 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMSD: Towards Multilingual Scientific Documents Similarity Measurement
Sep 19, 2023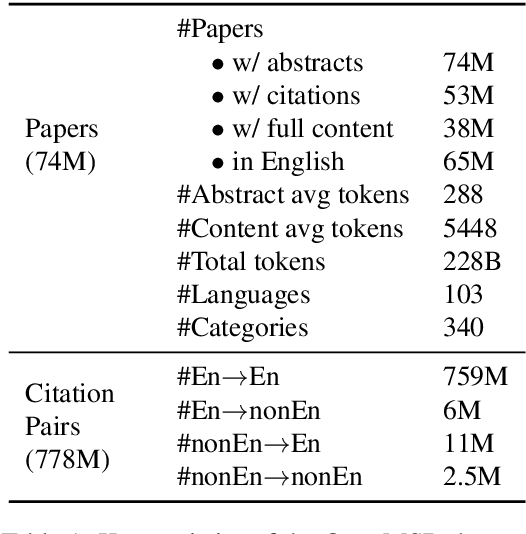
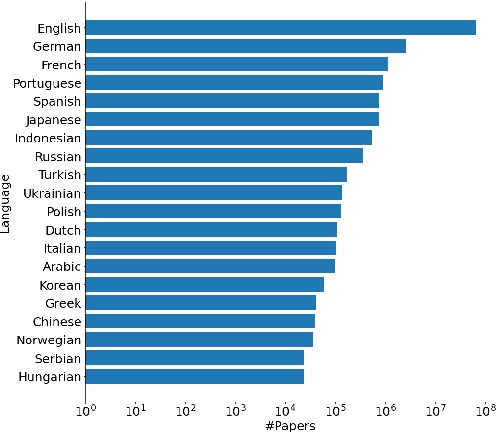
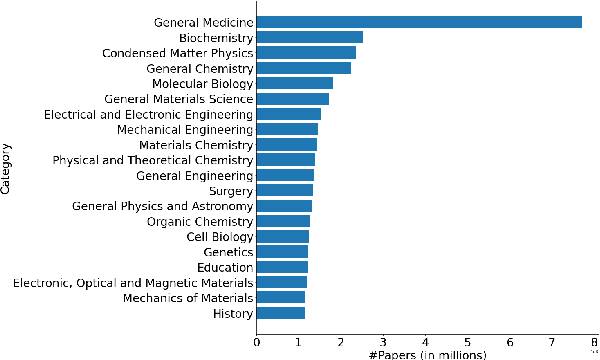
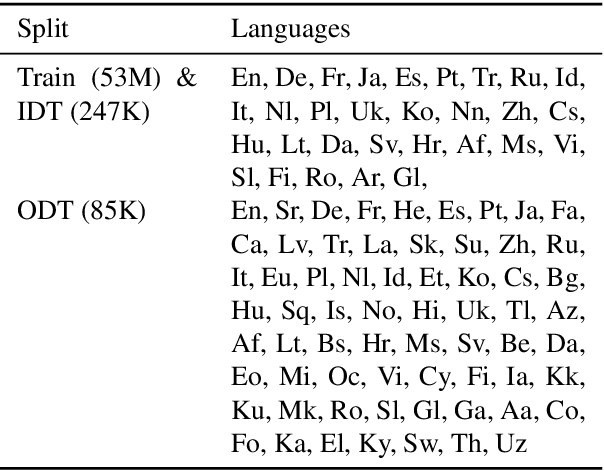
We develop and evaluate multilingual scientific documents similarity measurement models in this work. Such models can be used to find related works in different languages, which can help multilingual researchers find and explore papers more efficiently. We propose the first multilingual scientific documents dataset, Open-access Multilingual Scientific Documents (OpenMSD), which has 74M papers in 103 languages and 778M citation pairs. With OpenMSD, we pretrain science-specialized language models, and explore different strategies to derive "related" paper pairs to fine-tune the models, including using a mixture of citation, co-citation, and bibliographic-coupling pairs. To further improve the models' performance for non-English papers, we explore the use of generative language models to enrich the non-English papers with English summaries. This allows us to leverage the models' English capabilities to create better representations for non-English papers. Our best model significantly outperforms strong baselines by 7-16% (in mean average precision).
HYRR: Hybrid Infused Reranking for Passage Retrieval
Dec 20, 2022

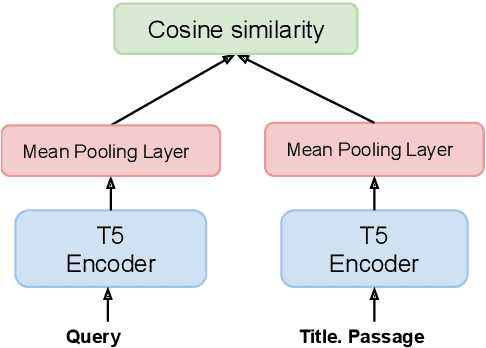

We present Hybrid Infused Reranking for Passages Retrieval (HYRR), a framework for training rerankers based on a hybrid of BM25 and neural retrieval models. Retrievers based on hybrid models have been shown to outperform both BM25 and neural models alone. Our approach exploits this improved performance when training a reranker, leading to a robust reranking model. The reranker, a cross-attention neural model, is shown to be robust to different first-stage retrieval systems, achieving better performance than rerankers simply trained upon the first-stage retrievers in the multi-stage systems. We present evaluations on a supervised passage retrieval task using MS MARCO and zero-shot retrieval tasks using BEIR. The empirical results show strong performance on both evaluations.
Handling Compounding in Mobile Keyboard Input
Jan 17, 2022This paper proposes a framework to improve the typing experience of mobile users in morphologically rich languages. Smartphone keyboards typically support features such as input decoding, corrections and predictions that all rely on language models. For latency reasons, these operations happen on device, so the models are of limited size and cannot easily cover all the words needed by users for their daily tasks, especially in morphologically rich languages. In particular, the compounding nature of Germanic languages makes their vocabulary virtually infinite. Similarly, heavily inflecting and agglutinative languages (e.g. Slavic, Turkic or Finno-Ugric languages) tend to have much larger vocabularies than morphologically simpler languages, such as English or Mandarin. We propose to model such languages with automatically selected subword units annotated with what we call binding types, allowing the decoder to know when to bind subword units into words. We show that this method brings around 20% word error rate reduction in a variety of compounding languages. This is more than twice the improvement we previously obtained with a more basic approach, also described in the paper.
Atomized Search Length: Beyond User Models
Jan 05, 2022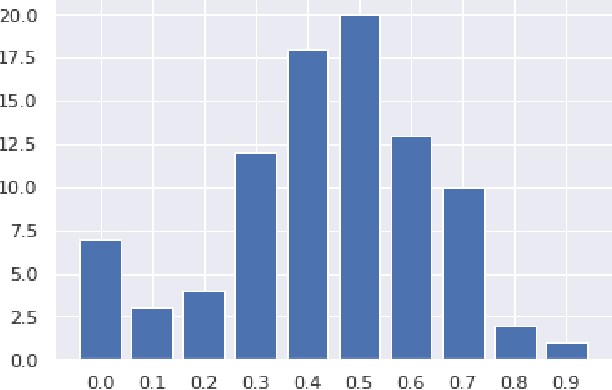
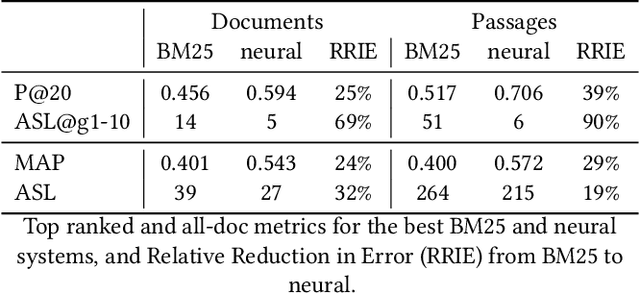
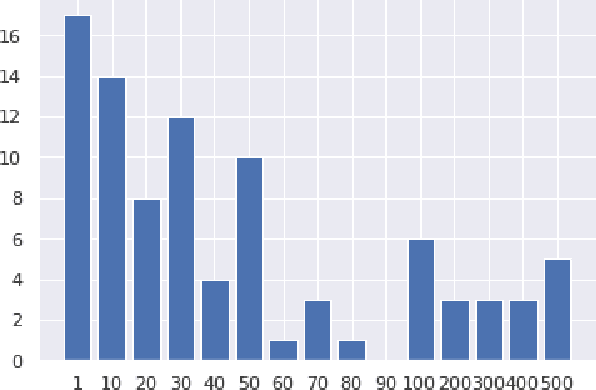
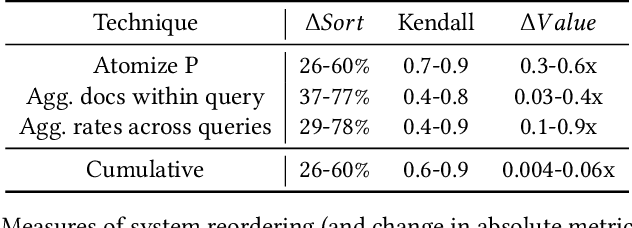
We argue that current IR metrics, modeled on optimizing user experience, measure too narrow a portion of the IR space. If IR systems are weak, these metrics undersample or completely filter out the deeper documents that need improvement. If IR systems are relatively strong, these metrics undersample deeper relevant documents that could underpin even stronger IR systems, ones that could present content from tens or hundreds of relevant documents in a user-digestible hierarchy or text summary. We reanalyze over 70 TREC tracks from the past 28 years, showing that roughly half undersample top ranked documents and nearly all undersample tail documents. We show that in the 2020 Deep Learning tracks, neural systems were actually near-optimal at top-ranked documents, compared to only modest gains over BM25 on tail documents. Our analysis is based on a simple new systems-oriented metric, 'atomized search length', which is capable of accurately and evenly measuring all relevant documents at any depth.
RRF102: Meeting the TREC-COVID Challenge with a 100+ Runs Ensemble
Oct 01, 2020
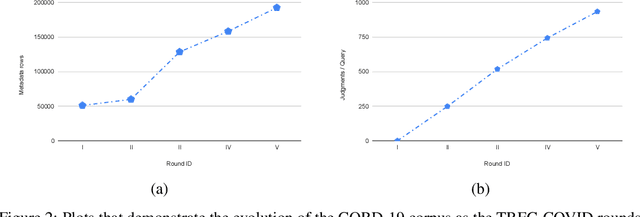
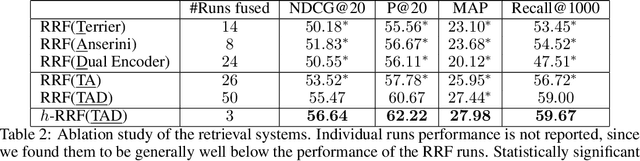
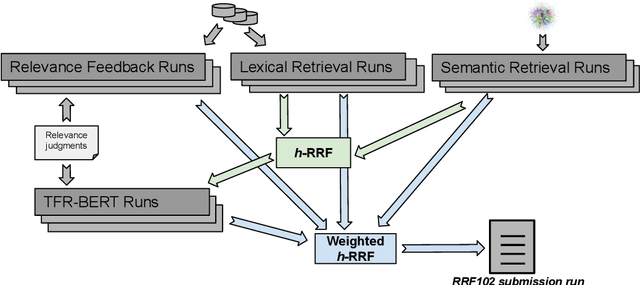
In this paper, we report the results of our participation in the TREC-COVID challenge. To meet the challenge of building a search engine for rapidly evolving biomedical collection, we propose a simple yet effective weighted hierarchical rank fusion approach, that ensembles together 102 runs from (a) lexical and semantic retrieval systems, (b) pre-trained and fine-tuned BERT rankers, and (c) relevance feedback runs. Our ablation studies demonstrate the contributions of each of these systems to the overall ensemble. The submitted ensemble runs achieved state-of-the-art performance in rounds 4 and 5 of the TREC-COVID challenge.
Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset
Jul 02, 2020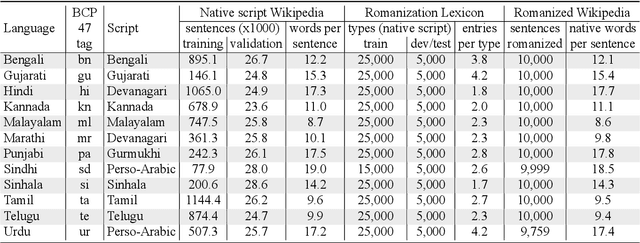
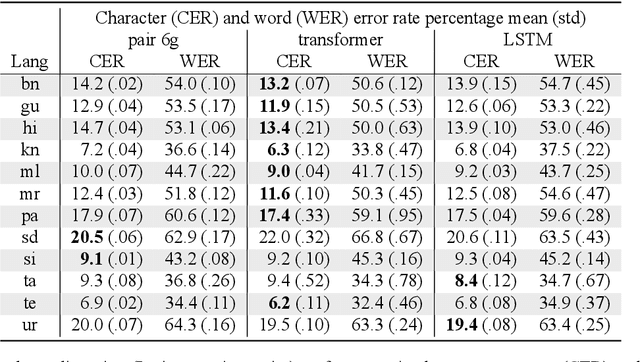

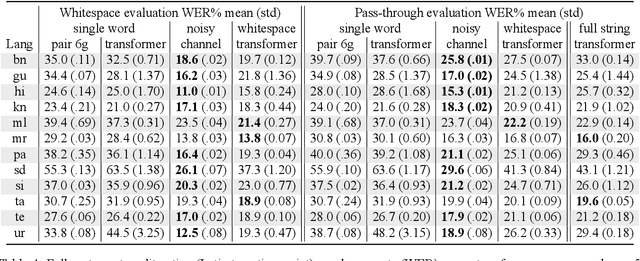
This paper describes the Dakshina dataset, a new resource consisting of text in both the Latin and native scripts for 12 South Asian languages. The dataset includes, for each language: 1) native script Wikipedia text; 2) a romanization lexicon; and 3) full sentence parallel data in both a native script of the language and the basic Latin alphabet. We document the methods used for preparation and selection of the Wikipedia text in each language; collection of attested romanizations for sampled lexicons; and manual romanization of held-out sentences from the native script collections. We additionally provide baseline results on several tasks made possible by the dataset, including single word transliteration, full sentence transliteration, and language modeling of native script and romanized text. Keywords: romanization, transliteration, South Asian languages
Zero-shot Neural Retrieval via Domain-targeted Synthetic Query Generation
Apr 29, 2020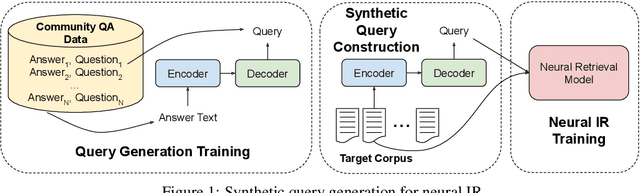

Deep neural scoring models have recently been shown to improve ranking quality on a number of benchmarks (Guo et al., 2016; Daiet al., 2018; MacAvaney et al., 2019; Yanget al., 2019a). However, these methods rely on underlying ad-hoc retrieval systems to generate candidates for scoring, which are rarely neural themselves (Zamani et al., 2018). Re-cent work has shown that the performance of ad-hoc neural retrieval systems can be competitive with a number of baselines (Zamani et al.,2018), potentially leading the way to full end-to-end neural retrieval. A major road-block to the adoption of ad-hoc retrieval models is that they require large supervised training sets to surpass classic term-based techniques, which can be developed from raw corpora. Previous work shows weakly supervised data can yield competitive results, e.g., click data (Dehghaniet al., 2017; Borisov et al., 2016). Unfortunately for many domains, even weakly supervised data can be scarce. In this paper, we pro-pose an approach to zero-shot learning (Xianet al., 2018) for ad-hoc retrieval models that relies on synthetic query generation. Crucially, the query generation system is trained on general domain data, but is applied to documents in the targeted domain. This allows us to create arbitrarily large, yet noisy, query-document relevance pairs that are domain targeted. On a number of benchmarks, we show that this is an effective strategy for building neural retrieval models for specialised domains.