 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMSD: Towards Multilingual Scientific Documents Similarity Measurement
Sep 19, 2023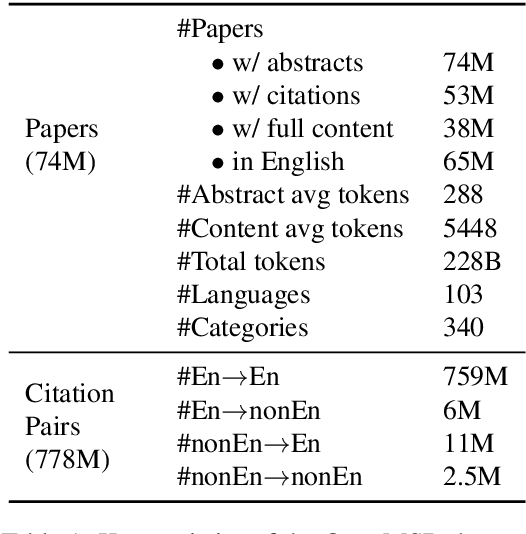
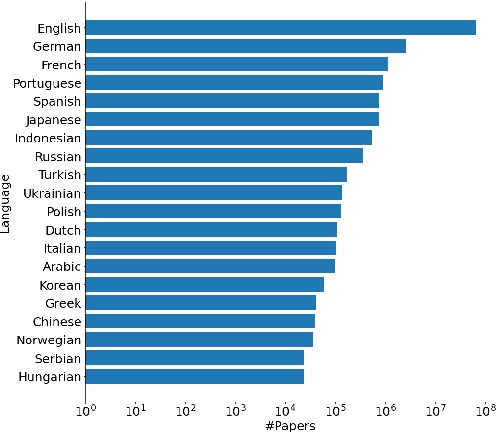
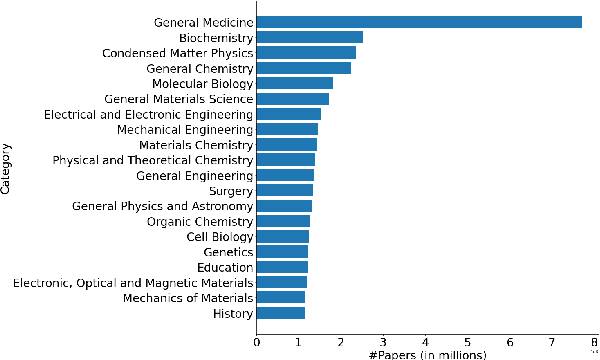
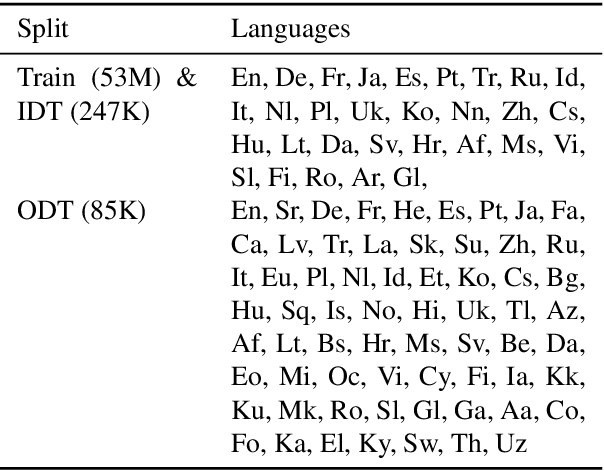
We develop and evaluate multilingual scientific documents similarity measurement models in this work. Such models can be used to find related works in different languages, which can help multilingual researchers find and explore papers more efficiently. We propose the first multilingual scientific documents dataset, Open-access Multilingual Scientific Documents (OpenMSD), which has 74M papers in 103 languages and 778M citation pairs. With OpenMSD, we pretrain science-specialized language models, and explore different strategies to derive "related" paper pairs to fine-tune the models, including using a mixture of citation, co-citation, and bibliographic-coupling pairs. To further improve the models' performance for non-English papers, we explore the use of generative language models to enrich the non-English papers with English summaries. This allows us to leverage the models' English capabilities to create better representations for non-English papers. Our best model significantly outperforms strong baselines by 7-16% (in mean average precision).
Retrieval Augmentation for T5 Re-ranker using External Sources
Oct 11, 2022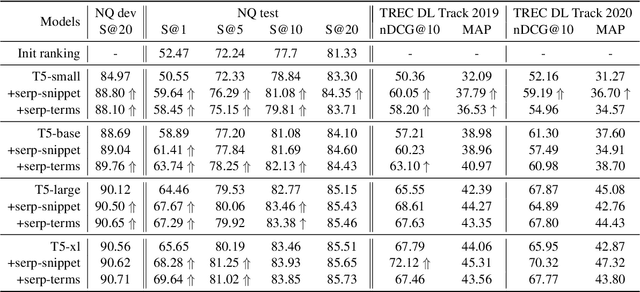
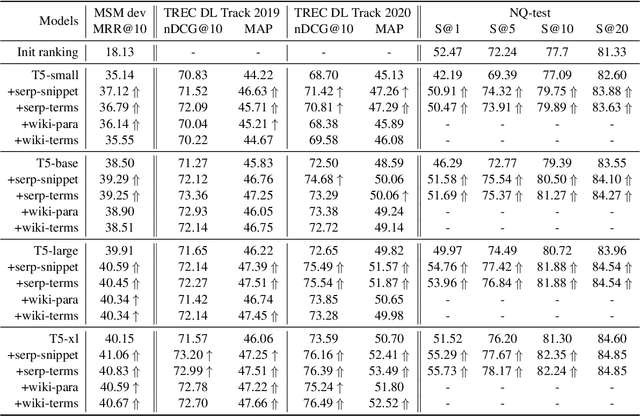
Retrieval augmentation has shown promising improvements in different tasks. However, whether such augmentation can assist a large language model based re-ranker remains unclear. We investigate how to augment T5-based re-rankers using high-quality information retrieved from two external corpora -- a commercial web search engine and Wikipedia. We empirically demonstrate how retrieval augmentation can substantially improve the effectiveness of T5-based re-rankers for both in-domain and zero-shot out-of-domain re-ranking tasks.
ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference
Apr 25, 2022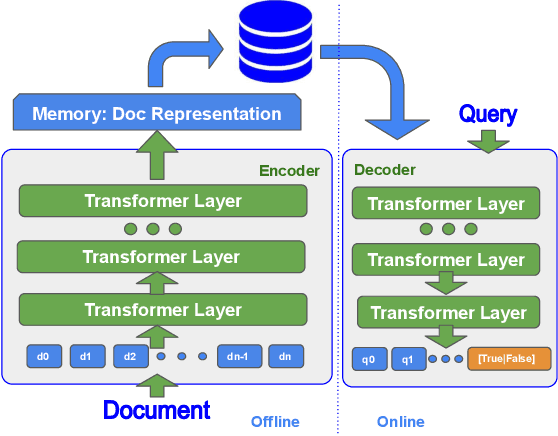
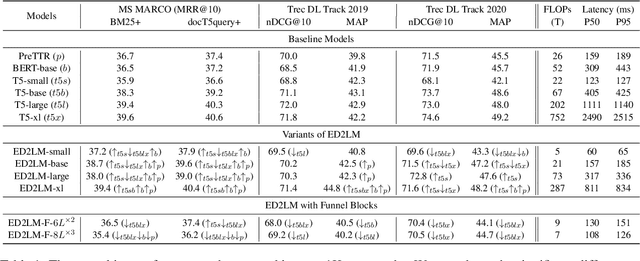
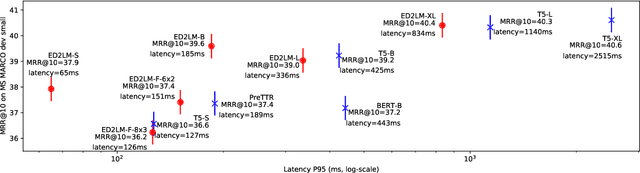
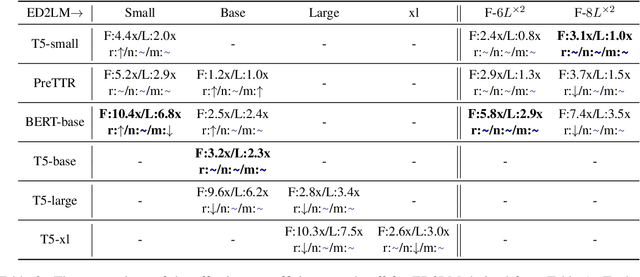
State-of-the-art neural models typically encode document-query pairs using cross-attention for re-ranking. To this end, models generally utilize an encoder-only (like BERT) paradigm or an encoder-decoder (like T5) approach. These paradigms, however, are not without flaws, i.e., running the model on all query-document pairs at inference-time incurs a significant computational cost. This paper proposes a new training and inference paradigm for re-ranking. We propose to finetune a pretrained encoder-decoder model using in the form of document to query generation. Subsequently, we show that this encoder-decoder architecture can be decomposed into a decoder-only language model during inference. This results in significant inference time speedups since the decoder-only architecture only needs to learn to interpret static encoder embeddings during inference. Our experiments show that this new paradigm achieves results that are comparable to the more expensive cross-attention ranking approaches while being up to 6.8X faster. We believe this work paves the way for more efficient neural rankers that leverage large pretrained models.