 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Pre-training Indicators Reliably Predict Fine-tuning Outcomes of LLMs?
Apr 16, 2025While metrics available during pre-training, such as perplexity, correlate well with model performance at scaling-laws studies, their predictive capacities at a fixed model size remain unclear, hindering effective model selection and development. To address this gap, we formulate the task of selecting pre-training checkpoints to maximize downstream fine-tuning performance as a pairwise classification problem: predicting which of two LLMs, differing in their pre-training, will perform better after supervised fine-tuning (SFT). We construct a dataset using 50 1B parameter LLM variants with systematically varied pre-training configurations, e.g., objectives or data, and evaluate them on diverse downstream tasks after SFT. We first conduct a study and demonstrate that the conventional perplexity is a misleading indicator. As such, we introduce novel unsupervised and supervised proxy metrics derived from pre-training that successfully reduce the relative performance prediction error rate by over 50%. Despite the inherent complexity of this task, we demonstrate the practical utility of our proposed proxies in specific scenarios, paving the way for more efficient design of pre-training schemes optimized for various downstream tasks.
A Watermark for Black-Box Language Models
Oct 02, 2024



Watermarking has recently emerged as an effective strategy for detecting the outputs of large language models (LLMs). Most existing schemes require \emph{white-box} access to the model's next-token probability distribution, which is typically not accessible to downstream users of an LLM API. In this work, we propose a principled watermarking scheme that requires only the ability to sample sequences from the LLM (i.e. \emph{black-box} access), boasts a \emph{distortion-free} property, and can be chained or nested using multiple secret keys. We provide performance guarantees, demonstrate how it can be leveraged when white-box access is available, and show when it can outperform existing white-box schemes via comprehensive experiments.
Impact of Preference Noise on the Alignment Performance of Generative Language Models
Apr 15, 2024



A key requirement in developing Generative Language Models (GLMs) is to have their values aligned with human values. Preference-based alignment is a widely used paradigm for this purpose, in which preferences over generation pairs are first elicited from human annotators or AI systems, and then fed into some alignment techniques, e.g., Direct Preference Optimization. However, a substantial percent (20 - 40%) of the preference pairs used in GLM alignment are noisy, and it remains unclear how the noise affects the alignment performance and how to mitigate its negative impact. In this paper, we propose a framework to inject desirable amounts and types of noise to the preferences, and systematically study the impact of preference noise on the alignment performance in two tasks (summarization and dialogue generation). We find that the alignment performance can be highly sensitive to the noise rates in the preference data: e.g., a 10 percentage points (pp) increase of the noise rate can lead to 30 pp drop in the alignment performance (in win rate). To mitigate the impact of noise, confidence-based data filtering shows significant benefit when certain types of noise are present. We hope our work can help the community better understand and mitigate the impact of preference noise in GLM alignment.
Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data
Apr 08, 2024Reinforcement Learning from Human Feedback (RLHF) is a popular method for aligning Language Models (LM) with human values and preferences. RLHF requires a large number of preference pairs as training data, which are often used in both the Supervised Fine-Tuning and Reward Model training, and therefore publicly available datasets are commonly used. In this work, we study to what extent a malicious actor can manipulate the LMs generations by poisoning the preferences, i.e., injecting poisonous preference pairs into these datasets and the RLHF training process. We propose strategies to build poisonous preference pairs and test their performance by poisoning two widely used preference datasets. Our results show that preference poisoning is highly effective: by injecting a small amount of poisonous data (1-5% of the original dataset), we can effectively manipulate the LM to generate a target entity in a target sentiment (positive or negative). The findings from our experiments also shed light on strategies to defend against the preference poisoning attack.
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023



Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
PaRaDe: Passage Ranking using Demonstrations with Large Language Models
Oct 22, 2023



Recent studies show that large language models (LLMs) can be instructed to effectively perform zero-shot passage re-ranking, in which the results of a first stage retrieval method, such as BM25, are rated and reordered to improve relevance. In this work, we improve LLM-based re-ranking by algorithmically selecting few-shot demonstrations to include in the prompt. Our analysis investigates the conditions where demonstrations are most helpful, and shows that adding even one demonstration is significantly beneficial. We propose a novel demonstration selection strategy based on difficulty rather than the commonly used semantic similarity. Furthermore, we find that demonstrations helpful for ranking are also effective at question generation. We hope our work will spur more principled research into question generation and passage ranking.
OpenMSD: Towards Multilingual Scientific Documents Similarity Measurement
Sep 19, 2023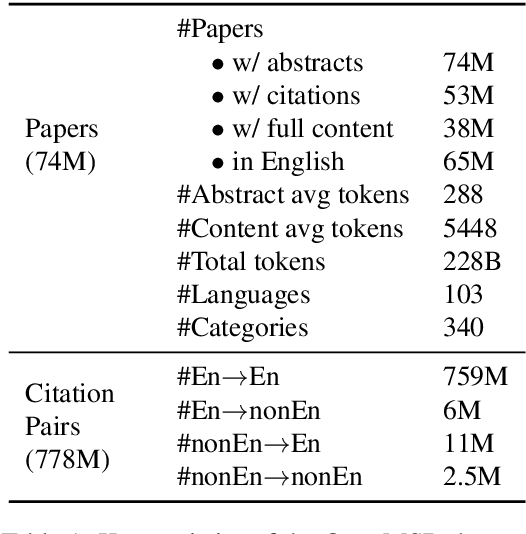
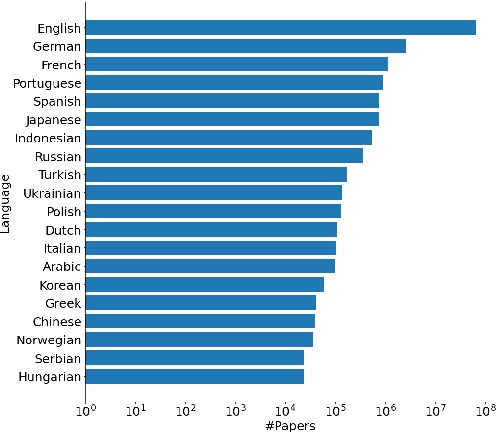
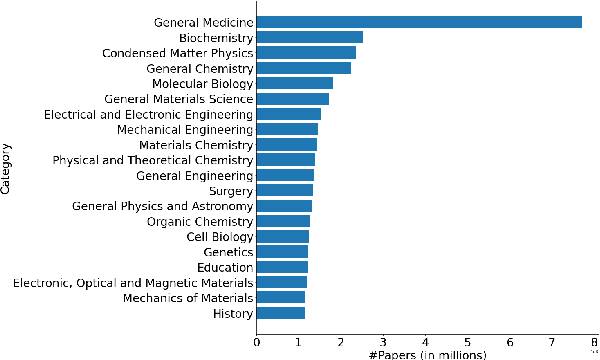
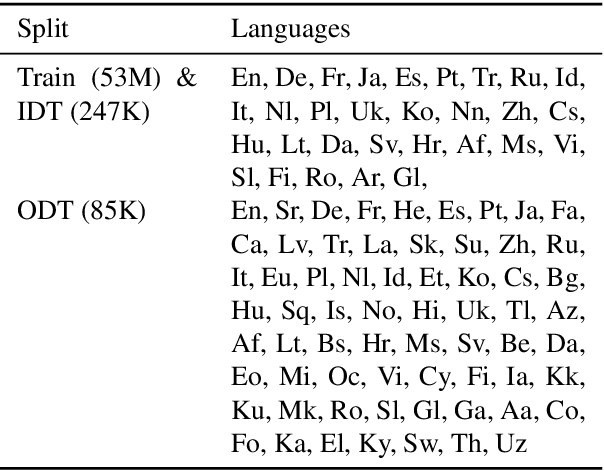
We develop and evaluate multilingual scientific documents similarity measurement models in this work. Such models can be used to find related works in different languages, which can help multilingual researchers find and explore papers more efficiently. We propose the first multilingual scientific documents dataset, Open-access Multilingual Scientific Documents (OpenMSD), which has 74M papers in 103 languages and 778M citation pairs. With OpenMSD, we pretrain science-specialized language models, and explore different strategies to derive "related" paper pairs to fine-tune the models, including using a mixture of citation, co-citation, and bibliographic-coupling pairs. To further improve the models' performance for non-English papers, we explore the use of generative language models to enrich the non-English papers with English summaries. This allows us to leverage the models' English capabilities to create better representations for non-English papers. Our best model significantly outperforms strong baselines by 7-16% (in mean average precision).
LayerNAS: Neural Architecture Search in Polynomial Complexity
Apr 23, 2023Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial. For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$. LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to $ O(H \cdot |\mathbb{S}| \cdot L) $, where $H$ is a constant set in LayerNAS. Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.