 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMSD: Towards Multilingual Scientific Documents Similarity Measurement
Sep 19, 2023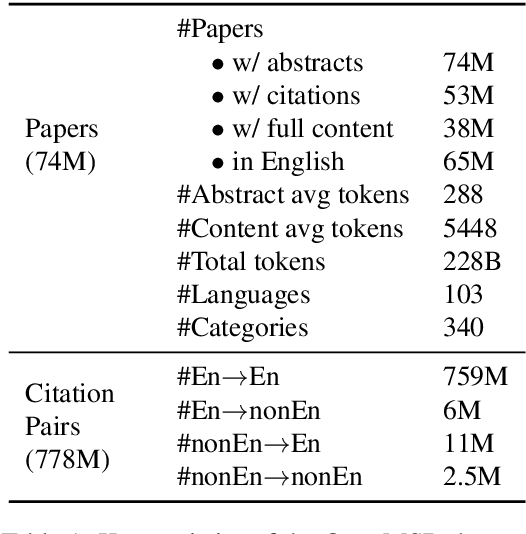
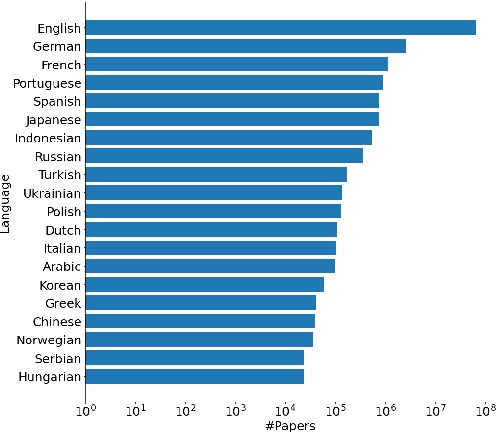
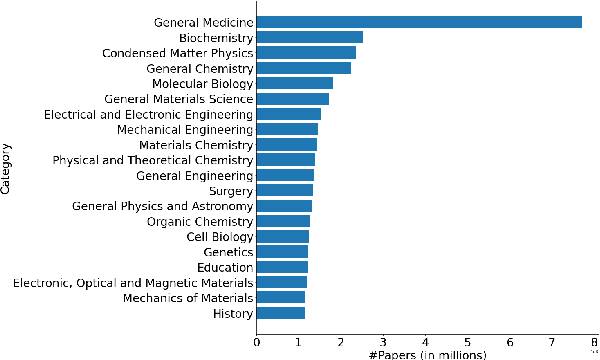
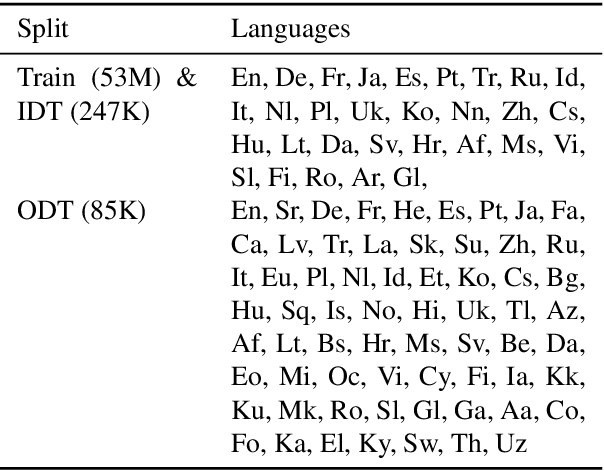
We develop and evaluate multilingual scientific documents similarity measurement models in this work. Such models can be used to find related works in different languages, which can help multilingual researchers find and explore papers more efficiently. We propose the first multilingual scientific documents dataset, Open-access Multilingual Scientific Documents (OpenMSD), which has 74M papers in 103 languages and 778M citation pairs. With OpenMSD, we pretrain science-specialized language models, and explore different strategies to derive "related" paper pairs to fine-tune the models, including using a mixture of citation, co-citation, and bibliographic-coupling pairs. To further improve the models' performance for non-English papers, we explore the use of generative language models to enrich the non-English papers with English summaries. This allows us to leverage the models' English capabilities to create better representations for non-English papers. Our best model significantly outperforms strong baselines by 7-16% (in mean average precision).
Zero-shot Neural Retrieval via Domain-targeted Synthetic Query Generation
Apr 29, 2020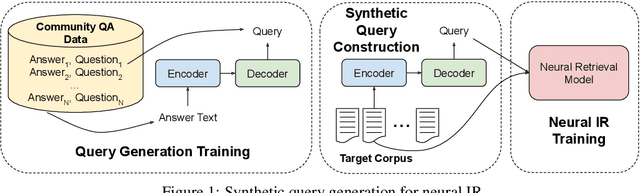

Deep neural scoring models have recently been shown to improve ranking quality on a number of benchmarks (Guo et al., 2016; Daiet al., 2018; MacAvaney et al., 2019; Yanget al., 2019a). However, these methods rely on underlying ad-hoc retrieval systems to generate candidates for scoring, which are rarely neural themselves (Zamani et al., 2018). Re-cent work has shown that the performance of ad-hoc neural retrieval systems can be competitive with a number of baselines (Zamani et al.,2018), potentially leading the way to full end-to-end neural retrieval. A major road-block to the adoption of ad-hoc retrieval models is that they require large supervised training sets to surpass classic term-based techniques, which can be developed from raw corpora. Previous work shows weakly supervised data can yield competitive results, e.g., click data (Dehghaniet al., 2017; Borisov et al., 2016). Unfortunately for many domains, even weakly supervised data can be scarce. In this paper, we pro-pose an approach to zero-shot learning (Xianet al., 2018) for ad-hoc retrieval models that relies on synthetic query generation. Crucially, the query generation system is trained on general domain data, but is applied to documents in the targeted domain. This allows us to create arbitrarily large, yet noisy, query-document relevance pairs that are domain targeted. On a number of benchmarks, we show that this is an effective strategy for building neural retrieval models for specialised domains.