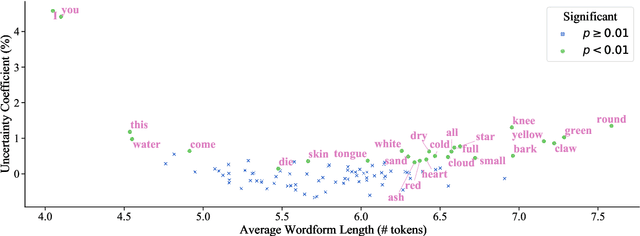
Psycholinguistic studies of human word processing and lexical access provide ample evidence of the preferred nature of word-initial versus word-final segments, e.g., in terms of attention paid by listeners (greater) or the likelihood of reduction by speakers (lower). This has led to the conjecture -- as in Wedel et al. (2019b), but common elsewhere -- that languages have evolved to provide more information earlier in words than later. Information-theoretic methods to establish such tendencies in lexicons have suffered from several methodological shortcomings that leave open the question of whether this high word-initial informativeness is actually a property of the lexicon or simply an artefact of the incremental nature of recognition. In this paper, we point out the confounds in existing methods for comparing the informativeness of segments early in the word versus later in the word, and present several new measures that avoid these confounds. When controlling for these confounds, we still find evidence across hundreds of languages that indeed there is a cross-linguistic tendency to front-load information in words.
Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset
Jul 02, 2020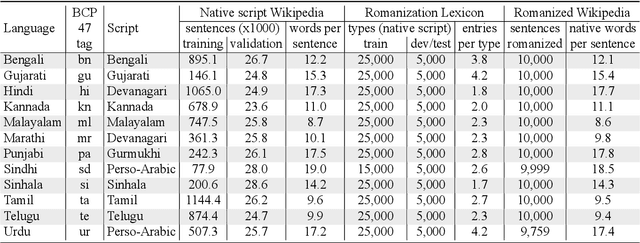
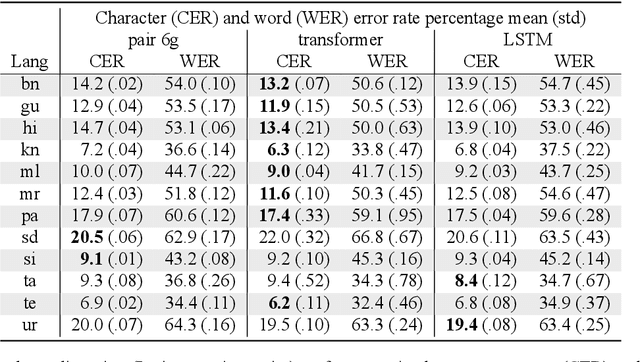

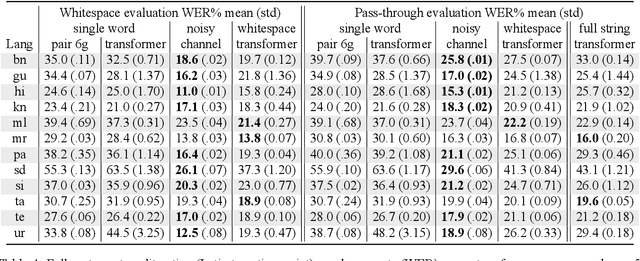
This paper describes the Dakshina dataset, a new resource consisting of text in both the Latin and native scripts for 12 South Asian languages. The dataset includes, for each language: 1) native script Wikipedia text; 2) a romanization lexicon; and 3) full sentence parallel data in both a native script of the language and the basic Latin alphabet. We document the methods used for preparation and selection of the Wikipedia text in each language; collection of attested romanizations for sampled lexicons; and manual romanization of held-out sentences from the native script collections. We additionally provide baseline results on several tasks made possible by the dataset, including single word transliteration, full sentence transliteration, and language modeling of native script and romanized text. Keywords: romanization, transliteration, South Asian languages
Phonotactic Complexity and its Trade-offs
May 07, 2020We present methods for calculating a measure of phonotactic complexity---bits per phoneme---that permits a straightforward cross-linguistic comparison. When given a word, represented as a sequence of phonemic segments such as symbols in the international phonetic alphabet, and a statistical model trained on a sample of word types from the language, we can approximately measure bits per phoneme using the negative log-probability of that word under the model. This simple measure allows us to compare the entropy across languages, giving insight into how complex a language's phonotactics are. Using a collection of 1016 basic concept words across 106 languages, we demonstrate a very strong negative correlation of -0.74 between bits per phoneme and the average length of words.
* Published in TACL: https://doi.org/10.1162/tacl_a_00296
Language-agnostic Multilingual Modeling
Apr 20, 2020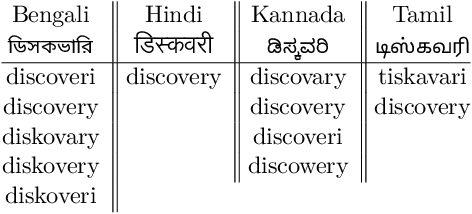
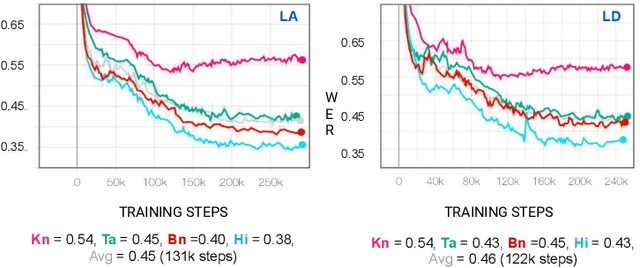
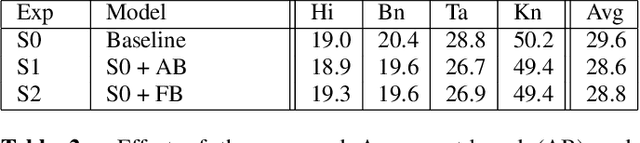
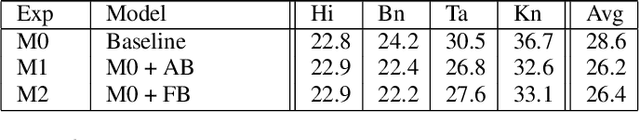
Multilingual Automated Speech Recognition (ASR) systems allow for the joint training of data-rich and data-scarce languages in a single model. This enables data and parameter sharing across languages, which is especially beneficial for the data-scarce languages. However, most state-of-the-art multilingual models require the encoding of language information and therefore are not as flexible or scalable when expanding to newer languages. Language-independent multilingual models help to address this issue, and are also better suited for multicultural societies where several languages are frequently used together (but often rendered with different writing systems). In this paper, we propose a new approach to building a language-agnostic multilingual ASR system which transforms all languages to one writing system through a many-to-one transliteration transducer. Thus, similar sounding acoustics are mapped to a single, canonical target sequence of graphemes, effectively separating the modeling and rendering problems. We show with four Indic languages, namely, Hindi, Bengali, Tamil and Kannada, that the language-agnostic multilingual model achieves up to 10% relative reduction in Word Error Rate (WER) over a language-dependent multilingual model.